 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtended Feature Space-Based Automatic Melanoma Detection System
Sep 10, 2022
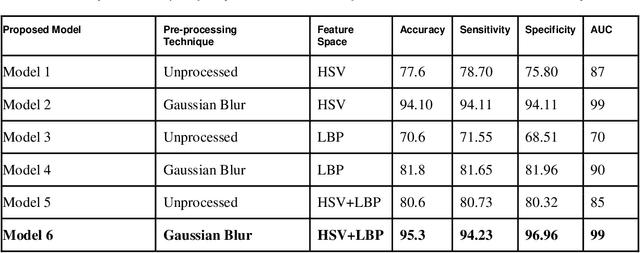

Melanoma is the deadliest form of skin cancer. Uncontrollable growth of melanocytes leads to melanoma. Melanoma has been growing wildly in the last few decades. In recent years, the detection of melanoma using image processing techniques has become a dominant research field. The Automatic Melanoma Detection System (AMDS) helps to detect melanoma based on image processing techniques by accepting infected skin area images as input. A single lesion image is a source of multiple features. Therefore, It is crucial to select the appropriate features from the image of the lesion in order to increase the accuracy of AMDS. For melanoma detection, all extracted features are not important. Some of the extracted features are complex and require more computation tasks, which impacts the classification accuracy of AMDS. The feature extraction phase of AMDS exhibits more variability, therefore it is important to study the behaviour of AMDS using individual and extended feature extraction approaches. A novel algorithm ExtFvAMDS is proposed for the calculation of Extended Feature Vector Space. The six models proposed in the comparative study revealed that the HSV feature vector space for automatic detection of melanoma using Ensemble Bagged Tree classifier on Med-Node Dataset provided 99% AUC, 95.30% accuracy, 94.23% sensitivity, and 96.96% specificity.
GDC- Generalized Distribution Calibration for Few-Shot Learning
Apr 11, 2022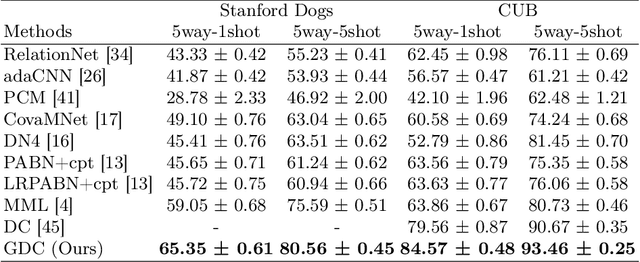
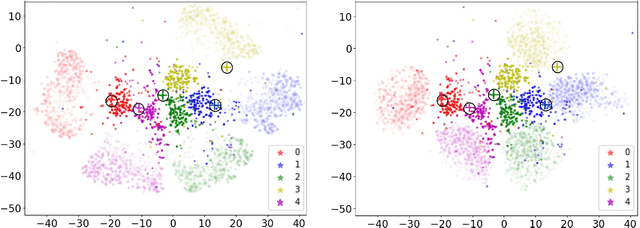
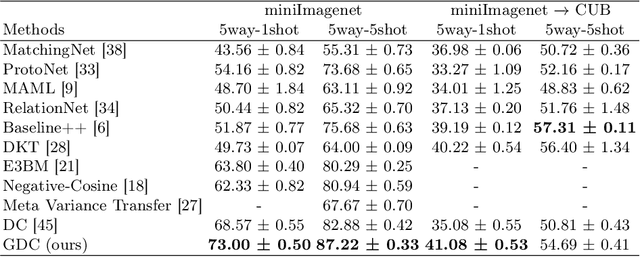
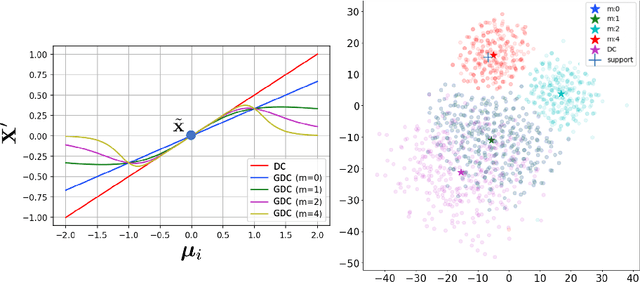
Few shot learning is an important problem in machine learning as large labelled datasets take considerable time and effort to assemble. Most few-shot learning algorithms suffer from one of two limitations- they either require the design of sophisticated models and loss functions, thus hampering interpretability; or employ statistical techniques but make assumptions that may not hold across different datasets or features. Developing on recent work in extrapolating distributions of small sample classes from the most similar larger classes, we propose a Generalized sampling method that learns to estimate few-shot distributions for classification as weighted random variables of all large classes. We use a form of covariance shrinkage to provide robustness against singular covariances due to overparameterized features or small datasets. We show that our sampled points are close to few-shot classes even in cases when there are no similar large classes in the training set. Our method works with arbitrary off-the-shelf feature extractors and outperforms existing state-of-the-art on miniImagenet, CUB and Stanford Dogs datasets by 3% to 5% on 5way-1shot and 5way-5shot tasks and by 1% in challenging cross domain tasks.
