 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Fluent Query Reformulations with Text-to-Text Transformers and Reinforcement Learning
Dec 18, 2020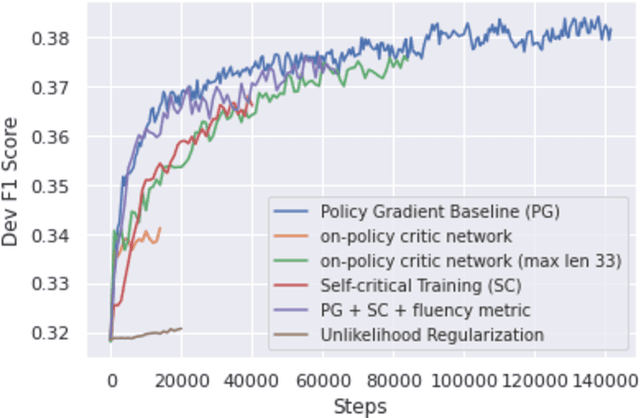
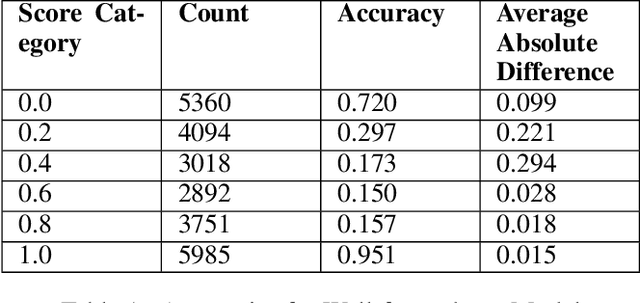
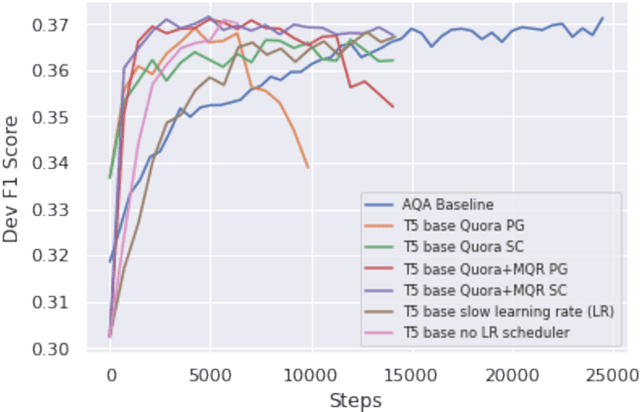

Query reformulation aims to alter potentially noisy or ambiguous text sequences into coherent ones closer to natural language questions. In this process, it is also crucial to maintain and even enhance performance in a downstream environments like question answering when rephrased queries are given as input. We explore methods to generate these query reformulations by training reformulators using text-to-text transformers and apply policy-based reinforcement learning algorithms to further encourage reward learning. Query fluency is numerically evaluated by the same class of model fine-tuned on a human-evaluated well-formedness dataset. The reformulator leverages linguistic knowledge obtained from transfer learning and generates more well-formed reformulations than a translation-based model in qualitative and quantitative analysis. During reinforcement learning, it better retains fluency while optimizing the RL objective to acquire question answering rewards and can generalize to out-of-sample textual data in qualitative evaluations. Our RL framework is demonstrated to be flexible, allowing reward signals to be sourced from different downstream environments such as intent classification.
Neural Machine Translation with Monte-Carlo Tree Search
Apr 27, 2020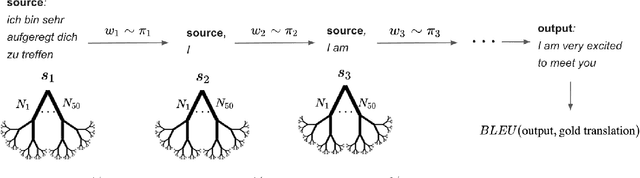
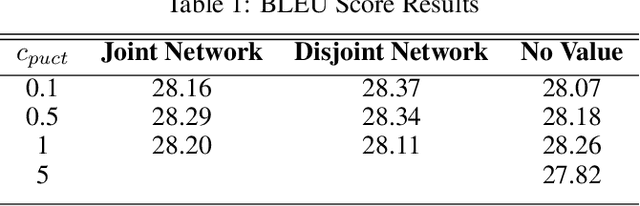
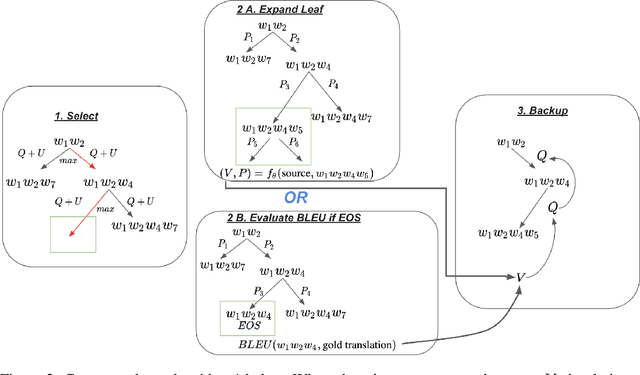
Recent algorithms in machine translation have included a value network to assist the policy network when deciding which word to output at each step of the translation. The addition of a value network helps the algorithm perform better on evaluation metrics like the BLEU score. After training the policy and value networks in a supervised setting, the policy and value networks can be jointly improved through common actor-critic methods. The main idea of our project is to instead leverage Monte-Carlo Tree Search (MCTS) to search for good output words with guidance from a combined policy and value network architecture in a similar fashion as AlphaZero. This network serves both as a local and a global look-ahead reference that uses the result of the search to improve itself. Experiments using the IWLST14 German to English translation dataset show that our method outperforms the actor-critic methods used in recent machine translation papers.
Reinforcement Learning Generalization with Surprise Minimization
Apr 26, 2020
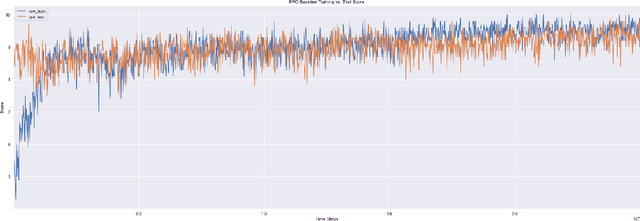
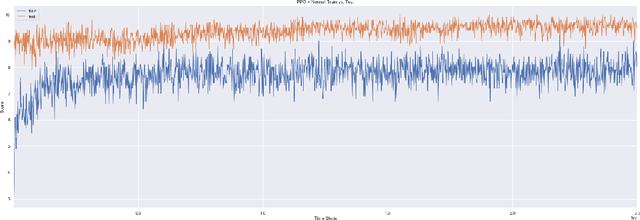
Generalization remains a challenging problem for reinforcement learning algorithms, which are often trained and tested on the same set of environments. When test environments are perturbed but the task is semantically the same, agents can still fail to perform accurately. Particularly when they are trained on high-dimensional state spaces, such as images. We evaluate an surprise minimizing agent on a generalization benchmark to show an additional reward learned from a density model can help agents acquire robust skills on unseen procedurally generated diverse environments.