 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Machine Translation with Monte-Carlo Tree Search
Apr 27, 2020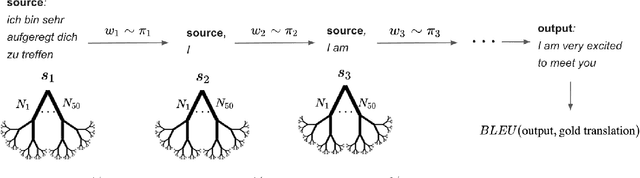
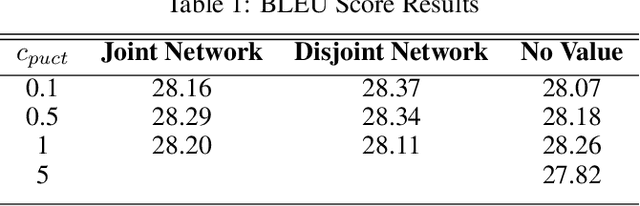
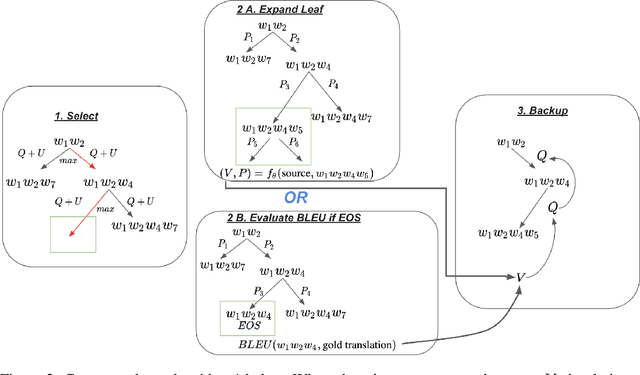
Recent algorithms in machine translation have included a value network to assist the policy network when deciding which word to output at each step of the translation. The addition of a value network helps the algorithm perform better on evaluation metrics like the BLEU score. After training the policy and value networks in a supervised setting, the policy and value networks can be jointly improved through common actor-critic methods. The main idea of our project is to instead leverage Monte-Carlo Tree Search (MCTS) to search for good output words with guidance from a combined policy and value network architecture in a similar fashion as AlphaZero. This network serves both as a local and a global look-ahead reference that uses the result of the search to improve itself. Experiments using the IWLST14 German to English translation dataset show that our method outperforms the actor-critic methods used in recent machine translation papers.
Adaptive Attention Span in Computer Vision
Apr 18, 2020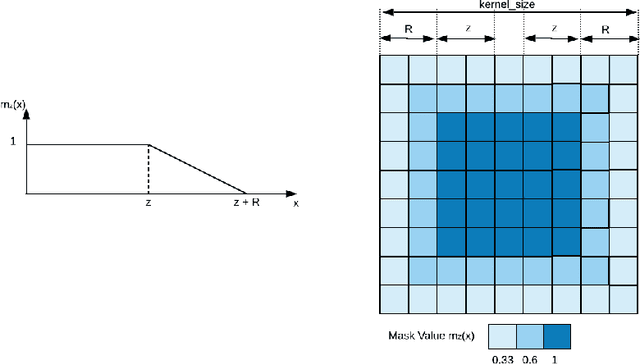

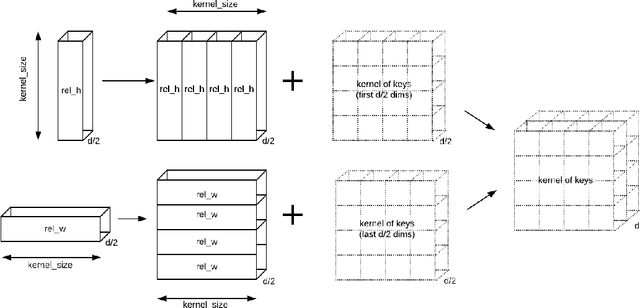
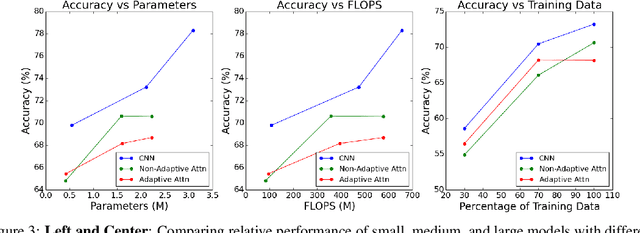
