 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Network Symmetrisation in Concrete Settings
Dec 12, 2024Cornish (2024) recently gave a general theory of neural network symmetrisation in the abstract context of Markov categories. We give a high-level overview of these results, and their concrete implications for the symmetrisation of deterministic functions and of Markov kernels.
SymDiff: Equivariant Diffusion via Stochastic Symmetrisation
Oct 08, 2024



We propose SymDiff, a novel method for constructing equivariant diffusion models using the recently introduced framework of stochastic symmetrisation. SymDiff resembles a learned data augmentation that is deployed at sampling time, and is lightweight, computationally efficient, and easy to implement on top of arbitrary off-the-shelf models. Notably, in contrast to previous work, SymDiff typically does not require any neural network components that are intrinsically equivariant, avoiding the need for complex parameterizations and the use of higher-order geometric features. Instead, our method can leverage highly scalable modern architectures as drop-in replacements for these more constrained alternatives. We show that this additional flexibility yields significant empirical benefit on $\mathrm{E}(3)$-equivariant molecular generation. To the best of our knowledge, this is the first application of symmetrisation to generative modelling, suggesting its potential in this domain more generally.
Stochastic Neural Network Symmetrisation in Markov Categories
Jun 17, 2024We consider the problem of symmetrising a neural network along a group homomorphism: given a homomorphism $\varphi : H \to G$, we would like a procedure that converts $H$-equivariant neural networks into $G$-equivariant ones. We formulate this in terms of Markov categories, which allows us to consider neural networks whose outputs may be stochastic, but with measure-theoretic details abstracted away. We obtain a flexible, compositional, and generic framework for symmetrisation that relies on minimal assumptions about the structure of the group and the underlying neural network architecture. Our approach recovers existing methods for deterministic symmetrisation as special cases, and extends directly to provide a novel methodology for stochastic symmetrisation also. Beyond this, we believe our findings also demonstrate the utility of Markov categories for addressing problems in machine learning in a conceptual yet mathematically rigorous way.
Marginal Density Ratio for Off-Policy Evaluation in Contextual Bandits
Dec 03, 2023



Off-Policy Evaluation (OPE) in contextual bandits is crucial for assessing new policies using existing data without costly experimentation. However, current OPE methods, such as Inverse Probability Weighting (IPW) and Doubly Robust (DR) estimators, suffer from high variance, particularly in cases of low overlap between target and behavior policies or large action and context spaces. In this paper, we introduce a new OPE estimator for contextual bandits, the Marginal Ratio (MR) estimator, which focuses on the shift in the marginal distribution of outcomes $Y$ instead of the policies themselves. Through rigorous theoretical analysis, we demonstrate the benefits of the MR estimator compared to conventional methods like IPW and DR in terms of variance reduction. Additionally, we establish a connection between the MR estimator and the state-of-the-art Marginalized Inverse Propensity Score (MIPS) estimator, proving that MR achieves lower variance among a generalized family of MIPS estimators. We further illustrate the utility of the MR estimator in causal inference settings, where it exhibits enhanced performance in estimating Average Treatment Effects (ATE). Our experiments on synthetic and real-world datasets corroborate our theoretical findings and highlight the practical advantages of the MR estimator in OPE for contextual bandits.
Causal Falsification of Digital Twins
Jan 19, 2023Digital twins hold substantial promise in many applications, but rigorous procedures for assessing their accuracy are essential for their widespread deployment in safety-critical settings. By formulating this task within the framework of causal inference, we show it is not possible to certify that a twin is "correct" using real-world observational data unless potentially tenuous assumptions are made about the data-generating process. To avoid these assumptions, we propose an assessment strategy that instead aims to find cases where the twin is not correct, and present a general-purpose statistical procedure for doing so that may be used across a wide variety of applications and twin models. Our approach yields reliable and actionable information about the twin under only the assumption of an i.i.d. dataset of real-world observations, and in particular remains sound even in the presence of arbitrary unmeasured confounding. We demonstrate the effectiveness of our methodology via a large-scale case study involving sepsis modelling within the Pulse Physiology Engine, which we assess using the MIMIC-III dataset of ICU patients.
Conformal Off-Policy Prediction in Contextual Bandits
Jun 09, 2022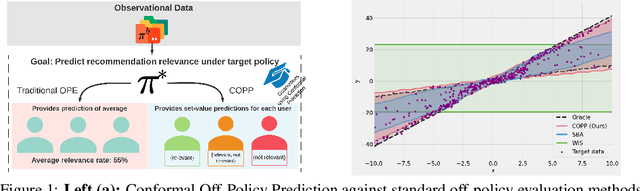

