 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning-Based DRAM Equalizer Parameter Optimization Using Latent Representations
Jul 03, 2025Equalizer parameter optimization for signal integrity in high-speed Dynamic Random Access Memory systems is crucial but often computationally demanding or model-reliant. This paper introduces a data-driven framework employing learned latent signal representations for efficient signal integrity evaluation, coupled with a model-free Advantage Actor-Critic reinforcement learning agent for parameter optimization. The latent representation captures vital signal integrity features, offering a fast alternative to direct eye diagram analysis during optimization, while the reinforcement learning agent derives optimal equalizer settings without explicit system models. Applied to industry-standard Dynamic Random Access Memory waveforms, the method achieved significant eye-opening window area improvements: 42.7\% for cascaded Continuous-Time Linear Equalizer and Decision Feedback Equalizer structures, and 36.8\% for Decision Feedback Equalizer-only configurations. These results demonstrate superior performance, computational efficiency, and robust generalization across diverse Dynamic Random Access Memory units compared to existing techniques. Core contributions include an efficient latent signal integrity metric for optimization, a robust model-free reinforcement learning strategy, and validated superior performance for complex equalizer architectures.
Machine learning based state observer for discrete time systems evolving on Lie groups
Jan 20, 2024In this paper, a machine learning based observer for systems evolving on manifolds is designed such that the state of the observer is restricted to the Lie group on which the system evolves. Conventional techniques involving machine learning based observers on systems evolving on Lie groups involve designing charts for the Lie group, training a machine learning based observer for each chart, and switching between the trained models based on the state of the system. We propose a novel deep learning based technique whose predictions are restricted to a measure 0 subset of Euclidean space without using charts. Using this network, we design an observer ensuring that the state of the observer is restricted to the Lie group, and predicting the state using only one trained algorithm. The deep learning network predicts an ``error term'' on the Lie algebra of the Lie group, uses the map from the Lie algebra to the group, and uses the group action and the present state to estimate the state at the next epoch. This model being purely data driven does not require the model of the system. The proposed algorithm provides a novel framework for constraining the output of machine learning networks to a measure 0 subset of a Euclidean space without chart specific training and without requiring switching. We show the validity of this method using Monte Carlo simulations performed of the rigid body rotation and translation system.
Unscented Kalman filter with stable embedding for simple, accurate and computationally efficient state estimation of systems on manifolds in Euclidean space
Aug 22, 2022
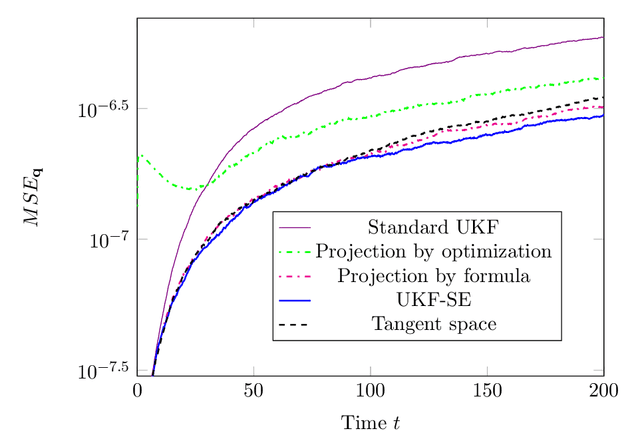
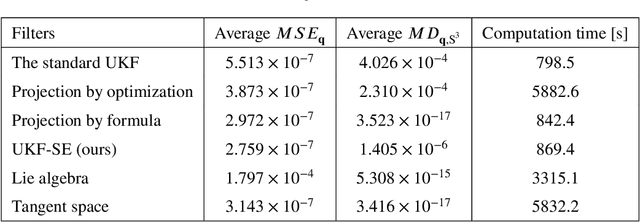
This paper proposes a simple, accurate and computationally efficient method to apply the ordinary unscented Kalman filter developed in Euclidean space to systems whose dynamics evolve on manifolds.We use the mathematical theory called stable embedding to make a variant of unscented Kalman filter that keeps state estimates in closeproximity to the manifold while exhibiting excellent estimation performance. We confirm the performance of our devised filter by applying it to the satellite system model and comparing the performance with other unscented Kalman filters devised specifically for systems on manifolds. Our devised filter has a low estimation error, keeps the state estimates in close proximity to the manifold as expected, and consumes a minor amount of computation time. Also our devised filter is simple and easy to use because our filter directly employs the off-the-shelf standard unscented Kalman filter devised in Euclidean space without any particular manifold-structure-preserving discretization method or coordinate transformation.
