 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInconsistencies In Consistency Models: Better ODE Solving Does Not Imply Better Samples
Nov 13, 2024



Although diffusion models can generate remarkably high-quality samples, they are intrinsically bottlenecked by their expensive iterative sampling procedure. Consistency models (CMs) have recently emerged as a promising diffusion model distillation method, reducing the cost of sampling by generating high-fidelity samples in just a few iterations. Consistency model distillation aims to solve the probability flow ordinary differential equation (ODE) defined by an existing diffusion model. CMs are not directly trained to minimize error against an ODE solver, rather they use a more computationally tractable objective. As a way to study how effectively CMs solve the probability flow ODE, and the effect that any induced error has on the quality of generated samples, we introduce Direct CMs, which \textit{directly} minimize this error. Intriguingly, we find that Direct CMs reduce the ODE solving error compared to CMs but also result in significantly worse sample quality, calling into question why exactly CMs work well in the first place. Full code is available at: https://github.com/layer6ai-labs/direct-cms.
MSc-SQL: Multi-Sample Critiquing Small Language Models For Text-To-SQL Translation
Oct 16, 2024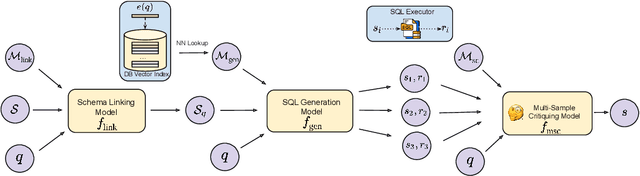
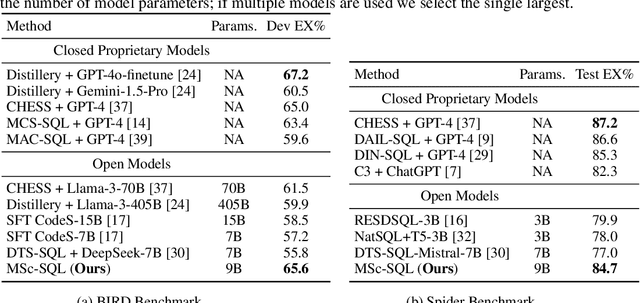


Text-to-SQL generation enables non-experts to interact with databases via natural language. Recent advances rely on large closed-source models like GPT-4 that present challenges in accessibility, privacy, and latency. To address these issues, we focus on developing small, efficient, and open-source text-to-SQL models. We demonstrate the benefits of sampling multiple candidate SQL generations and propose our method, MSc-SQL, to critique them using associated metadata. Our sample critiquing model evaluates multiple outputs simultaneously, achieving state-of-the-art performance compared to other open-source models while remaining competitive with larger models at a much lower cost. Full code can be found at github.com/layer6ai-labs/msc-sql.
Data-Efficient Multimodal Fusion on a Single GPU
Jan 02, 2024



The goal of multimodal alignment is to learn a single latent space that is shared between multimodal inputs. The most powerful models in this space have been trained using massive datasets of paired inputs and large-scale computational resources, making them prohibitively expensive to train in many practical scenarios. We surmise that existing unimodal encoders pre-trained on large amounts of unimodal data should provide an effective bootstrap to create multimodal models from unimodal ones at much lower costs. We therefore propose FuseMix, a multimodal augmentation scheme that operates on the latent spaces of arbitrary pre-trained unimodal encoders. Using FuseMix for multimodal alignment, we achieve competitive performance -- and in certain cases outperform state-of-the art methods -- in both image-text and audio-text retrieval, with orders of magnitude less compute and data: for example, we outperform CLIP on the Flickr30K text-to-image retrieval task with $\sim \! 600\times$ fewer GPU days and $\sim \! 80\times$ fewer image-text pairs. Additionally, we show how our method can be applied to convert pre-trained text-to-image generative models into audio-to-image ones. Code is available at: https://github.com/layer6ai-labs/fusemix.
