 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Quantification and Causal Considerations for Off-Policy Decision Making
Feb 09, 2025Off-policy evaluation (OPE) is a critical challenge in robust decision-making that seeks to assess the performance of a new policy using data collected under a different policy. However, the existing OPE methodologies suffer from several limitations arising from statistical uncertainty as well as causal considerations. In this thesis, we address these limitations by presenting three different works. Firstly, we consider the problem of high variance in the importance-sampling-based OPE estimators. We introduce the Marginal Ratio (MR) estimator, a novel OPE method that reduces variance by focusing on the marginal distribution of outcomes rather than direct policy shifts, improving robustness in contextual bandits. Next, we propose Conformal Off-Policy Prediction (COPP), a principled approach for uncertainty quantification in OPE that provides finite-sample predictive intervals, ensuring robust decision-making in risk-sensitive applications. Finally, we address causal unidentifiability in off-policy decision-making by developing novel bounds for sequential decision settings, which remain valid under arbitrary unmeasured confounding. We apply these bounds to assess the reliability of digital twin models, introducing a falsification framework to identify scenarios where model predictions diverge from real-world behaviour. Our contributions provide new insights into robust decision-making under uncertainty and establish principled methods for evaluating policies in both static and dynamic settings.
Understanding Chain-of-Thought in LLMs through Information Theory
Nov 18, 2024Large Language Models (LLMs) have shown impressive performance in complex reasoning tasks through Chain-of-Thought (CoT) reasoning, allowing models to break down problems into manageable sub-tasks. However, existing CoT evaluation techniques either require annotated CoT data or fall short in accurately assessing intermediate reasoning steps, leading to high rates of false positives. In this paper, we formalize CoT reasoning in LLMs through an information-theoretic lens. Specifically, our framework quantifies the `information gain' at each reasoning step, enabling the identification of failure modes in LLMs without the need for expensive annotated datasets. We demonstrate the efficacy of our approach through extensive experiments on toy and GSM-8K data, where it significantly outperforms existing outcome-based methods by providing more accurate insights into model performance on individual tasks.
Dataset Fairness: Achievable Fairness on Your Data With Utility Guarantees
Feb 27, 2024



In machine learning fairness, training models which minimize disparity across different sensitive groups often leads to diminished accuracy, a phenomenon known as the fairness-accuracy trade-off. The severity of this trade-off fundamentally depends on dataset characteristics such as dataset imbalances or biases. Therefore using a uniform fairness requirement across datasets remains questionable and can often lead to models with substantially low utility. To address this, we present a computationally efficient approach to approximate the fairness-accuracy trade-off curve tailored to individual datasets, backed by rigorous statistical guarantees. By utilizing the You-Only-Train-Once (YOTO) framework, our approach mitigates the computational burden of having to train multiple models when approximating the trade-off curve. Moreover, we quantify the uncertainty in our approximation by introducing confidence intervals around this curve, offering a statistically grounded perspective on the acceptable range of fairness violations for any given accuracy threshold. Our empirical evaluation spanning tabular, image and language datasets underscores that our approach provides practitioners with a principled framework for dataset-specific fairness decisions across various data modalities.
Marginal Density Ratio for Off-Policy Evaluation in Contextual Bandits
Dec 03, 2023



Off-Policy Evaluation (OPE) in contextual bandits is crucial for assessing new policies using existing data without costly experimentation. However, current OPE methods, such as Inverse Probability Weighting (IPW) and Doubly Robust (DR) estimators, suffer from high variance, particularly in cases of low overlap between target and behavior policies or large action and context spaces. In this paper, we introduce a new OPE estimator for contextual bandits, the Marginal Ratio (MR) estimator, which focuses on the shift in the marginal distribution of outcomes $Y$ instead of the policies themselves. Through rigorous theoretical analysis, we demonstrate the benefits of the MR estimator compared to conventional methods like IPW and DR in terms of variance reduction. Additionally, we establish a connection between the MR estimator and the state-of-the-art Marginalized Inverse Propensity Score (MIPS) estimator, proving that MR achieves lower variance among a generalized family of MIPS estimators. We further illustrate the utility of the MR estimator in causal inference settings, where it exhibits enhanced performance in estimating Average Treatment Effects (ATE). Our experiments on synthetic and real-world datasets corroborate our theoretical findings and highlight the practical advantages of the MR estimator in OPE for contextual bandits.
Trustworthy LLMs: a Survey and Guideline for Evaluating Large Language Models' Alignment
Aug 10, 2023