Learning Robust Latent Representations for Controllable Speech Synthesis
May 10, 2021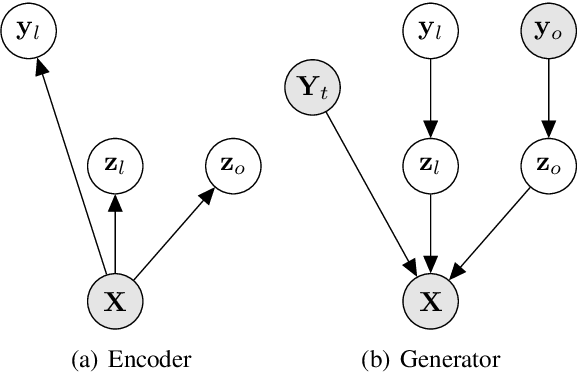
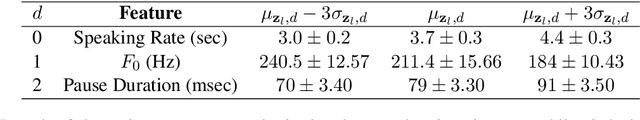
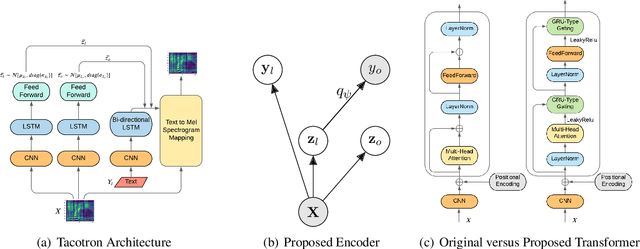

State-of-the-art Variational Auto-Encoders (VAEs) for learning disentangled latent representations give impressive results in discovering features like pitch, pause duration, and accent in speech data, leading to highly controllable text-to-speech (TTS) synthesis. However, these LSTM-based VAEs fail to learn latent clusters of speaker attributes when trained on either limited or noisy datasets. Further, different latent variables start encoding the same features, limiting the control and expressiveness during speech synthesis. To resolve these issues, we propose RTI-VAE (Reordered Transformer with Information reduction VAE) where we minimize the mutual information between different latent variables and devise a modified Transformer architecture with layer reordering to learn controllable latent representations in speech data. We show that RTI-VAE reduces the cluster overlap of speaker attributes by at least 30\% over LSTM-VAE and by at least 7\% over vanilla Transformer-VAE.
