 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabPFGen -- Tabular Data Generation with TabPFN
Jun 07, 2024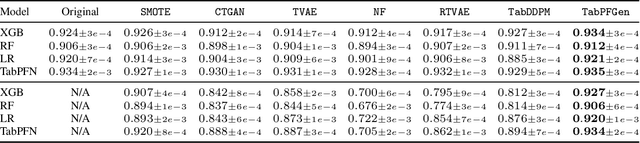
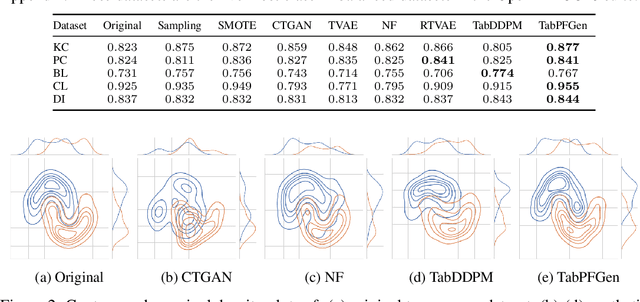
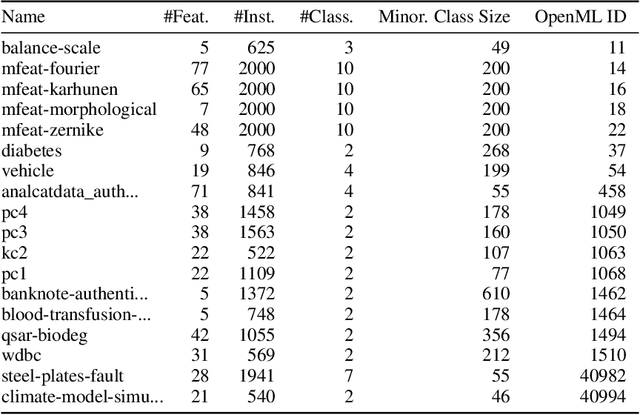
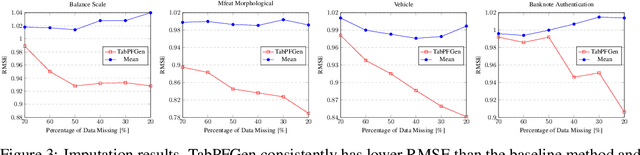
Advances in deep generative modelling have not translated well to tabular data. We argue that this is caused by a mismatch in structure between popular generative models and discriminative models of tabular data. We thus devise a technique to turn TabPFN -- a highly performant transformer initially designed for in-context discriminative tabular tasks -- into an energy-based generative model, which we dub TabPFGen. This novel framework leverages the pre-trained TabPFN as part of the energy function and does not require any additional training or hyperparameter tuning, thus inheriting TabPFN's in-context learning capability. We can sample from TabPFGen analogously to other energy-based models. We demonstrate strong results on standard generative modelling tasks, including data augmentation, class-balancing, and imputation, unlocking a new frontier of tabular data generation.
Retrieval & Fine-Tuning for In-Context Tabular Models
Jun 07, 2024Tabular data is a pervasive modality spanning a wide range of domains, and the inherent diversity poses a considerable challenge for deep learning. Recent advancements using transformer-based in-context learning have shown promise on smaller and less complex datasets, but have struggled to scale to larger and more complex ones. To address this limitation, we propose a combination of retrieval and fine-tuning: we can adapt the transformer to a local subset of the data by collecting nearest neighbours, and then perform task-specific fine-tuning with this retrieved set of neighbours in context. Using TabPFN as the base model -- currently the best tabular in-context learner -- and applying our retrieval and fine-tuning scheme on top results in what we call a locally-calibrated PFN, or LoCalPFN. We conduct extensive evaluation on 95 datasets curated by TabZilla from OpenML, upon which we establish a new state-of-the-art with LoCalPFN -- even with respect to tuned tree-based models. Notably, we show a significant boost in performance compared to the base in-context model, demonstrating the efficacy of our approach and advancing the frontier of deep learning in tabular data.
In-Context Data Distillation with TabPFN
Feb 10, 2024Foundation models have revolutionized tasks in computer vision and natural language processing. However, in the realm of tabular data, tree-based models like XGBoost continue to dominate. TabPFN, a transformer model tailored for tabular data, mirrors recent foundation models in its exceptional in-context learning capability, being competitive with XGBoost's performance without the need for task-specific training or hyperparameter tuning. Despite its promise, TabPFN's applicability is hindered by its data size constraint, limiting its use in real-world scenarios. To address this, we present in-context data distillation (ICD), a novel methodology that effectively eliminates these constraints by optimizing TabPFN's context. ICD efficiently enables TabPFN to handle significantly larger datasets with a fixed memory budget, improving TabPFN's quadratic memory complexity but at the cost of a linear number of tuning steps. Notably, TabPFN, enhanced with ICD, demonstrates very strong performance against established tree-based models and modern deep learning methods on 48 large tabular datasets from OpenML.
