 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Nonparametrics for Offline Skill Discovery
Feb 16, 2022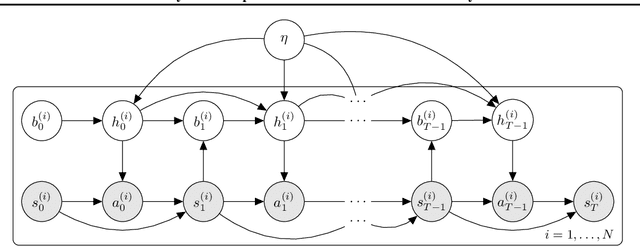
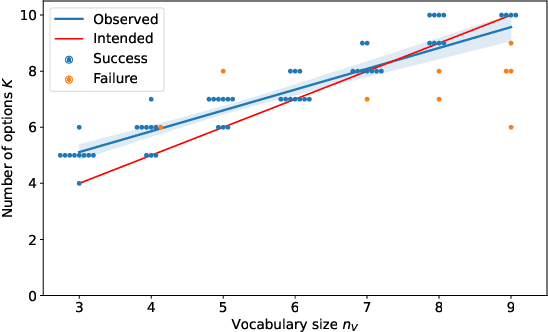
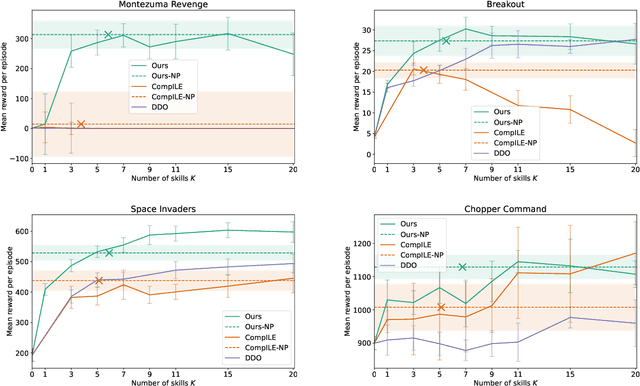
Skills or low-level policies in reinforcement learning are temporally extended actions that can speed up learning and enable complex behaviours. Recent work in offline reinforcement learning and imitation learning has proposed several techniques for skill discovery from a set of expert trajectories. While these methods are promising, the number K of skills to discover is always a fixed hyperparameter, which requires either prior knowledge about the environment or an additional parameter search to tune it. We first propose a method for offline learning of options (a particular skill framework) exploiting advances in variational inference and continuous relaxations. We then highlight an unexplored connection between Bayesian nonparametrics and offline skill discovery, and show how to obtain a nonparametric version of our model. This version is tractable thanks to a carefully structured approximate posterior with a dynamically-changing number of options, removing the need to specify K. We also show how our nonparametric extension can be applied in other skill frameworks, and empirically demonstrate that our method can outperform state-of-the-art offline skill learning algorithms across a variety of environments. Our code is available at https://github.com/layer6ai-labs/BNPO .