Feedback Gradient Descent: Efficient and Stable Optimization with Orthogonality for DNNs
May 12, 2022
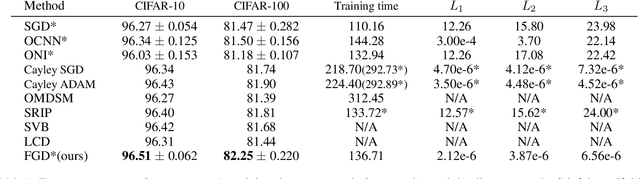
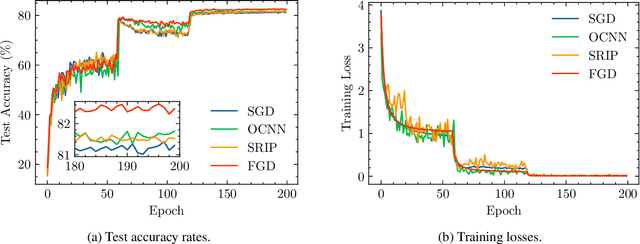

The optimization with orthogonality has been shown useful in training deep neural networks (DNNs). To impose orthogonality on DNNs, both computational efficiency and stability are important. However, existing methods utilizing Riemannian optimization or hard constraints can only ensure stability while those using soft constraints can only improve efficiency. In this paper, we propose a novel method, named Feedback Gradient Descent (FGD), to our knowledge, the first work showing high efficiency and stability simultaneously. FGD induces orthogonality based on the simple yet indispensable Euler discretization of a continuous-time dynamical system on the tangent bundle of the Stiefel manifold. In particular, inspired by a numerical integration method on manifolds called Feedback Integrators, we propose to instantiate it on the tangent bundle of the Stiefel manifold for the first time. In the extensive image classification experiments, FGD comprehensively outperforms the existing state-of-the-art methods in terms of accuracy, efficiency, and stability.
Robust Navigation for Racing Drones based on Imitation Learning and Modularization
May 27, 2021



This paper presents a vision-based modularized drone racing navigation system that uses a customized convolutional neural network (CNN) for the perception module to produce high-level navigation commands and then leverages a state-of-the-art planner and controller to generate low-level control commands, thus exploiting the advantages of both data-based and model-based approaches. Unlike the state-of-the-art method which only takes the current camera image as the CNN input, we further add the latest three drone states as part of the inputs. Our method outperforms the state-of-the-art method in various track layouts and offers two switchable navigation behaviors with a single trained network. The CNN-based perception module is trained to imitate an expert policy that automatically generates ground truth navigation commands based on the pre-computed global trajectories. Owing to the extensive randomization and our modified dataset aggregation (DAgger) policy during data collection, our navigation system, which is purely trained in simulation with synthetic textures, successfully operates in environments with randomly-chosen photorealistic textures without further fine-tuning.
The Adaptive Dynamic Programming Toolbox
Dec 29, 2020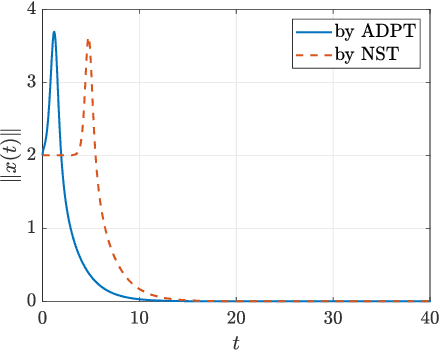
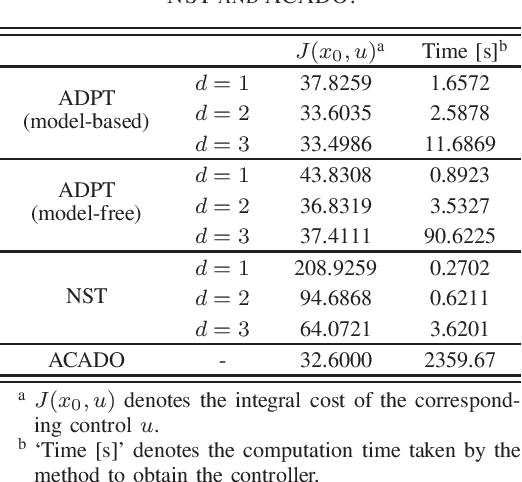


The paper develops the Adaptive Dynamic Programming Toolbox (ADPT), which solves optimal control problems for continuous-time nonlinear systems. Based on the adaptive dynamic programming technique, the ADPT computes optimal feedback controls from the system dynamics in the model-based working mode, or from measurements of trajectories of the system in the model-free working mode without the requirement of knowledge of the system model. Multiple options are provided such that the ADPT can accommodate various customized circumstances. Compared to other popular software toolboxes for optimal control, the ADPT enjoys its computational precision and speed, which is illustrated with its applications to a satellite attitude control problem.
