 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Fluent Query Reformulations with Text-to-Text Transformers and Reinforcement Learning
Paper and Code
Dec 18, 2020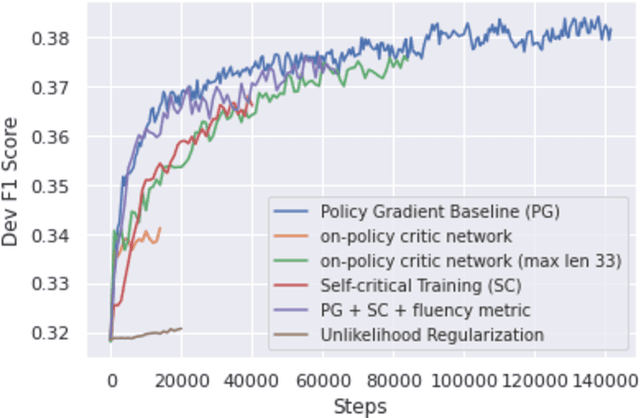
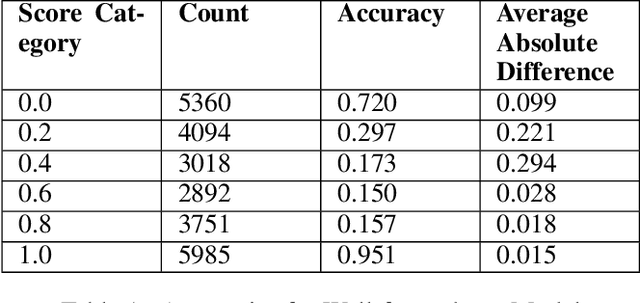
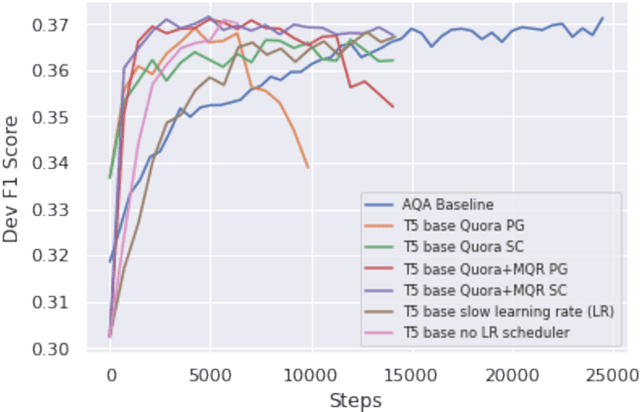

Query reformulation aims to alter potentially noisy or ambiguous text sequences into coherent ones closer to natural language questions. In this process, it is also crucial to maintain and even enhance performance in a downstream environments like question answering when rephrased queries are given as input. We explore methods to generate these query reformulations by training reformulators using text-to-text transformers and apply policy-based reinforcement learning algorithms to further encourage reward learning. Query fluency is numerically evaluated by the same class of model fine-tuned on a human-evaluated well-formedness dataset. The reformulator leverages linguistic knowledge obtained from transfer learning and generates more well-formed reformulations than a translation-based model in qualitative and quantitative analysis. During reinforcement learning, it better retains fluency while optimizing the RL objective to acquire question answering rewards and can generalize to out-of-sample textual data in qualitative evaluations. Our RL framework is demonstrated to be flexible, allowing reward signals to be sourced from different downstream environments such as intent classification.