 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Robust Latent Representations for Controllable Speech Synthesis
May 10, 2021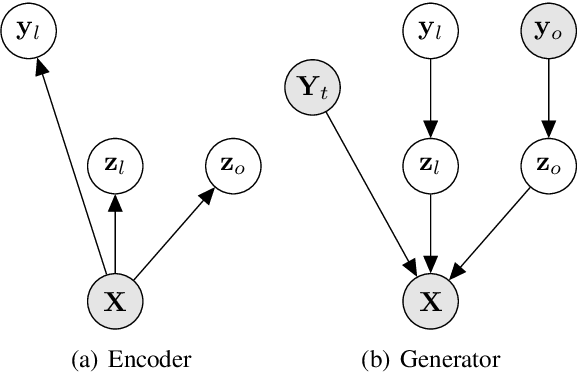
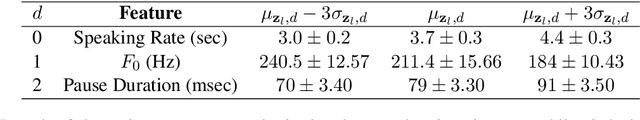
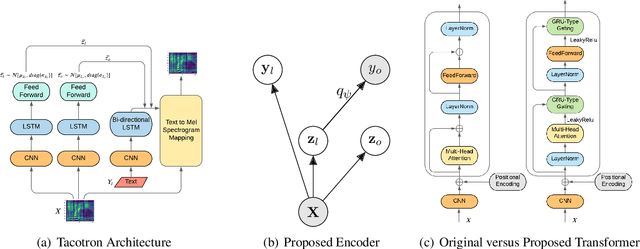

State-of-the-art Variational Auto-Encoders (VAEs) for learning disentangled latent representations give impressive results in discovering features like pitch, pause duration, and accent in speech data, leading to highly controllable text-to-speech (TTS) synthesis. However, these LSTM-based VAEs fail to learn latent clusters of speaker attributes when trained on either limited or noisy datasets. Further, different latent variables start encoding the same features, limiting the control and expressiveness during speech synthesis. To resolve these issues, we propose RTI-VAE (Reordered Transformer with Information reduction VAE) where we minimize the mutual information between different latent variables and devise a modified Transformer architecture with layer reordering to learn controllable latent representations in speech data. We show that RTI-VAE reduces the cluster overlap of speaker attributes by at least 30\% over LSTM-VAE and by at least 7\% over vanilla Transformer-VAE.
Machine Learning Fund Categorizations
May 29, 2020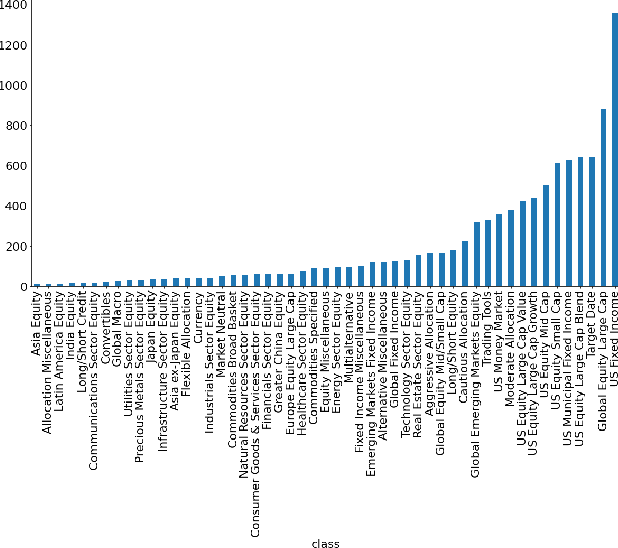
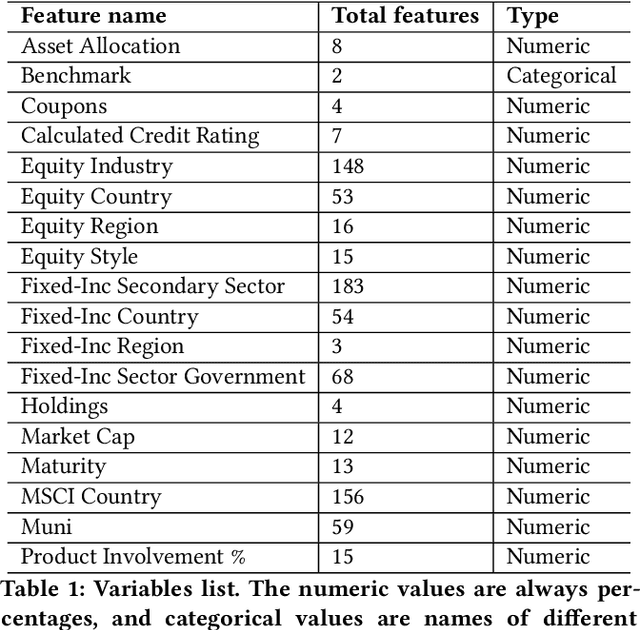
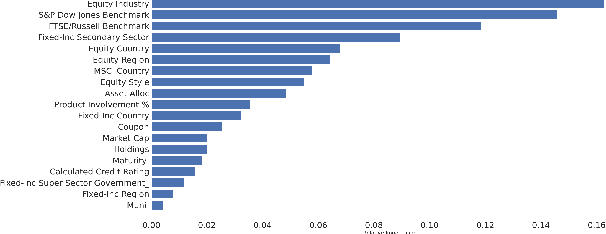
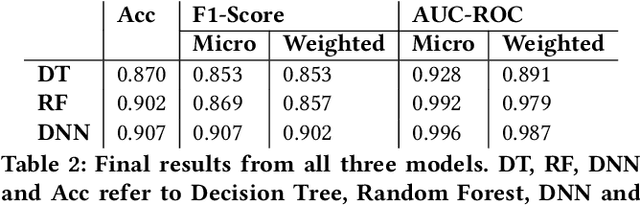
Given the surge in popularity of mutual funds (including exchange-traded funds (ETFs)) as a diversified financial investment, a vast variety of mutual funds from various investment management firms and diversification strategies have become available in the market. Identifying similar mutual funds among such a wide landscape of mutual funds has become more important than ever because of many applications ranging from sales and marketing to portfolio replication, portfolio diversification and tax loss harvesting. The current best method is data-vendor provided categorization which usually relies on curation by human experts with the help of available data. In this work, we establish that an industry wide well-regarded categorization system is learnable using machine learning and largely reproducible, and in turn constructing a truly data-driven categorization. We discuss the intellectual challenges in learning this man-made system, our results and their implications.