Double Prioritized State Recycled Experience Replay
Jul 15, 2020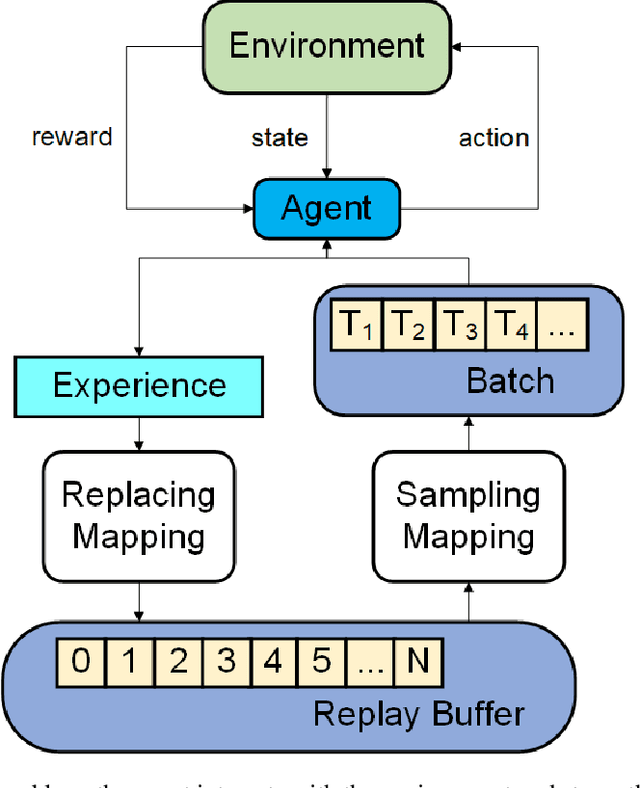
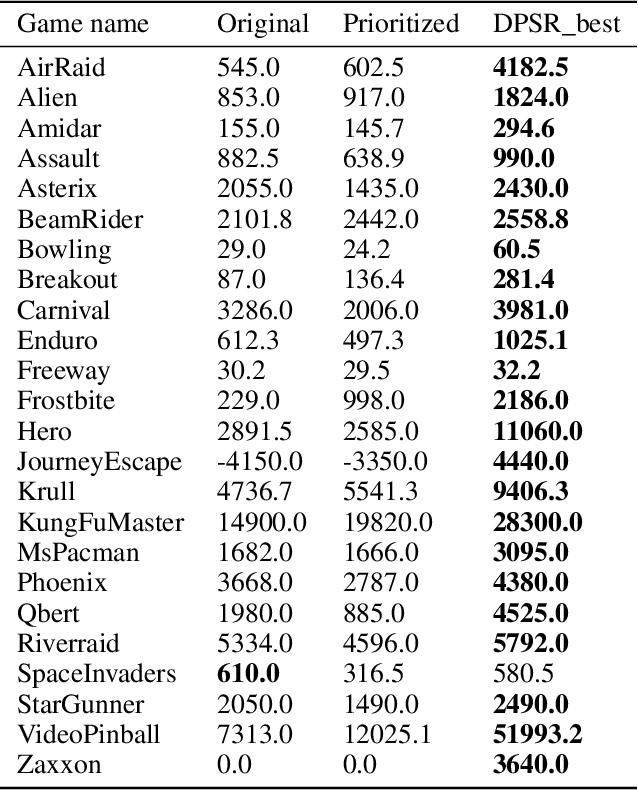
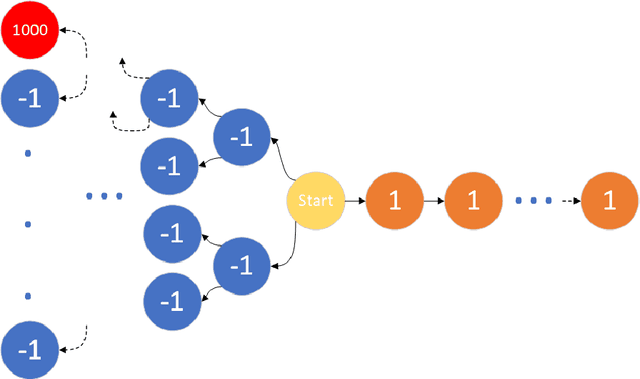

Experience replay enables online reinforcement learning agents to store and reuse the experiences generated in previous interaction with the environment. In the original method, the experiences are sampled and replayed to train the Q-network at the same possibility, i.e. uniformly. In prior work, a method called prioritized experience replay was developed where experiences in the memory are prioritized, so as to replay experiences which seem to be more important in higher frequencies for training the Q-network more efficiently. In this paper, we develop a method called double-prioritized state-recycled (DPSR) experience replay, prioritizing the experience both for training stage and storing stage, as well as replacing the experiences in the memory with state recycling to make the best of experiences which seem to have low priorities