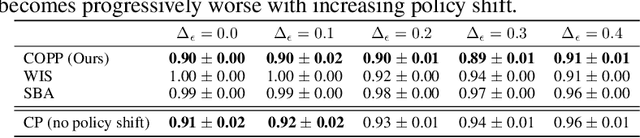
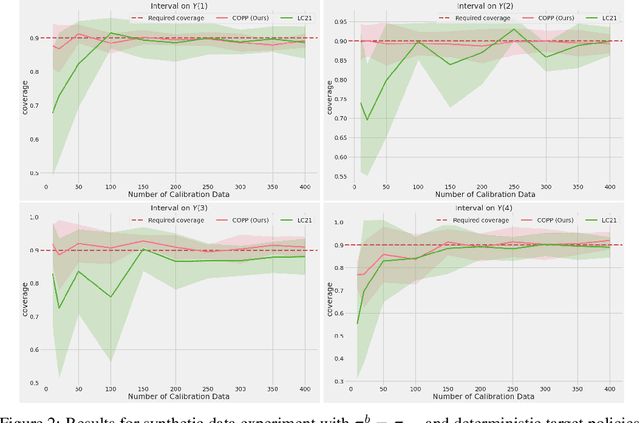
Most off-policy evaluation methods for contextual bandits have focused on the expected outcome of a policy, which is estimated via methods that at best provide only asymptotic guarantees. However, in many applications, the expectation may not be the best measure of performance as it does not capture the variability of the outcome. In addition, particularly in safety-critical settings, stronger guarantees than asymptotic correctness may be required. To address these limitations, we consider a novel application of conformal prediction to contextual bandits. Given data collected under a behavioral policy, we propose \emph{conformal off-policy prediction} (COPP), which can output reliable predictive intervals for the outcome under a new target policy. We provide theoretical finite-sample guarantees without making any additional assumptions beyond the standard contextual bandit setup, and empirically demonstrate the utility of COPP compared with existing methods on synthetic and real-world data.
Deep Generative Pattern-Set Mixture Models for Nonignorable Missingness
Mar 05, 2021

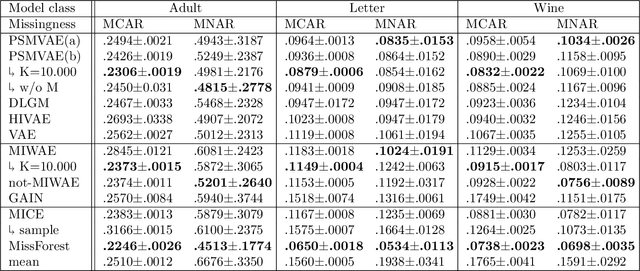

We propose a variational autoencoder architecture to model both ignorable and nonignorable missing data using pattern-set mixtures as proposed by Little (1993). Our model explicitly learns to cluster the missing data into missingness pattern sets based on the observed data and missingness masks. Underpinning our approach is the assumption that the data distribution under missingness is probabilistically semi-supervised by samples from the observed data distribution. Our setup trades off the characteristics of ignorable and nonignorable missingness and can thus be applied to data of both types. We evaluate our method on a wide range of data sets with different types of missingness and achieve state-of-the-art imputation performance. Our model outperforms many common imputation algorithms, especially when the amount of missing data is high and the missingness mechanism is nonignorable.
* International Conference on Artificial Intelligence and Statistics (AISTATS)
Variational Inference with Continuously-Indexed Normalizing Flows
Jul 10, 2020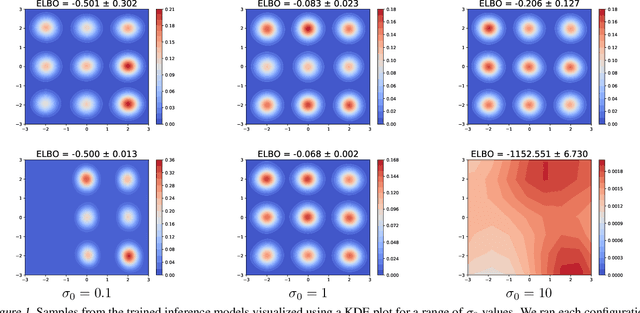
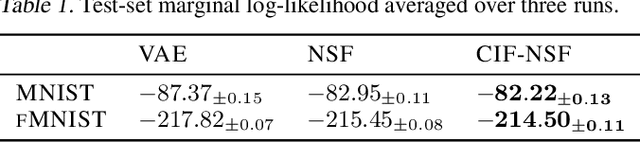

Continuously-indexed flows (CIFs) have recently achieved improvements over baseline normalizing flows in a variety of density estimation tasks. In this paper, we adapt CIFs to the task of variational inference (VI) through the framework of auxiliary VI, and demonstrate that the advantages of CIFs over baseline flows can also translate to the VI setting for both sampling from posteriors with complicated topology and performing maximum likelihood estimation in latent-variable models.
Localised Generative Flows
Sep 30, 2019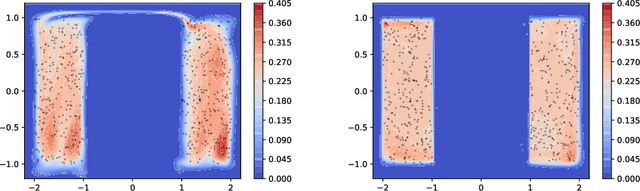

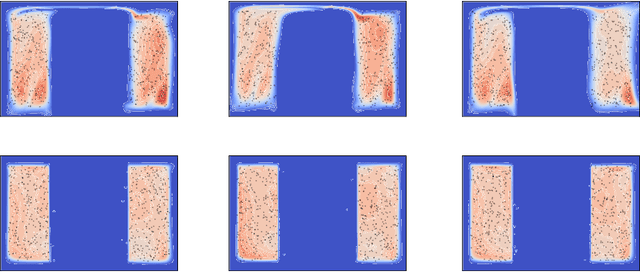
We argue that flow-based density models based on continuous bijections are limited in their ability to learn target distributions with complicated topologies, and propose Localised Generative Flows (LGFs) to address this problem. LGFs are composed of stacked continuous mixtures of bijections, which enables each bijection to learn a local region of the target rather than its entirety. Our method is a generalisation of existing flow-based methods, which can be used without modification as the basis for an LGF model. Unlike normalising flows, LGFs do not permit exact computation of log likelihoods, but we propose a simple variational scheme that performs well in practice. We show empirically that LGFs yield improved performance across a variety of density estimation tasks.