Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Attention Span in Computer Vision
Paper and Code
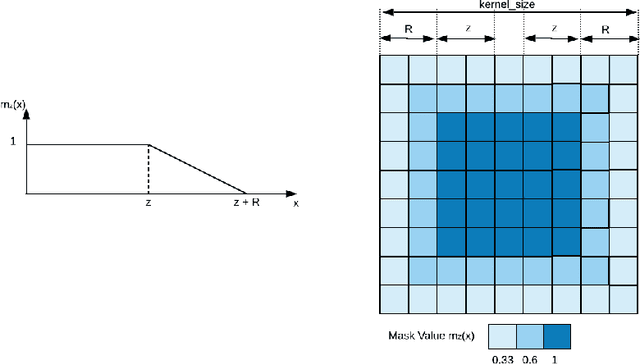

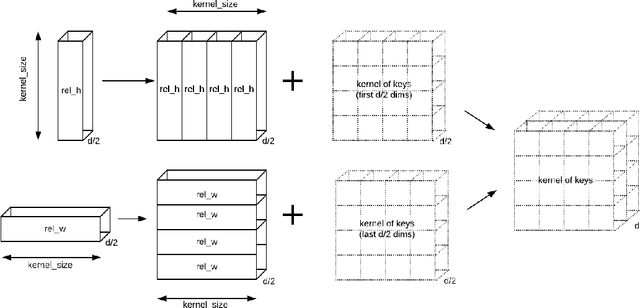
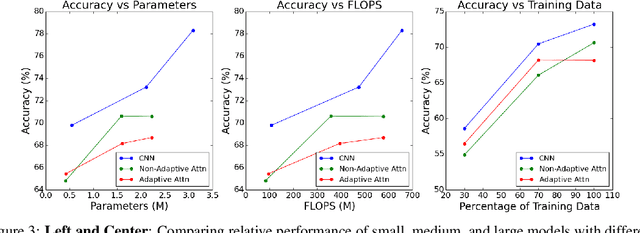
Recent developments in Transformers for language modeling have opened new areas of research in computer vision. Results from late 2019 showed vast performance increases in both object detection and recognition when convolutions are replaced by local self-attention kernels. Models using local self-attention kernels were also shown to have less parameters and FLOPS compared to equivalent architectures that only use convolutions. In this work we propose a novel method for learning the local self-attention kernel size. We then compare its performance to fixed-size local attention and convolution kernels. The code for all our experiments and models is available at https://github.com/JoeRoussy/adaptive-attention-in-cv
* 6 pages with 1 Algorithm, 4 figures, 1 Table and 1 page appendix
View paper on