Ensuring alignment, which refers to making models behave in accordance with human intentions [1,2], has become a critical task before deploying large language models (LLMs) in real-world applications. For instance, OpenAI devoted six months to iteratively aligning GPT-4 before its release [3]. However, a major challenge faced by practitioners is the lack of clear guidance on evaluating whether LLM outputs align with social norms, values, and regulations. This obstacle hinders systematic iteration and deployment of LLMs. To address this issue, this paper presents a comprehensive survey of key dimensions that are crucial to consider when assessing LLM trustworthiness. The survey covers seven major categories of LLM trustworthiness: reliability, safety, fairness, resistance to misuse, explainability and reasoning, adherence to social norms, and robustness. Each major category is further divided into several sub-categories, resulting in a total of 29 sub-categories. Additionally, a subset of 8 sub-categories is selected for further investigation, where corresponding measurement studies are designed and conducted on several widely-used LLMs. The measurement results indicate that, in general, more aligned models tend to perform better in terms of overall trustworthiness. However, the effectiveness of alignment varies across the different trustworthiness categories considered. This highlights the importance of conducting more fine-grained analyses, testing, and making continuous improvements on LLM alignment. By shedding light on these key dimensions of LLM trustworthiness, this paper aims to provide valuable insights and guidance to practitioners in the field. Understanding and addressing these concerns will be crucial in achieving reliable and ethically sound deployment of LLMs in various applications.
Causal Falsification of Digital Twins
Jan 19, 2023Digital twins hold substantial promise in many applications, but rigorous procedures for assessing their accuracy are essential for their widespread deployment in safety-critical settings. By formulating this task within the framework of causal inference, we show it is not possible to certify that a twin is "correct" using real-world observational data unless potentially tenuous assumptions are made about the data-generating process. To avoid these assumptions, we propose an assessment strategy that instead aims to find cases where the twin is not correct, and present a general-purpose statistical procedure for doing so that may be used across a wide variety of applications and twin models. Our approach yields reliable and actionable information about the twin under only the assumption of an i.i.d. dataset of real-world observations, and in particular remains sound even in the presence of arbitrary unmeasured confounding. We demonstrate the effectiveness of our methodology via a large-scale case study involving sepsis modelling within the Pulse Physiology Engine, which we assess using the MIMIC-III dataset of ICU patients.
Manifold Restricted Interventional Shapley Values
Jan 10, 2023



Shapley values are model-agnostic methods for explaining model predictions. Many commonly used methods of computing Shapley values, known as \emph{off-manifold methods}, rely on model evaluations on out-of-distribution input samples. Consequently, explanations obtained are sensitive to model behaviour outside the data distribution, which may be irrelevant for all practical purposes. While \emph{on-manifold methods} have been proposed which do not suffer from this problem, we show that such methods are overly dependent on the input data distribution, and therefore result in unintuitive and misleading explanations. To circumvent these problems, we propose \emph{ManifoldShap}, which respects the model's domain of validity by restricting model evaluations to the data manifold. We show, theoretically and empirically, that ManifoldShap is robust to off-manifold perturbations of the model and leads to more accurate and intuitive explanations than existing state-of-the-art Shapley methods.
Conformal Off-Policy Prediction in Contextual Bandits
Jun 09, 2022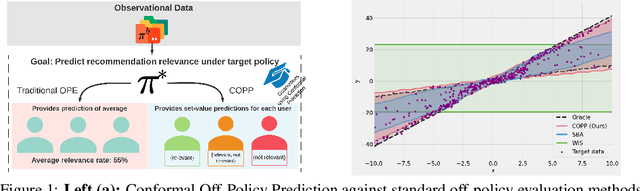

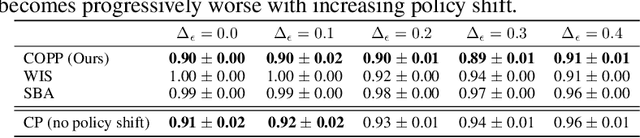
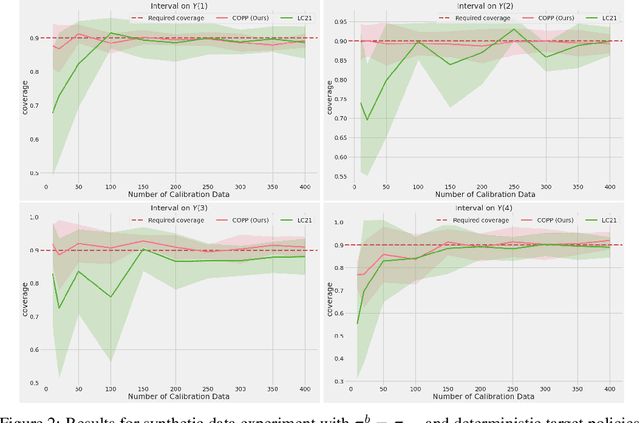
Most off-policy evaluation methods for contextual bandits have focused on the expected outcome of a policy, which is estimated via methods that at best provide only asymptotic guarantees. However, in many applications, the expectation may not be the best measure of performance as it does not capture the variability of the outcome. In addition, particularly in safety-critical settings, stronger guarantees than asymptotic correctness may be required. To address these limitations, we consider a novel application of conformal prediction to contextual bandits. Given data collected under a behavioral policy, we propose \emph{conformal off-policy prediction} (COPP), which can output reliable predictive intervals for the outcome under a new target policy. We provide theoretical finite-sample guarantees without making any additional assumptions beyond the standard contextual bandit setup, and empirically demonstrate the utility of COPP compared with existing methods on synthetic and real-world data.