Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning Generalization with Surprise Minimization
Paper and Code

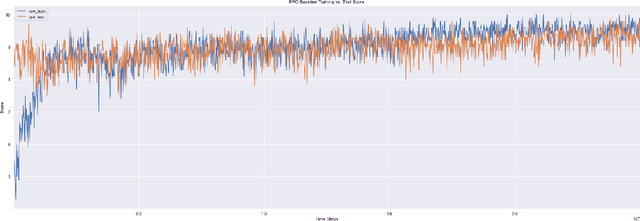
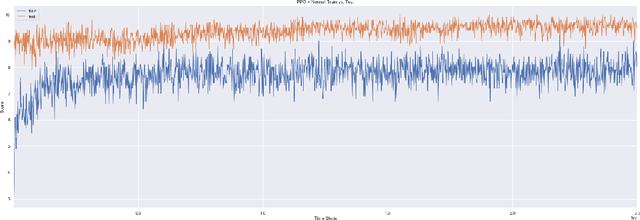
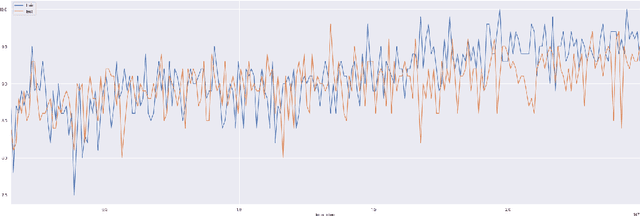
Generalization remains a challenging problem for reinforcement learning algorithms, which are often trained and tested on the same set of environments. When test environments are perturbed but the task is semantically the same, agents can still fail to perform accurately. Particularly when they are trained on high-dimensional state spaces, such as images. We evaluate an surprise minimizing agent on a generalization benchmark to show an additional reward learned from a density model can help agents acquire robust skills on unseen procedurally generated diverse environments.
View paper on