 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouble Prioritized State Recycled Experience Replay
Paper and Code
Jul 15, 2020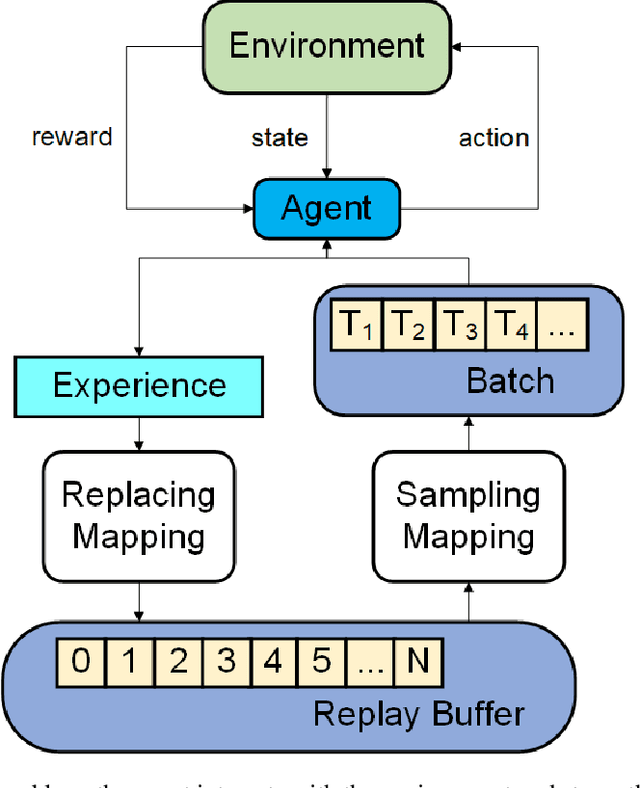
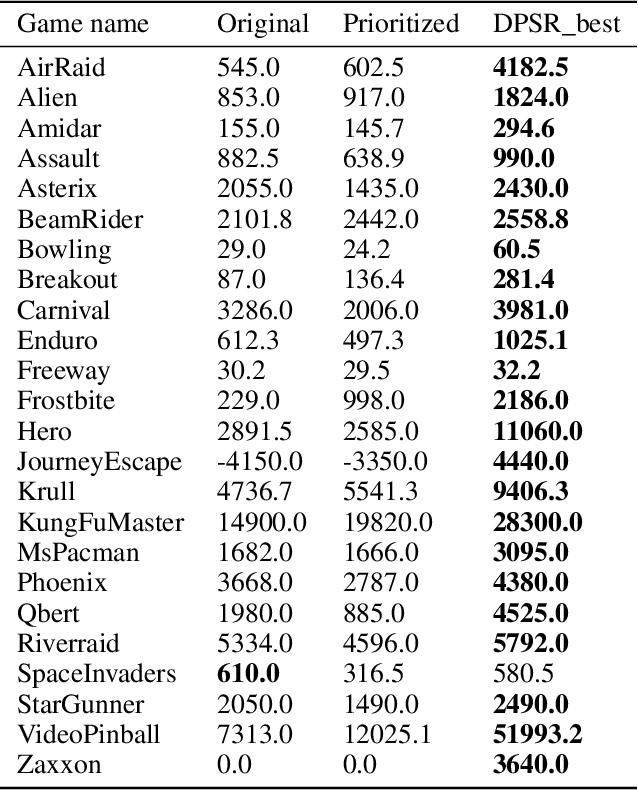
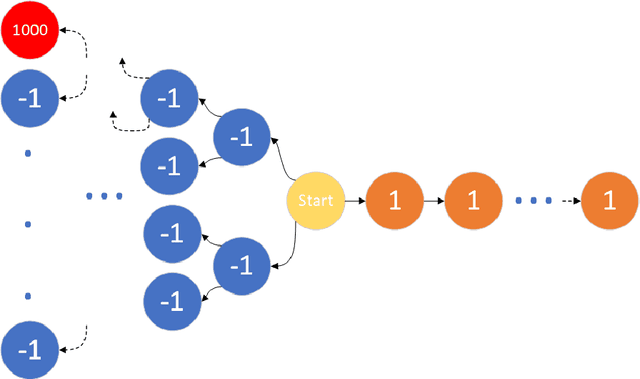

Experience replay enables online reinforcement learning agents to store and reuse the experiences generated in previous interaction with the environment. In the original method, the experiences are sampled and replayed to train the Q-network at the same possibility, i.e. uniformly. In prior work, a method called prioritized experience replay was developed where experiences in the memory are prioritized, so as to replay experiences which seem to be more important in higher frequencies for training the Q-network more efficiently. In this paper, we develop a method called double-prioritized state-recycled (DPSR) experience replay, prioritizing the experience both for training stage and storing stage, as well as replacing the experiences in the memory with state recycling to make the best of experiences which seem to have low priorities temporarily. We use this method in Deep Q-Networks (DQN), and achieve a state-of-the-art result, outperforming the original method and prioritized experience replay on many Atari games.