 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepCQ: General-Purpose Deep-Surrogate Framework for Lossy Compression Quality Prediction
Dec 24, 2025Error-bounded lossy compression techniques have become vital for scientific data management and analytics, given the ever-increasing volume of data generated by modern scientific simulations and instruments. Nevertheless, assessing data quality post-compression remains computationally expensive due to the intensive nature of metric calculations. In this work, we present a general-purpose deep-surrogate framework for lossy compression quality prediction (DeepCQ), with the following key contributions: 1) We develop a surrogate model for compression quality prediction that is generalizable to different error-bounded lossy compressors, quality metrics, and input datasets; 2) We adopt a novel two-stage design that decouples the computationally expensive feature-extraction stage from the light-weight metrics prediction, enabling efficient training and modular inference; 3) We optimize the model performance on time-evolving data using a mixture-of-experts design. Such a design enhances the robustness when predicting across simulation timesteps, especially when the training and test data exhibit significant variation. We validate the effectiveness of DeepCQ on four real-world scientific applications. Our results highlight the framework's exceptional predictive accuracy, with prediction errors generally under 10\% across most settings, significantly outperforming existing methods. Our framework empowers scientific users to make informed decisions about data compression based on their preferred data quality, thereby significantly reducing I/O and computational overhead in scientific data analysis.
Fast, high-fidelity Lyman $α$ forests with convolutional neural networks
Jun 23, 2021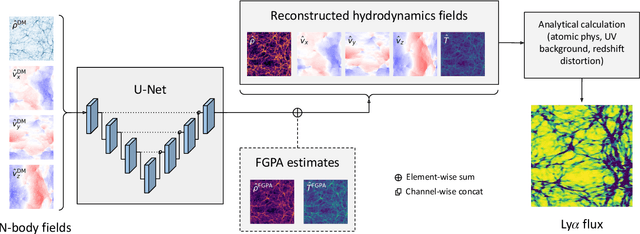
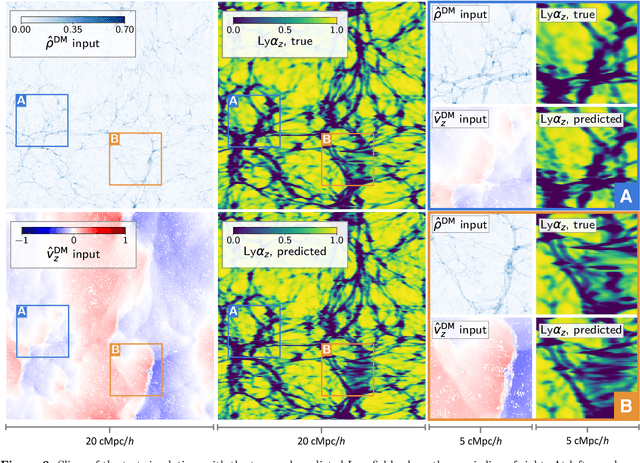
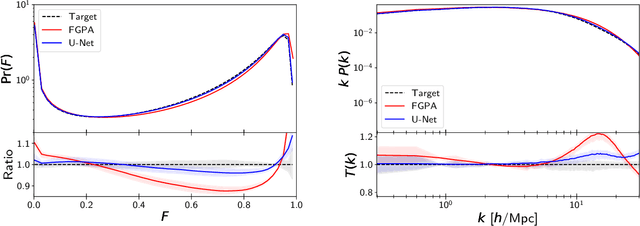
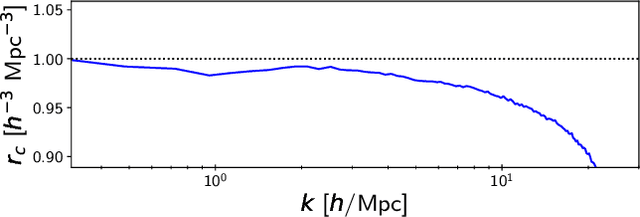
Full-physics cosmological simulations are powerful tools for studying the formation and evolution of structure in the universe but require extreme computational resources. Here, we train a convolutional neural network to use a cheaper N-body-only simulation to reconstruct the baryon hydrodynamic variables (density, temperature, and velocity) on scales relevant to the Lyman-$\alpha$ (Ly$\alpha$) forest, using data from Nyx simulations. We show that our method enables rapid estimation of these fields at a resolution of $\sim$20kpc, and captures the statistics of the Ly$\alpha$ forest with much greater accuracy than existing approximations. Because our model is fully-convolutional, we can train on smaller simulation boxes and deploy on much larger ones, enabling substantial computational savings. Furthermore, as our method produces an approximation for the hydrodynamic fields instead of Ly$\alpha$ flux directly, it is not limited to a particular choice of ionizing background or mean transmitted flux.