Adaptive Attention Span in Computer Vision
Apr 18, 2020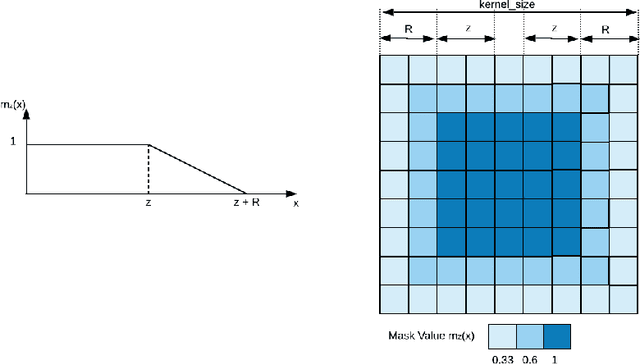

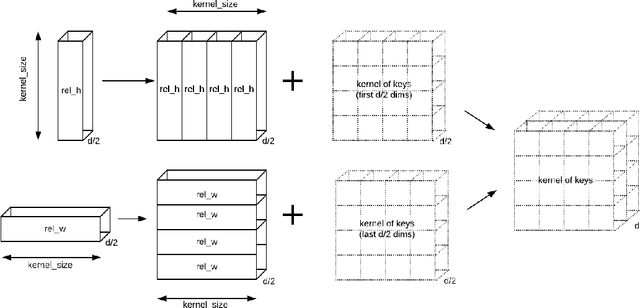
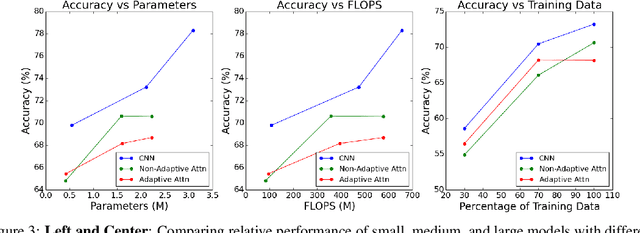
Recent developments in Transformers for language modeling have opened new areas of research in computer vision. Results from late 2019 showed vast performance increases in both object detection and recognition when convolutions are replaced by local self-attention kernels. Models using local self-attention kernels were also shown to have less parameters and FLOPS compared to equivalent architectures that only use convolutions. In this work we propose a novel method for learning the local self-attention kernel size. We then compare its performance to fixed-size local attention and convolution kernels. The code for all our experiments and models is available at https://github.com/JoeRoussy/adaptive-attention-in-cv
Adaptive Transformers in RL
Apr 08, 2020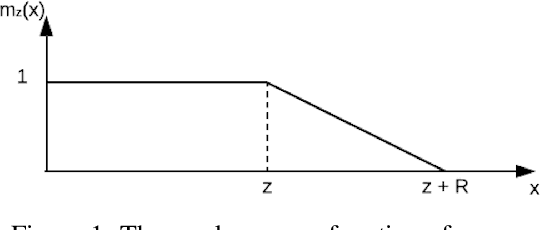
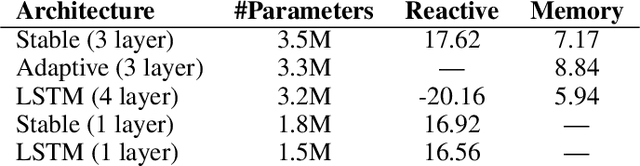
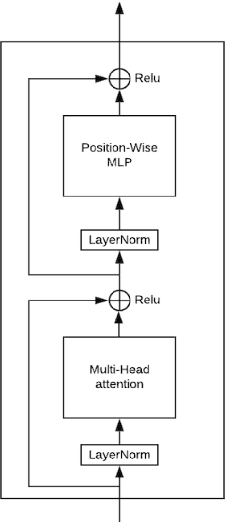
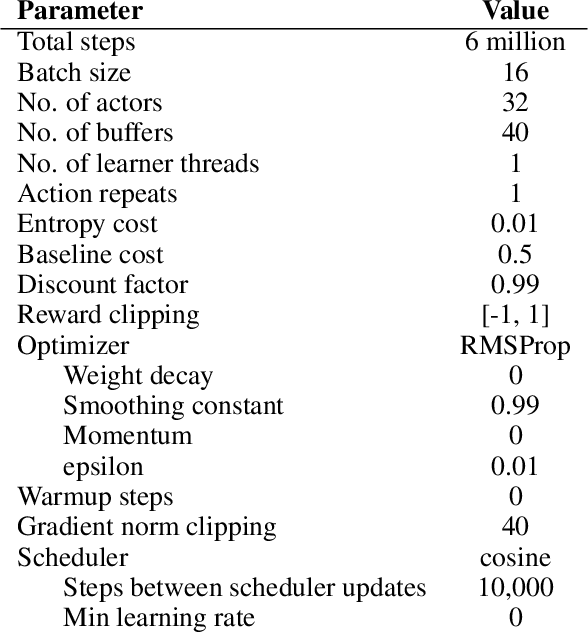
Recent developments in Transformers have opened new interesting areas of research in partially observable reinforcement learning tasks. Results from late 2019 showed that Transformers are able to outperform LSTMs on both memory intense and reactive tasks. In this work we first partially replicate the results shown in Stabilizing Transformers in RL on both reactive and memory based environments. We then show performance improvement coupled with reduced computation when adding adaptive attention span to this Stable Transformer on a challenging DMLab30 environment. The code for all our experiments and models is available at https://github.com/jerrodparker20/adaptive-transformers-in-rl.