TR0N: Translator Networks for 0-Shot Plug-and-Play Conditional Generation
Apr 26, 2023



We propose TR0N, a highly general framework to turn pre-trained unconditional generative models, such as GANs and VAEs, into conditional models. The conditioning can be highly arbitrary, and requires only a pre-trained auxiliary model. For example, we show how to turn unconditional models into class-conditional ones with the help of a classifier, and also into text-to-image models by leveraging CLIP. TR0N learns a lightweight stochastic mapping which "translates" between the space of conditions and the latent space of the generative model, in such a way that the generated latent corresponds to a data sample satisfying the desired condition. The translated latent samples are then further improved upon through Langevin dynamics, enabling us to obtain higher-quality data samples. TR0N requires no training data nor fine-tuning, yet can achieve a zero-shot FID of 10.9 on MS-COCO, outperforming competing alternatives not only on this metric, but also in sampling speed -- all while retaining a much higher level of generality. Our code is available at https://github.com/layer6ai-labs/tr0n.
X-Pool: Cross-Modal Language-Video Attention for Text-Video Retrieval
Mar 28, 2022
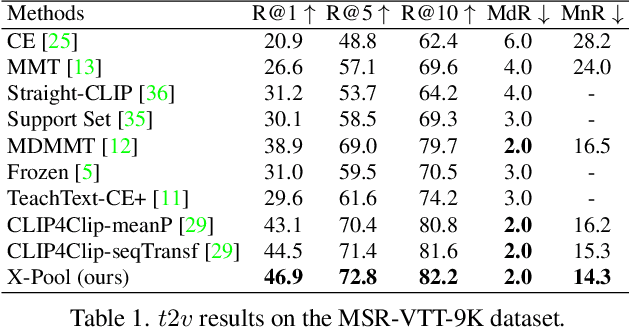
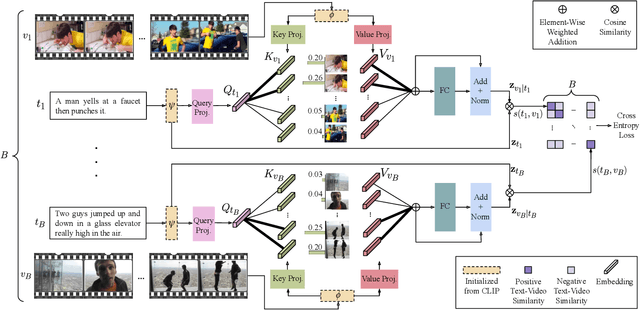
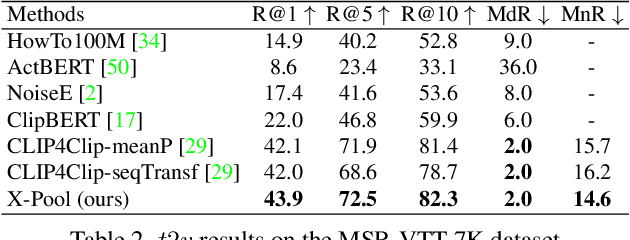
In text-video retrieval, the objective is to learn a cross-modal similarity function between a text and a video that ranks relevant text-video pairs higher than irrelevant pairs. However, videos inherently express a much wider gamut of information than texts. Instead, texts often capture sub-regions of entire videos and are most semantically similar to certain frames within videos. Therefore, for a given text, a retrieval model should focus on the text's most semantically similar video sub-regions to make a more relevant comparison. Yet, most existing works aggregate entire videos without directly considering text. Common text-agnostic aggregations schemes include mean-pooling or self-attention over the frames, but these are likely to encode misleading visual information