Estimating Galactic Distances From Images Using Self-supervised Representation Learning
Jan 12, 2021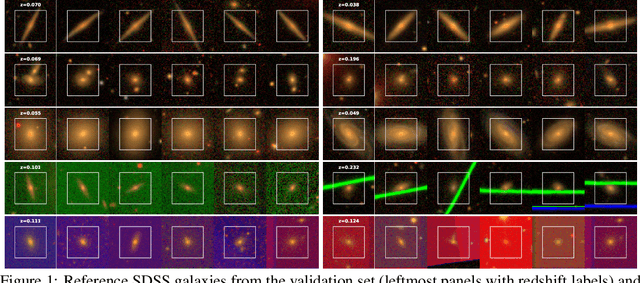
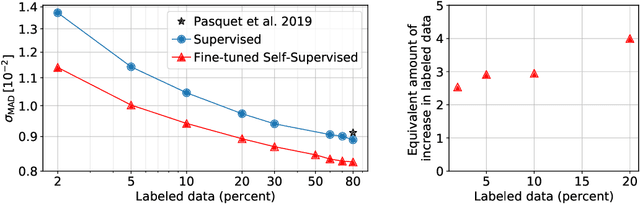
We use a contrastive self-supervised learning framework to estimate distances to galaxies from their photometric images. We incorporate data augmentations from computer vision as well as an application-specific augmentation accounting for galactic dust. We find that the resulting visual representations of galaxy images are semantically useful and allow for fast similarity searches, and can be successfully fine-tuned for the task of redshift estimation. We show that (1) pretraining on a large corpus of unlabeled data followed by fine-tuning on some labels can attain the accuracy of a fully-supervised model which requires 2-4x more labeled data, and (2) that by fine-tuning our self-supervised representations using all available data labels in the Main Galaxy Sample of the Sloan Digital Sky Survey (SDSS), we outperform the state-of-the-art supervised learning method.
Self-Supervised Representation Learning for Astronomical Images
Dec 24, 2020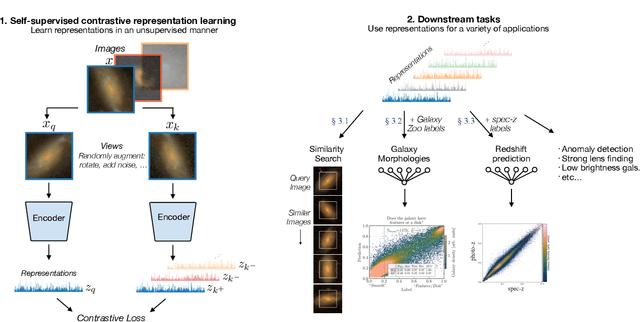

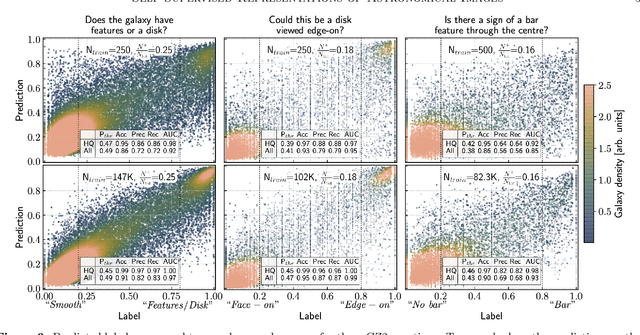
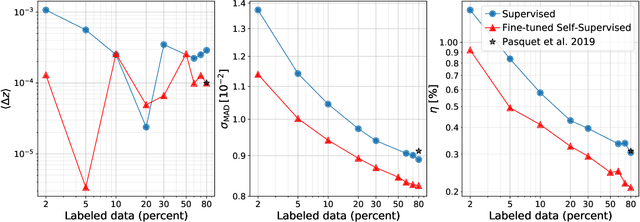
Sky surveys are the largest data generators in astronomy, making automated tools for extracting meaningful scientific information an absolute necessity. We show that, without the need for labels, self-supervised learning recovers representations of sky survey images that are semantically useful for a variety of scientific tasks. These representations can be directly used as features, or fine-tuned, to outperform supervised methods trained only on labeled