 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA mean teacher algorithm for unlearning of language models
Apr 18, 2025One of the goals of language model unlearning is to reduce memorization of selected text instances while retaining the model's general abilities. Despite various proposed methods, reducing memorization of large datasets without noticeable degradation in model utility remains challenging. In this paper, we investigate the mean teacher algorithm (Tarvainen & Valpola, 2017), a simple proximal optimization method from continual learning literature that gradually modifies the teacher model. We show that the mean teacher can approximate a trajectory of a slow natural gradient descent (NGD), which inherently seeks low-curvature updates that are less likely to degrade the model utility. While slow NGD can suffer from vanishing gradients, we introduce a new unlearning loss called "negative log-unlikelihood" (NLUL) that avoids this problem. We show that the combination of mean teacher and NLUL improves some metrics on the MUSE benchmarks (Shi et al., 2024).
Revisiting inverse Hessian vector products for calculating influence functions
Sep 25, 2024
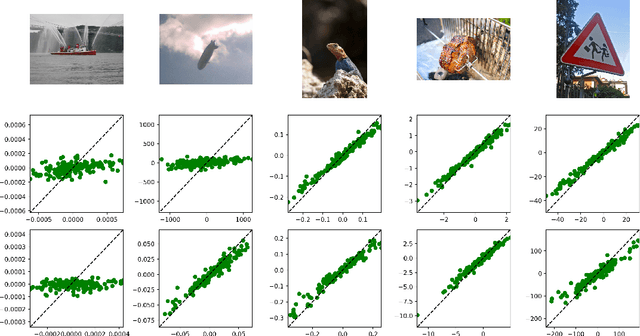
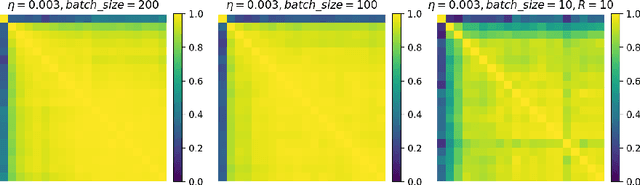

Influence functions are a popular tool for attributing a model's output to training data. The traditional approach relies on the calculation of inverse Hessian-vector products (iHVP), but the classical solver "Linear time Stochastic Second-order Algorithm" (LiSSA, Agarwal et al. (2017)) is often deemed impractical for large models due to expensive computation and hyperparameter tuning. We show that the three hyperparameters -- the scaling factor, the batch size, and the number of steps -- can be chosen depending on the spectral properties of the Hessian, particularly its trace and largest eigenvalue. By evaluating with random sketching (Swartworth and Woodruff, 2023), we find that the batch size has to be sufficiently large for LiSSA to converge; however, for all of the models we consider, the requirement is mild. We confirm our findings empirically by comparing to Proximal Bregman Retraining Functions (PBRF, Bae et al. (2022)). Finally, we discuss what role the inverse Hessian plays in calculating the influence.
Deep Concept Removal
Oct 09, 2023



We address the problem of concept removal in deep neural networks, aiming to learn representations that do not encode certain specified concepts (e.g., gender etc.) We propose a novel method based on adversarial linear classifiers trained on a concept dataset, which helps to remove the targeted attribute while maintaining model performance. Our approach Deep Concept Removal incorporates adversarial probing classifiers at various layers of the network, effectively addressing concept entanglement and improving out-of-distribution generalization. We also introduce an implicit gradient-based technique to tackle the challenges associated with adversarial training using linear classifiers. We evaluate the ability to remove a concept on a set of popular distributionally robust optimization (DRO) benchmarks with spurious correlations, as well as out-of-distribution (OOD) generalization tasks.