not described in the given text. To address this, we propose a cross-modal attention model called X-Pool that reasons between a text and the frames of a video. Our core mechanism is a scaled dot product attention for a text to attend to its most semantically similar frames. We then generate an aggregated video representation conditioned on the text's attention weights over the frames. We evaluate our method on three benchmark datasets of MSR-VTT, MSVD and LSMDC, achieving new state-of-the-art results by up to 12% in relative improvement in Recall@1. Our findings thereby highlight the importance of joint text-video reasoning to extract important visual cues according to text. Full code and demo can be found at: https://layer6ai-labs.github.io/xpool/
Weakly Supervised Action Selection Learning in Video
May 06, 2021
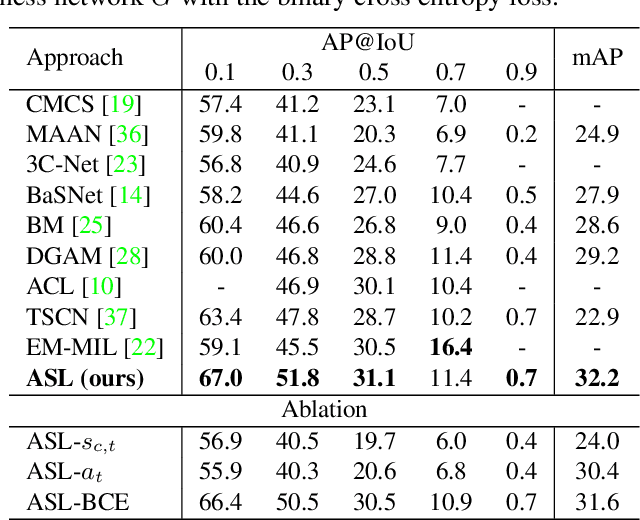
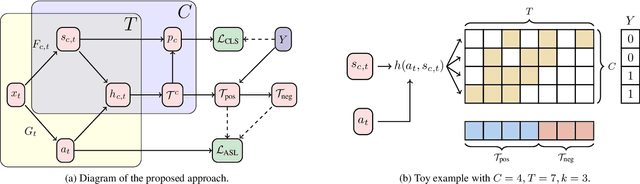
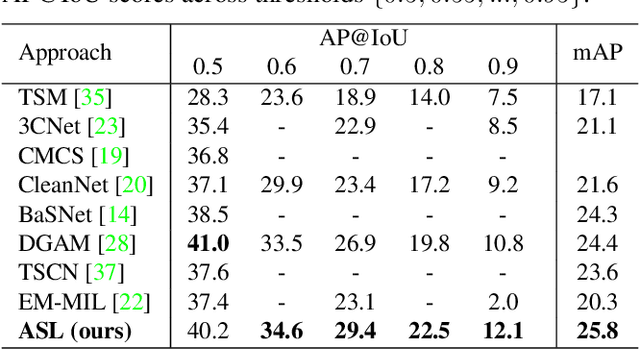
Localizing actions in video is a core task in computer vision. The weakly supervised temporal localization problem investigates whether this task can be adequately solved with only video-level labels, significantly reducing the amount of expensive and error-prone annotation that is required. A common approach is to train a frame-level classifier where frames with the highest class probability are selected to make a video-level prediction. Frame level activations are then used for localization. However, the absence of frame-level annotations cause the classifier to impart class bias on every frame. To address this, we propose the Action Selection Learning (ASL) approach to capture the general concept of action, a property we refer to as "actionness". Under ASL, the model is trained with a novel class-agnostic task to predict which frames will be selected by the classifier. Empirically, we show that ASL outperforms leading baselines on two popular benchmarks THUMOS-14 and ActivityNet-1.2, with 10.3% and 5.7% relative improvement respectively. We further analyze the properties of ASL and demonstrate the importance of actionness. Full code for this work is available here: https://github.com/layer6ai-labs/ASL.