Soft Computing Framework for Routing in Wireless Mesh Networks: An Integrated Cost Function Approach
Jul 11, 2013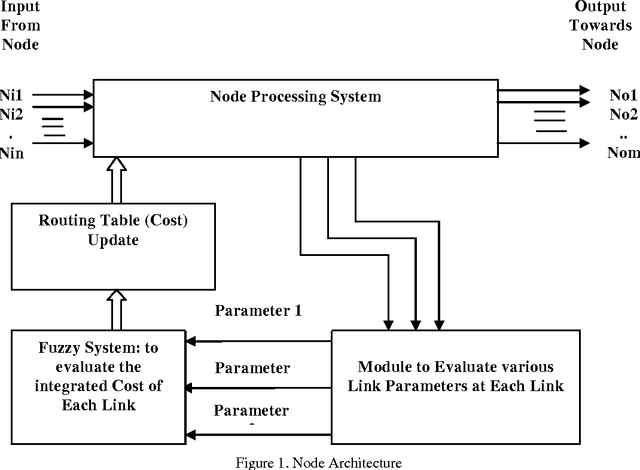
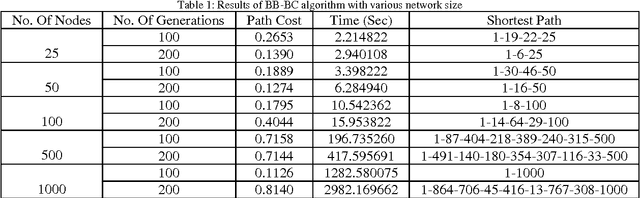
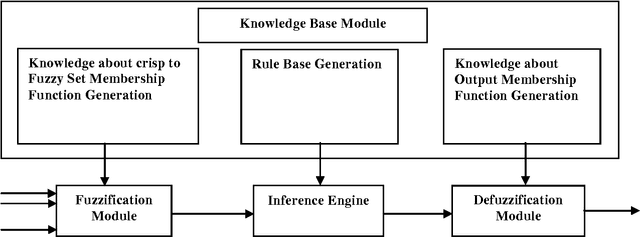
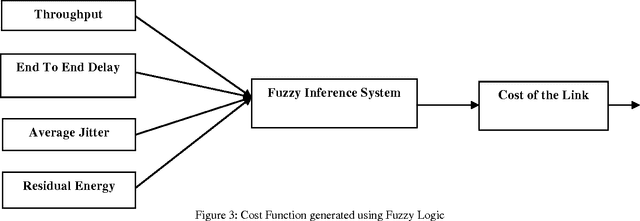
Dynamic behaviour of a WMN imposes stringent constraints on the routing policy of the network. In the shortest path based routing the shortest paths needs to be evaluated within a given time frame allowed by the WMN dynamics. The exact reasoning based shortest path evaluation methods usually fail to meet this rigid requirement. Thus, requiring some soft computing based approaches which can replace "best for sure" solutions with "good enough" solutions. This paper proposes a framework for optimal routing in the WMNs; where we investigate the suitability of Big Bang-Big Crunch (BB-BC), a soft computing based approach to evaluate shortest/near-shortest path. In order to make routing optimal we first propose to replace distance between the adjacent nodes with an integrated cost measure that takes into account throughput, delay, jitter and residual energy of a node. A fuzzy logic based inference mechanism evaluates this cost measure at each node. Using this distance measure we apply BB-BC optimization algorithm to evaluate shortest/near shortest path to update the routing tables periodically as dictated by network requirements. A large number of simulations were conducted and it has been observed that BB-BC algorithm appears to be a high potential candidate suitable for routing in WMNs.