Post-hoc Bias Scoring Is Optimal For Fair Classification
Oct 09, 2023
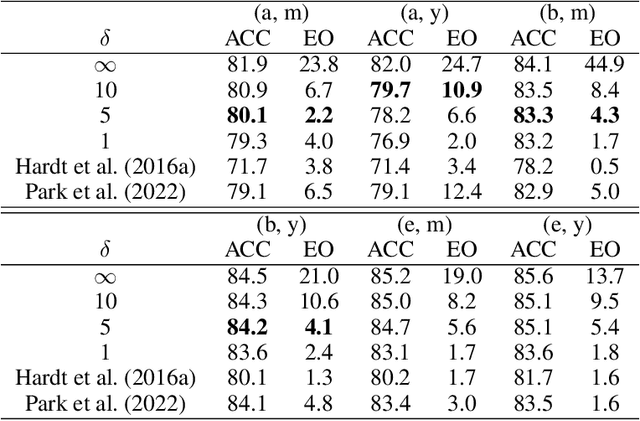

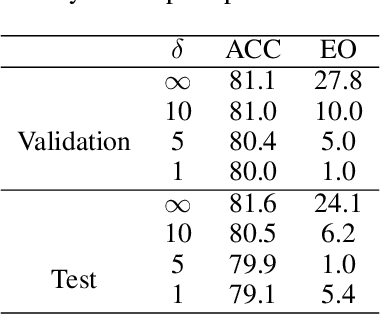
We consider a binary classification problem under group fairness constraints, which can be one of Demographic Parity (DP), Equalized Opportunity (EOp), or Equalized Odds (EO). We propose an explicit characterization of Bayes optimal classifier under the fairness constraints, which turns out to be a simple modification rule of the unconstrained classifier. Namely, we introduce a novel instance-level measure of bias, which we call bias score, and the modification rule is a simple linear rule on top of the finite amount of bias scores. Based on this characterization, we develop a post-hoc approach that allows us to adapt to fairness constraints while maintaining high accuracy. In the case of DP and EOp constraints, the modification rule is thresholding a single bias score, while in the case of EO constraints we are required to fit a linear modification rule with 2 parameters. The method can also be applied for composite group-fairness criteria, such as ones involving several sensitive attributes. We achieve competitive or better performance compared to both in-processing and post-processing methods across three datasets: Adult, COMPAS, and CelebA. Unlike most post-processing methods, we do not require access to sensitive attributes during the inference time.
Trustworthy LLMs: a Survey and Guideline for Evaluating Large Language Models' Alignment
Aug 10, 2023



Ensuring alignment, which refers to making models behave in accordance with human intentions [1,2], has become a critical task before deploying large language models (LLMs) in real-world applications. For instance, OpenAI devoted six months to iteratively aligning GPT-4 before its release [3]. However, a major challenge faced by practitioners is the lack of clear guidance on evaluating whether LLM outputs align with social norms, values, and regulations. This obstacle hinders systematic iteration and deployment of LLMs. To address this issue, this paper presents a comprehensive survey of key dimensions that are crucial to consider when assessing LLM trustworthiness. The survey covers seven major categories of LLM trustworthiness: reliability, safety, fairness, resistance to misuse, explainability and reasoning, adherence to social norms, and robustness. Each major category is further divided into several sub-categories, resulting in a total of 29 sub-categories. Additionally, a subset of 8 sub-categories is selected for further investigation, where corresponding measurement studies are designed and conducted on several widely-used LLMs. The measurement results indicate that, in general, more aligned models tend to perform better in terms of overall trustworthiness. However, the effectiveness of alignment varies across the different trustworthiness categories considered. This highlights the importance of conducting more fine-grained analyses, testing, and making continuous improvements on LLM alignment. By shedding light on these key dimensions of LLM trustworthiness, this paper aims to provide valuable insights and guidance to practitioners in the field. Understanding and addressing these concerns will be crucial in achieving reliable and ethically sound deployment of LLMs in various applications.
Robustifying Markowitz
Dec 28, 2022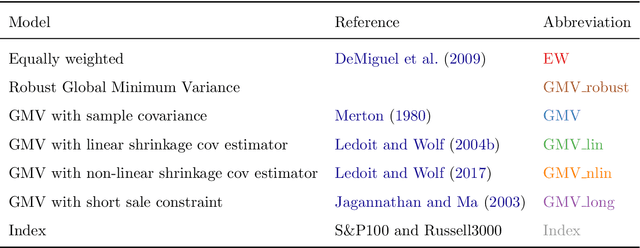
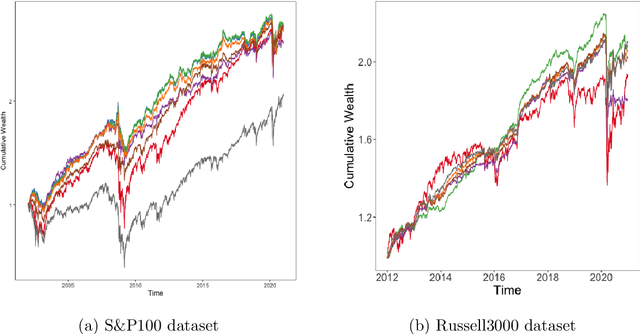
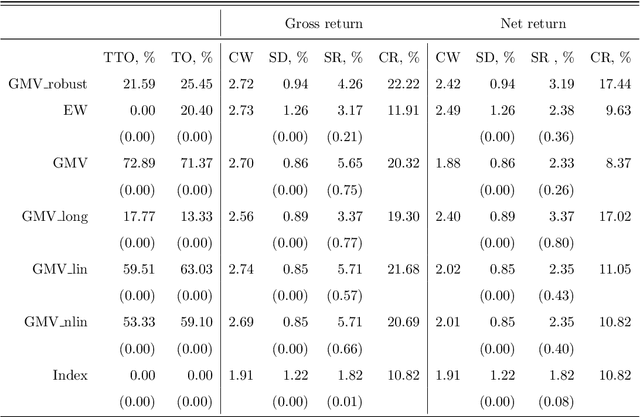
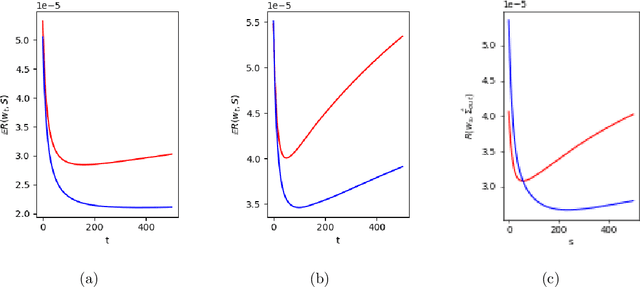
