 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGDC- Generalized Distribution Calibration for Few-Shot Learning
Apr 11, 2022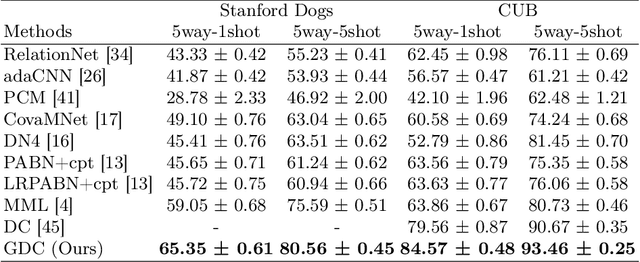
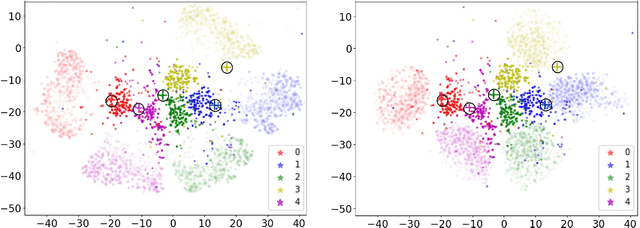
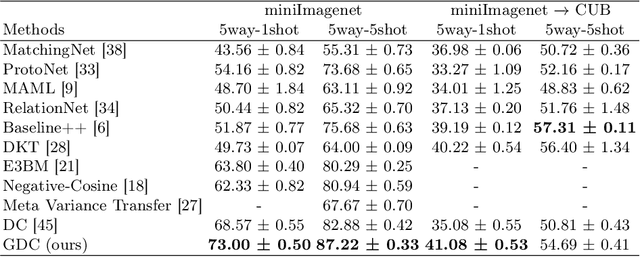
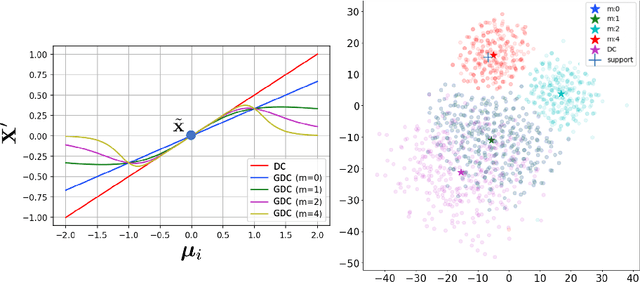
Few shot learning is an important problem in machine learning as large labelled datasets take considerable time and effort to assemble. Most few-shot learning algorithms suffer from one of two limitations- they either require the design of sophisticated models and loss functions, thus hampering interpretability; or employ statistical techniques but make assumptions that may not hold across different datasets or features. Developing on recent work in extrapolating distributions of small sample classes from the most similar larger classes, we propose a Generalized sampling method that learns to estimate few-shot distributions for classification as weighted random variables of all large classes. We use a form of covariance shrinkage to provide robustness against singular covariances due to overparameterized features or small datasets. We show that our sampled points are close to few-shot classes even in cases when there are no similar large classes in the training set. Our method works with arbitrary off-the-shelf feature extractors and outperforms existing state-of-the-art on miniImagenet, CUB and Stanford Dogs datasets by 3% to 5% on 5way-1shot and 5way-5shot tasks and by 1% in challenging cross domain tasks.
Learning Robust Latent Representations for Controllable Speech Synthesis
May 10, 2021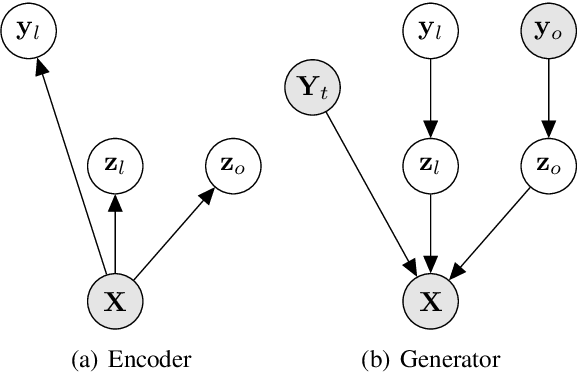
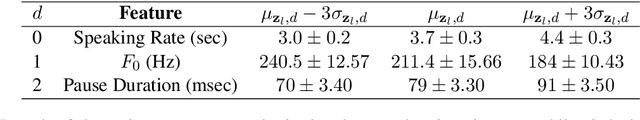
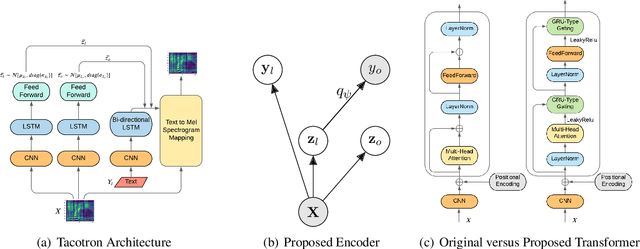

State-of-the-art Variational Auto-Encoders (VAEs) for learning disentangled latent representations give impressive results in discovering features like pitch, pause duration, and accent in speech data, leading to highly controllable text-to-speech (TTS) synthesis. However, these LSTM-based VAEs fail to learn latent clusters of speaker attributes when trained on either limited or noisy datasets. Further, different latent variables start encoding the same features, limiting the control and expressiveness during speech synthesis. To resolve these issues, we propose RTI-VAE (Reordered Transformer with Information reduction VAE) where we minimize the mutual information between different latent variables and devise a modified Transformer architecture with layer reordering to learn controllable latent representations in speech data. We show that RTI-VAE reduces the cluster overlap of speaker attributes by at least 30\% over LSTM-VAE and by at least 7\% over vanilla Transformer-VAE.
A Financial Service Chatbot based on Deep Bidirectional Transformers
Feb 17, 2020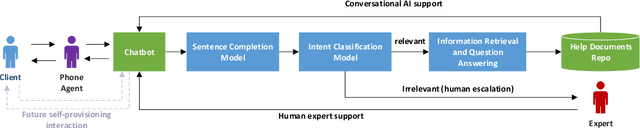

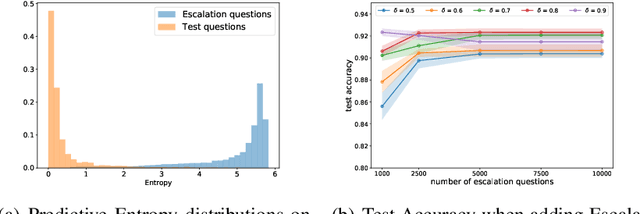
We develop a chatbot using Deep Bidirectional Transformer models (BERT) to handle client questions in financial investment customer service. The bot can recognize 381 intents, and decides when to say "I don't know" and escalates irrelevant/uncertain questions to human operators. Our main novel contribution is the discussion about uncertainty measure for BERT, where three different approaches are systematically compared on real problems. We investigated two uncertainty metrics, information entropy and variance of dropout sampling in BERT, followed by mixed-integer programming to optimize decision thresholds. Another novel contribution is the usage of BERT as a language model in automatic spelling correction. Inputs with accidental spelling errors can significantly decrease intent classification performance. The proposed approach combines probabilities from masked language model and word edit distances to find the best corrections for misspelled words. The chatbot and the entire conversational AI system are developed using open-source tools, and deployed within our company's intranet. The proposed approach can be useful for industries seeking similar in-house solutions in their specific business domains. We share all our code and a sample chatbot built on a public dataset on Github.