temporarily. We use this method in Deep Q-Networks (DQN), and achieve a state-of-the-art result, outperforming the original method and prioritized experience replay on many Atari games.
Deep Reinforcement Learning Based Robot Arm Manipulation with Efficient Training Data through Simulation
Sep 06, 2019

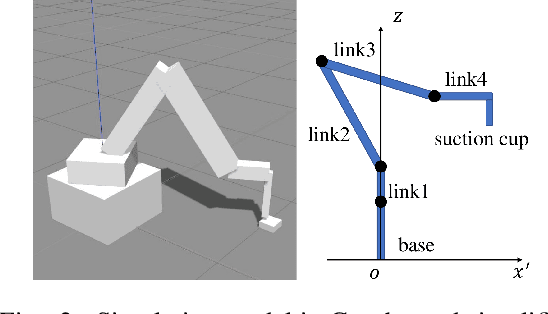
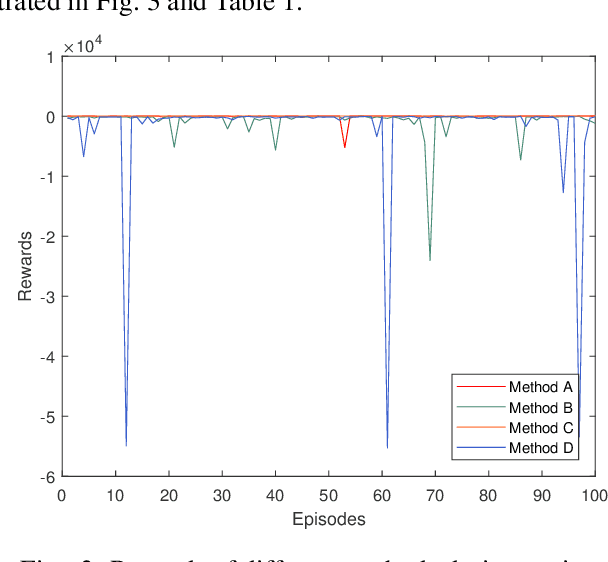
Deep reinforcement learning trains neural networks using experiences sampled from the replay buffer, which is commonly updated at each time step. In this paper, we propose a method to update the replay buffer adaptively and selectively to train a robot arm to accomplish a suction task in simulation. The response time of the agent is thoroughly taken into account. The state transitions that remain stuck at the boundary of constraint are not stored. The policy trained with our method works better than the one with the common replay buffer update method. The result is demonstrated both by simulation and by experiment with a real robot arm.