Markowitz mean-variance portfolios with sample mean and covariance as input parameters feature numerous issues in practice. They perform poorly out of sample due to estimation error, they experience extreme weights together with high sensitivity to change in input parameters. The heavy-tail characteristics of financial time series are in fact the cause for these erratic fluctuations of weights that consequently create substantial transaction costs. In robustifying the weights we present a toolbox for stabilizing costs and weights for global minimum Markowitz portfolios. Utilizing a projected gradient descent (PGD) technique, we avoid the estimation and inversion of the covariance operator as a whole and concentrate on robust estimation of the gradient descent increment. Using modern tools of robust statistics we construct a computationally efficient estimator with almost Gaussian properties based on median-of-means uniformly over weights. This robustified Markowitz approach is confirmed by empirical studies on equity markets. We demonstrate that robustified portfolios reach the lowest turnover compared to shrinkage-based and constrained portfolios while preserving or slightly improving out-of-sample performance.
Stability and Deviation Optimal Risk Bounds with Convergence Rate $O(1/n)$
Mar 22, 2021The sharpest known high probability generalization bounds for uniformly stable algorithms (Feldman, Vondr\'{a}k, 2018, 2019), (Bousquet, Klochkov, Zhivotovskiy, 2020) contain a generally inevitable sampling error term of order $\Theta(1/\sqrt{n})$. When applied to excess risk bounds, this leads to suboptimal results in several standard stochastic convex optimization problems. We show that if the so-called Bernstein condition is satisfied, the term $\Theta(1/\sqrt{n})$ can be avoided, and high probability excess risk bounds of order up to $O(1/n)$ are possible via uniform stability. Using this result, we show a high probability excess risk bound with the rate $O(\log n/n)$ for strongly convex and Lipschitz losses valid for \emph{any} empirical risk minimization method. This resolves a question of Shalev-Shwartz, Shamir, Srebro, and Sridharan (2009). We discuss how $O(\log n/n)$ high probability excess risk bounds are possible for projected gradient descent in the case of strongly convex and Lipschitz losses without the usual smoothness assumption.
Robust $k$-means Clustering for Distributions with Two Moments
Feb 06, 2020We consider the robust algorithms for the $k$-means clustering problem where a quantizer is constructed based on $N$ independent observations. Our main results are median of means based non-asymptotic excess distortion bounds that hold under the two bounded moments assumption in a general separable Hilbert space. In particular, our results extend the renowned asymptotic result of Pollard, 1981 who showed that the existence of two moments is sufficient for strong consistency of an empirically optimal quantizer in $\mathbb{R}^d$. In a special case of clustering in $\mathbb{R}^d$, under two bounded moments, we prove matching (up to constant factors) non-asymptotic upper and lower bounds on the excess distortion, which depend on the probability mass of the lightest cluster of an optimal quantizer. Our bounds have the sub-Gaussian form, and the proofs are based on the versions of uniform bounds for robust mean estimators.
Sharper bounds for uniformly stable algorithms
Oct 17, 2019The generalization bounds for stable algorithms is a classical question in learning theory taking its roots in the early works of Vapnik and Chervonenkis and Rogers and Wagner. In a series of recent breakthrough papers, Feldman and Vondrak have shown that the best known high probability upper bounds for uniformly stable learning algorithms due to Bousquet and Elisseeff are sub-optimal in some natural regimes. To do so, they proved two generalization bounds that significantly outperform the original generalization bound. Feldman and Vondrak also asked if it is possible to provide sharper bounds and prove corresponding high probability lower bounds. This paper is devoted to these questions: firstly, inspired by the original arguments of, we provide a short proof of the moment bound that implies the generalization bound stronger than both recent results. Secondly, we prove general lower bounds, showing that our moment bound is sharp (up to a logarithmic factor) unless some additional properties of the corresponding random variables are used. Our main probabilistic result is a general concentration inequality for weakly correlated random variables, which may be of independent interest.