Cross-Class Relevance Learning for Temporal Concept Localization
Nov 19, 2019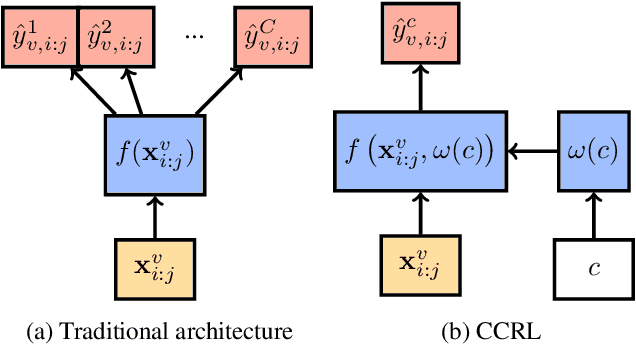
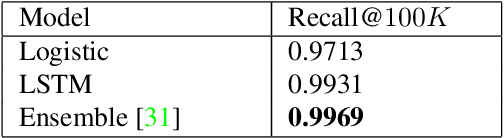
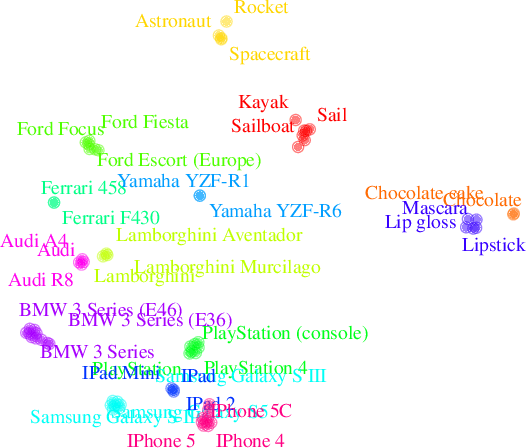
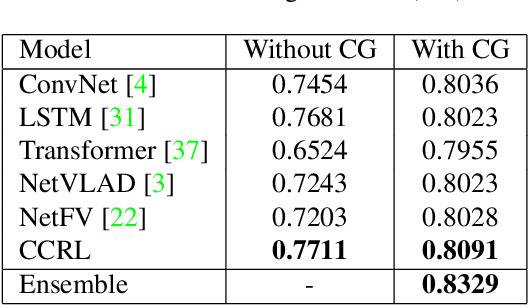
We present a novel Cross-Class Relevance Learning approach for the task of temporal concept localization. Most localization architectures rely on feature extraction layers followed by a classification layer which outputs class probabilities for each segment. However, in many real-world applications classes can exhibit complex relationships that are difficult to model with this architecture. In contrast, we propose to incorporate target class and class-related features as input, and learn a pairwise binary model to predict general segment to class relevance. This facilitates learning of shared information between classes, and allows for arbitrary class-specific feature engineering. We apply this approach to the 3rd YouTube-8M Video Understanding Challenge together with other leading models, and achieve first place out of over 280 teams. In this paper we describe our approach and show some empirical results.
Semi-Supervised Exploration in Image Retrieval
Jun 12, 2019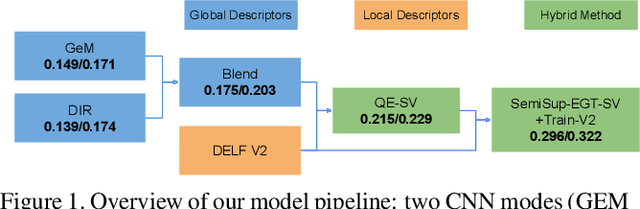
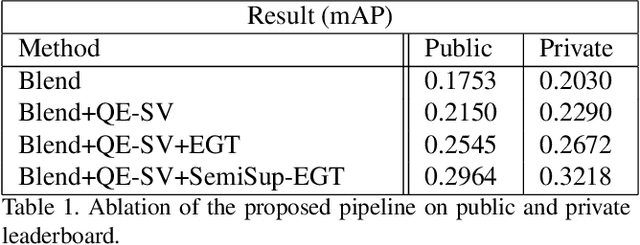
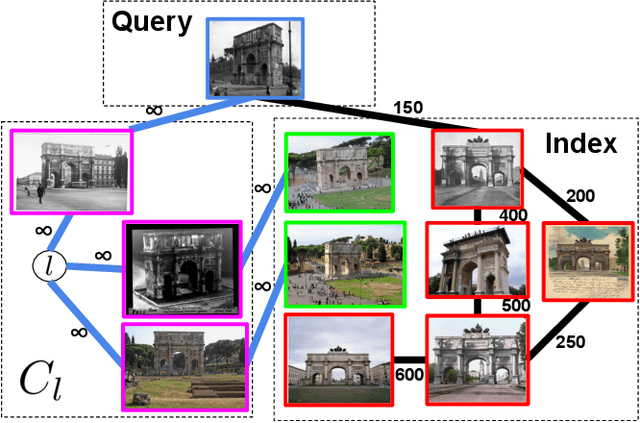
We present our solution to Landmark Image Retrieval Challenge 2019. This challenge was based on the large Google Landmarks Dataset V2[9]. The goal was to retrieve all database images containing the same landmark for every provided query image. Our solution is a combination of global and local models to form an initial KNN graph. We then use a novel extension of the recently proposed graph traversal method EGT [1] referred to as semi-supervised EGT to refine the graph and retrieve better candidates.