Recent developments in Transformers for language modeling have opened new areas of research in computer vision. Results from late 2019 showed vast performance increases in both object detection and recognition when convolutions are replaced by local self-attention kernels. Models using local self-attention kernels were also shown to have less parameters and FLOPS compared to equivalent architectures that only use convolutions. In this work we propose a novel method for learning the local self-attention kernel size. We then compare its performance to fixed-size local attention and convolution kernels. The code for all our experiments and models is available at https://github.com/JoeRoussy/adaptive-attention-in-cv
Adaptive Transformers in RL
Apr 08, 2020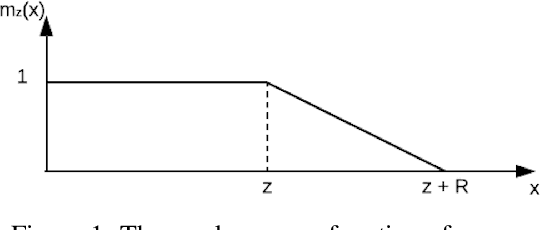
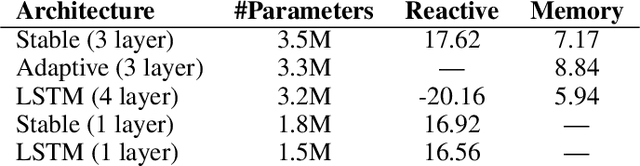
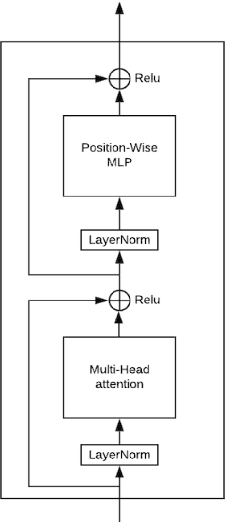
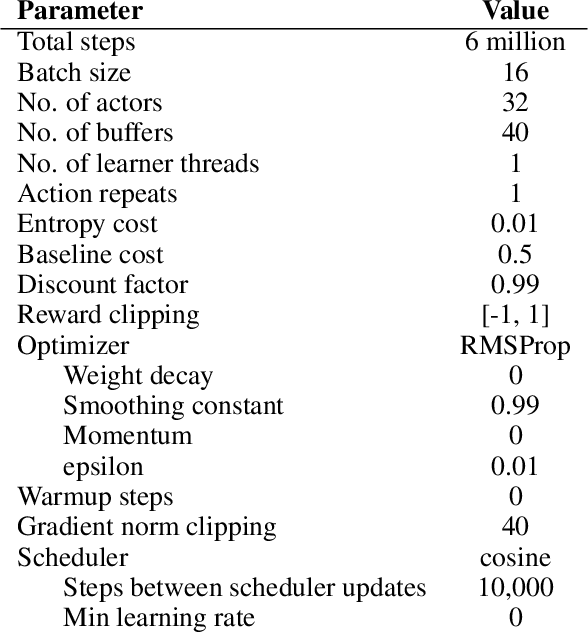
Recent developments in Transformers have opened new interesting areas of research in partially observable reinforcement learning tasks. Results from late 2019 showed that Transformers are able to outperform LSTMs on both memory intense and reactive tasks. In this work we first partially replicate the results shown in Stabilizing Transformers in RL on both reactive and memory based environments. We then show performance improvement coupled with reduced computation when adding adaptive attention span to this Stable Transformer on a challenging DMLab30 environment. The code for all our experiments and models is available at https://github.com/jerrodparker20/adaptive-transformers-in-rl.