data. We apply a contrastive learning framework on multi-band galaxy photometry from the Sloan Digital Sky Survey (SDSS) to learn image representations. We then use them for galaxy morphology classification, and fine-tune them for photometric redshift estimation, using labels from the Galaxy Zoo 2 dataset and SDSS spectroscopy. In both downstream tasks, using the same learned representations, we outperform the supervised state-of-the-art results, and we show that our approach can achieve the accuracy of supervised models while using 2-4 times fewer labels for training.
Creating Virtual Universes Using Generative Adversarial Networks
Aug 17, 2018
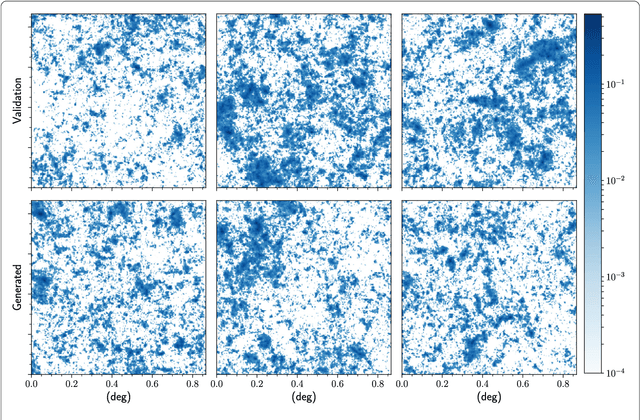

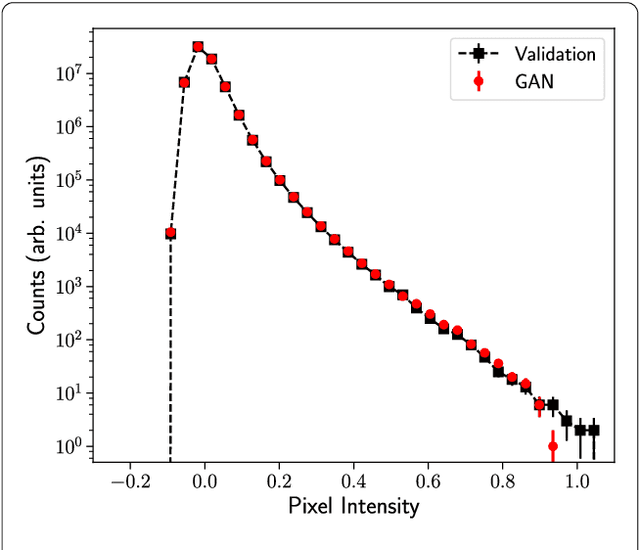
Inferring model parameters from experimental data is a grand challenge in many sciences, including cosmology. This often relies critically on high fidelity numerical simulations, which are prohibitively computationally expensive. The application of deep learning techniques to generative modeling is renewing interest in using high dimensional density estimators as computationally inexpensive emulators of fully-fledged simulations. These generative models have the potential to make a dramatic shift in the field of scientific simulations, but for that shift to happen we need to study the performance of such generators in the precision regime needed for science applications. To this end, in this letter we apply Generative Adversarial Networks to the problem of generating cosmological weak lensing convergence maps. We show that our generator network produces maps that are described by, with high statistical confidence, the same summary statistics as the fully simulated maps.