Text-to-Image-to-Text Translation using Cycle Consistent Adversarial Networks
Aug 14, 2018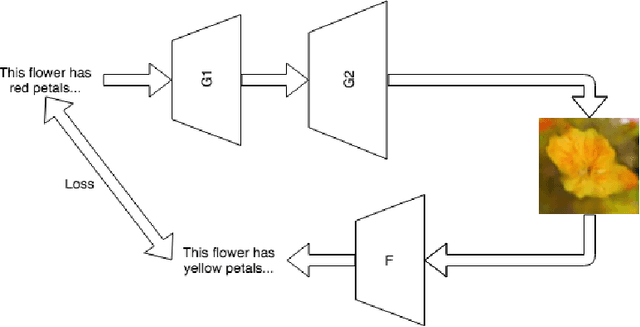
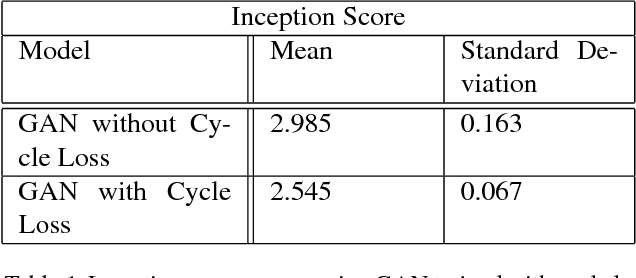
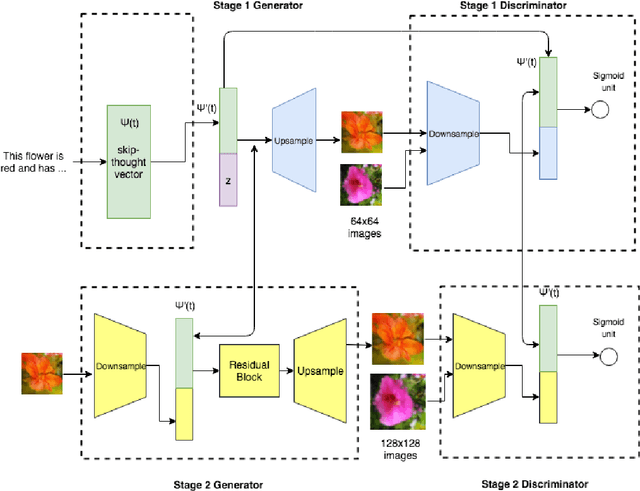
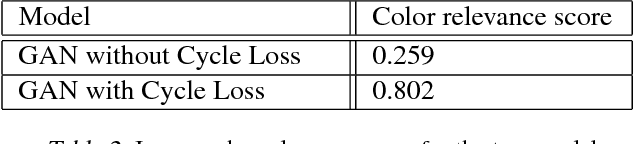
Text-to-Image translation has been an active area of research in the recent past. The ability for a network to learn the meaning of a sentence and generate an accurate image that depicts the sentence shows ability of the model to think more like humans. Popular methods on text to image translation make use of Generative Adversarial Networks (GANs) to generate high quality images based on text input, but the generated images don't always reflect the meaning of the sentence given to the model as input. We address this issue by using a captioning network to caption on generated images and exploit the distance between ground truth captions and generated captions to improve the network further. We show extensive comparisons between our method and existing methods.