Improved Reinforcement Learning through Imitation Learning Pretraining Towards Image-based Autonomous Driving
Jul 16, 2019

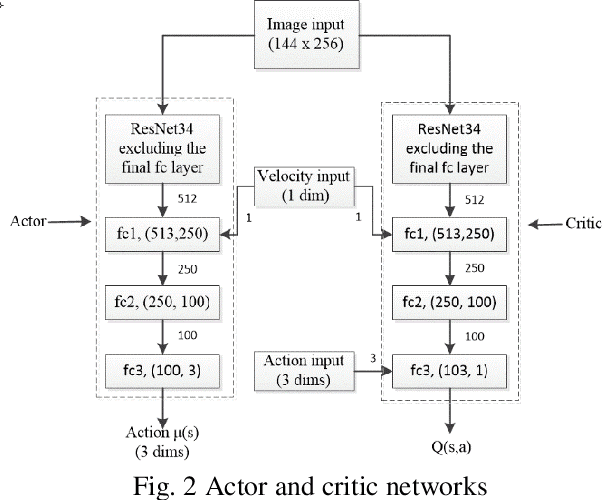

We present a training pipeline for the autonomous driving task given the current camera image and vehicle speed as the input to produce the throttle, brake, and steering control output. The simulator Airsim's convenient weather and lighting API provides a sufficient diversity during training which can be very helpful to increase the trained policy's robustness. In order to not limit the possible policy's performance, we use a continuous and deterministic control policy setting. We utilize ResNet-34 as our actor and critic networks with some slight changes in the fully connected layers. Considering human's mastery of this task and the high-complexity nature of this task, we first use imitation learning to mimic the given human policy and leverage the trained policy and its weights to the reinforcement learning phase for which we use DDPG. This combination shows a considerable performance boost comparing to both pure imitation learning and pure DDPG for the autonomous driving task.
A Dual Memory Structure for Efficient Use of Replay Memory in Deep Reinforcement Learning
Jul 15, 2019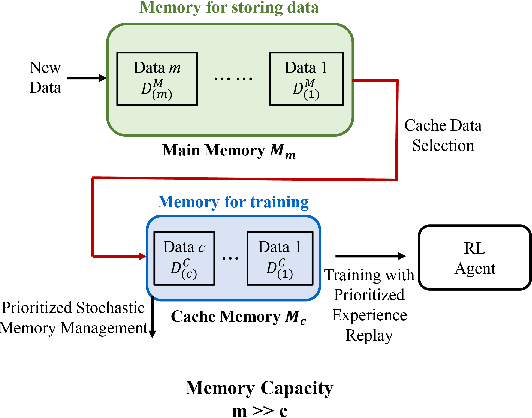

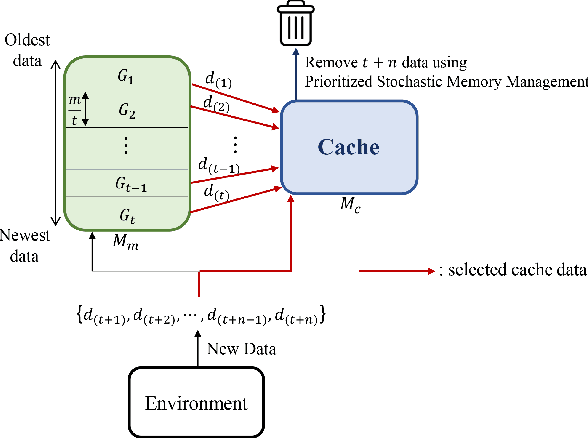
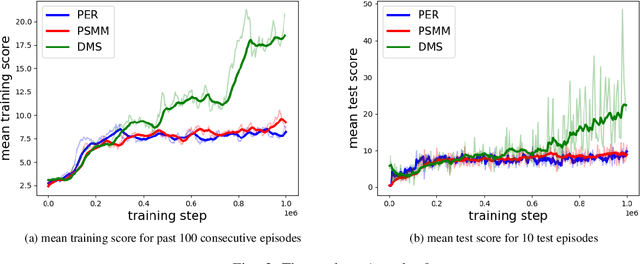
In this paper, we propose a dual memory structure for reinforcement learning algorithms with replay memory. The dual memory consists of a main memory that stores various data and a cache memory that manages the data and trains the reinforcement learning agent efficiently. Experimental results show that the dual memory structure achieves higher training and test scores than the conventional single memory structure in three selected environments of OpenAI Gym. This implies that the dual memory structure enables better and more efficient training than the single memory structure.