Variational Inference with Continuously-Indexed Normalizing Flows
Jul 10, 2020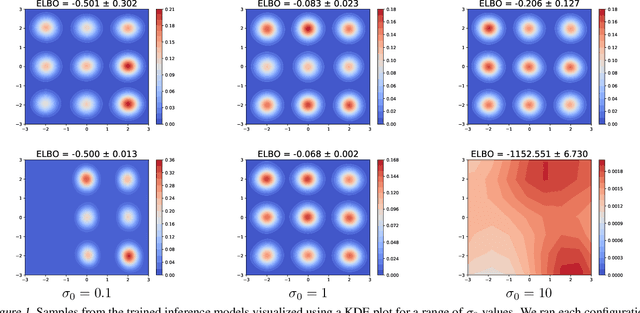
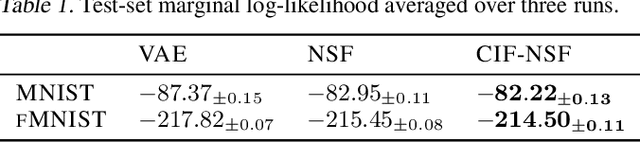

Continuously-indexed flows (CIFs) have recently achieved improvements over baseline normalizing flows in a variety of density estimation tasks. In this paper, we adapt CIFs to the task of variational inference (VI) through the framework of auxiliary VI, and demonstrate that the advantages of CIFs over baseline flows can also translate to the VI setting for both sampling from posteriors with complicated topology and performing maximum likelihood estimation in latent-variable models.
Detecting anthropogenic cloud perturbations with deep learning
Nov 29, 2019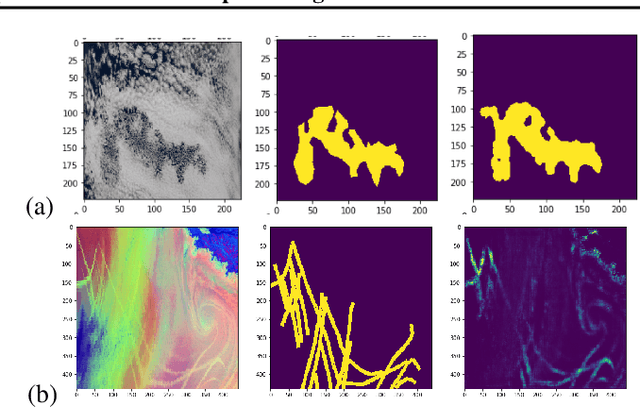
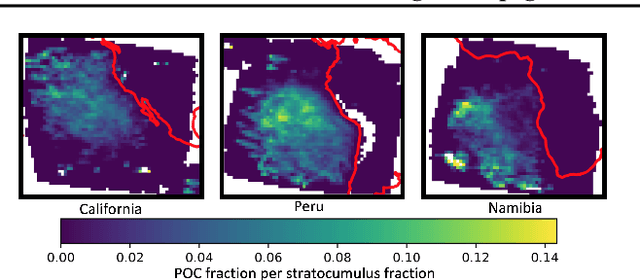
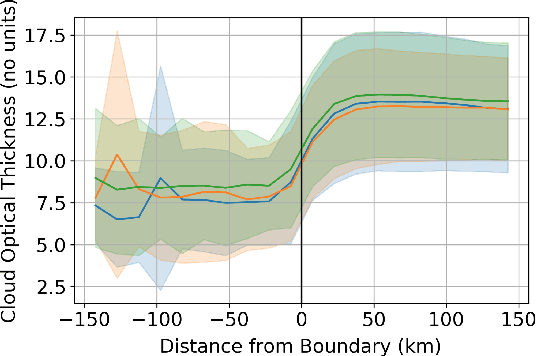
One of the most pressing questions in climate science is that of the effect of anthropogenic aerosol on the Earth's energy balance. Aerosols provide the `seeds' on which cloud droplets form, and changes in the amount of aerosol available to a cloud can change its brightness and other physical properties such as optical thickness and spatial extent. Clouds play a critical role in moderating global temperatures and small perturbations can lead to significant amounts of cooling or warming. Uncertainty in this effect is so large it is not currently known if it is negligible, or provides a large enough cooling to largely negate present-day warming by CO2. This work uses deep convolutional neural networks to look for two particular perturbations in clouds due to anthropogenic aerosol and assess their properties and prevalence, providing valuable insights into their climatic effects.
A Novel Representation of Neural Networks
Oct 07, 2016
Deep Neural Networks (DNNs) have become very popular for prediction in many areas. Their strength is in representation with a high number of parameters that are commonly learned via gradient descent or similar optimization methods. However, the representation is non-standardized, and the gradient calculation methods are often performed using component-based approaches that break parameters down into scalar units, instead of considering the parameters as whole entities. In this work, these problems are addressed. Standard notation is used to represent DNNs in a compact framework. Gradients of DNN loss functions are calculated directly over the inner product space on which the parameters are defined. This framework is general and is applied to two common network types: the Multilayer Perceptron and the Deep Autoencoder.