* 8 pages, 19 Figures
Routing in Wireless Mesh Networks: Two Soft Computing Based Approaches
Jul 11, 2013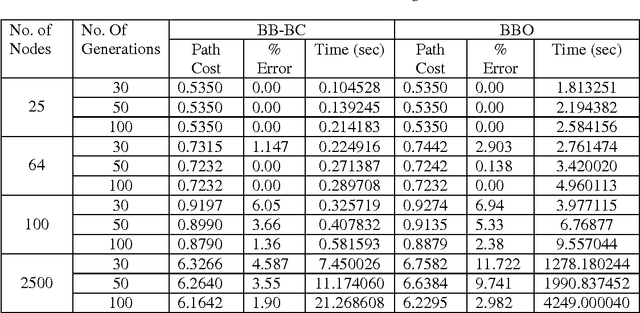
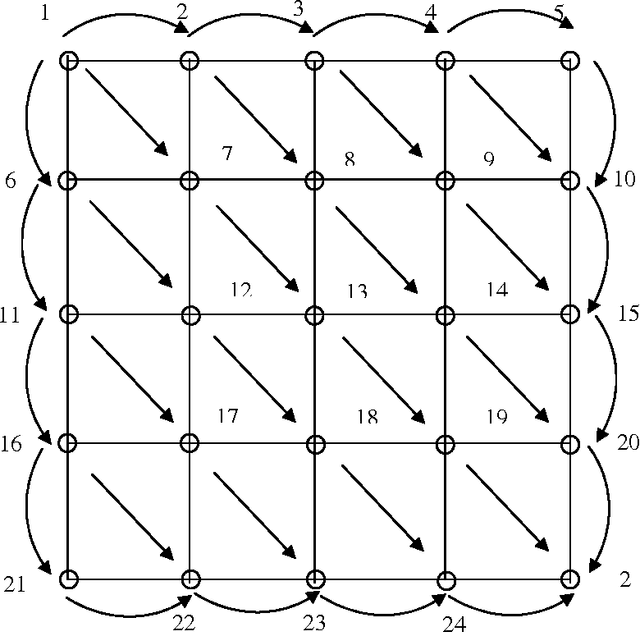

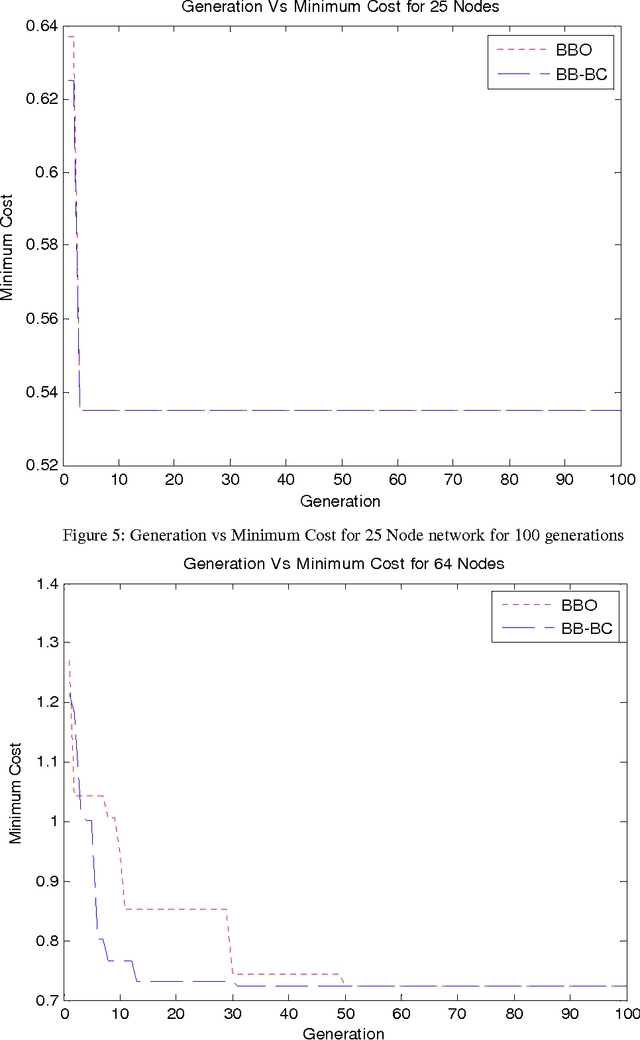
Due to dynamic network conditions, routing is the most critical part in WMNs and needs to be optimised. The routing strategies developed for WMNs must be efficient to make it an operationally self configurable network. Thus we need to resort to near shortest path evaluation. This lays down the requirement of some soft computing approaches such that a near shortest path is available in an affordable computing time. This paper proposes a Fuzzy Logic based integrated cost measure in terms of delay, throughput and jitter. Based upon this distance (cost) between two adjacent nodes we evaluate minimal shortest path that updates routing tables. We apply two recent soft computing approaches namely Big Bang Big Crunch (BB-BC) and Biogeography Based Optimization (BBO) approaches to enumerate shortest or near short paths. BB-BC theory is related with the evolution of the universe whereas BBO is inspired by dynamical equilibrium in the number of species on an island. Both the algorithms have low computational time and high convergence speed. Simulation results show that the proposed routing algorithms find the optimal shortest path taking into account three most important parameters of network dynamics. It has been further observed that for the shortest path problem BB-BC outperforms BBO in terms of speed and percent error between the evaluated minimal path and the actual shortest path.
* 11 Pages, 7 Figures