C-Learning: Horizon-Aware Cumulative Accessibility Estimation
Dec 14, 2020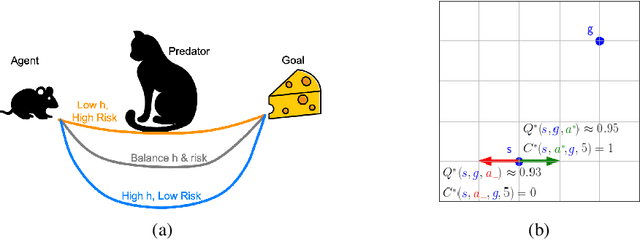
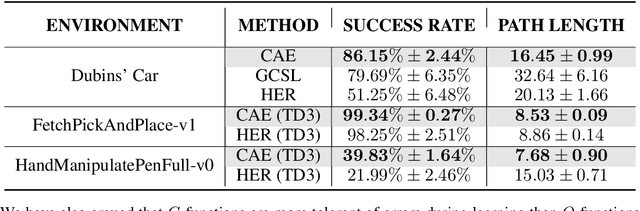
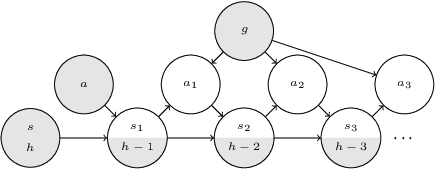

Multi-goal reaching is an important problem in reinforcement learning needed to achieve algorithmic generalization. Despite recent advances in this field, current algorithms suffer from three major challenges: high sample complexity, learning only a single way of reaching the goals, and difficulties in solving complex motion planning tasks. In order to address these limitations, we introduce the concept of cumulative accessibility functions, which measure the reachability of a goal from a given state within a specified horizon. We show that these functions obey a recurrence relation, which enables learning from offline interactions. We also prove that optimal cumulative accessibility functions are monotonic in the planning horizon. Additionally, our method can trade off speed and reliability in goal-reaching by suggesting multiple paths to a single goal depending on the provided horizon. We evaluate our approach on a set of multi-goal discrete and continuous control tasks. We show that our method outperforms state-of-the-art goal-reaching algorithms in success rate, sample complexity, and path optimality. Additional visualizations can be found at https://sites.google.com/view/learning-cae/.
Adaptive Transformers in RL
Apr 08, 2020
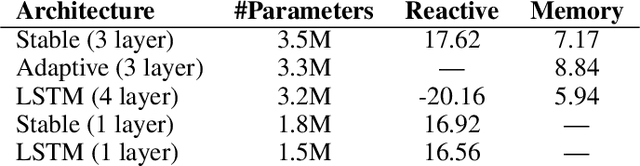
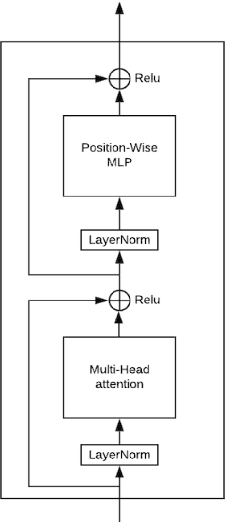
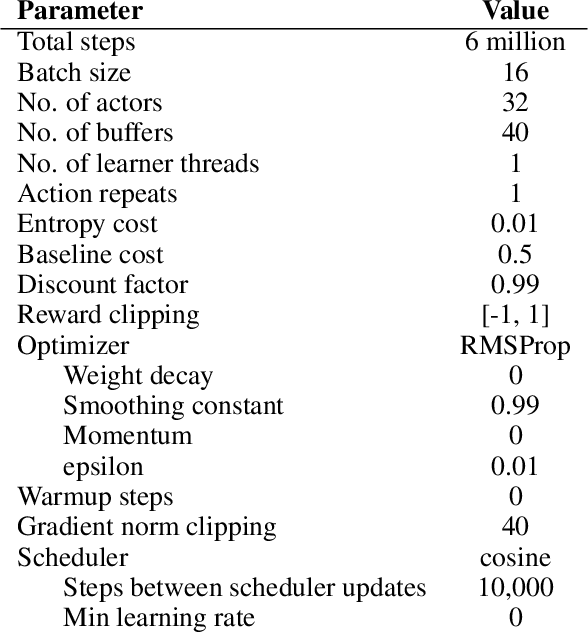
Recent developments in Transformers have opened new interesting areas of research in partially observable reinforcement learning tasks. Results from late 2019 showed that Transformers are able to outperform LSTMs on both memory intense and reactive tasks. In this work we first partially replicate the results shown in Stabilizing Transformers in RL on both reactive and memory based environments. We then show performance improvement coupled with reduced computation when adding adaptive attention span to this Stable Transformer on a challenging DMLab30 environment. The code for all our experiments and models is available at https://github.com/jerrodparker20/adaptive-transformers-in-rl.