 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebating for Better Reasoning: An Unsupervised Multimodal Approach
May 20, 2025As Large Language Models (LLMs) gain expertise across diverse domains and modalities, scalable oversight becomes increasingly challenging, particularly when their capabilities may surpass human evaluators. Debate has emerged as a promising mechanism for enabling such oversight. In this work, we extend the debate paradigm to a multimodal setting, exploring its potential for weaker models to supervise and enhance the performance of stronger models. We focus on visual question answering (VQA), where two "sighted" expert vision-language models debate an answer, while a "blind" (text-only) judge adjudicates based solely on the quality of the arguments. In our framework, the experts defend only answers aligned with their beliefs, thereby obviating the need for explicit role-playing and concentrating the debate on instances of expert disagreement. Experiments on several multimodal tasks demonstrate that the debate framework consistently outperforms individual expert models. Moreover, judgments from weaker LLMs can help instill reasoning capabilities in vision-language models through finetuning.
MCPDial: A Minecraft Persona-driven Dialogue Dataset
Oct 29, 2024We propose a novel approach that uses large language models (LLMs) to generate persona-driven conversations between Players and Non-Player Characters (NPC) in games. Showcasing the application of our methodology, we introduce the Minecraft Persona-driven Dialogue dataset (MCPDial). Starting with a small seed of expert-written conversations, we employ our method to generate hundreds of additional conversations. Each conversation in the dataset includes rich character descriptions of the player and NPC. The conversations are long, allowing for in-depth and extensive interactions between the player and NPC. MCPDial extends beyond basic conversations by incorporating canonical function calls (e.g. "Call find a resource on iron ore") between the utterances. Finally, we conduct a qualitative analysis of the dataset to assess its quality and characteristics.
Learning Dynamic Knowledge Graphs to Generalize on Text-Based Games
Feb 21, 2020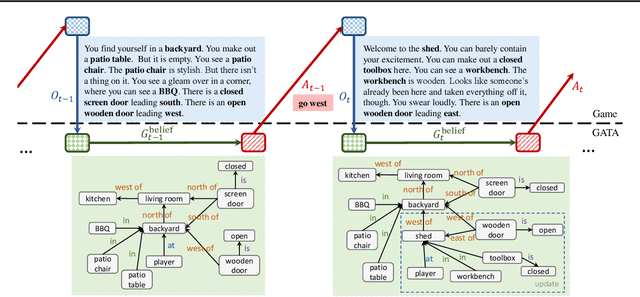

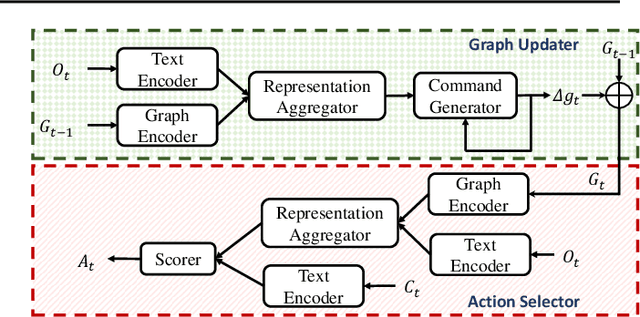
Playing text-based games requires skill in processing natural language and in planning. Although a key goal for agents solving this task is to generalize across multiple games, most previous work has either focused on solving a single game or has tackled generalization with rule-based heuristics. In this work, we investigate how structured information in the form of a knowledge graph (KG) can facilitate effective planning and generalization. We introduce a novel transformer-based sequence-to-sequence model that constructs a "belief" KG from raw text observations of the environment, dynamically updating this belief graph at every game step as it receives new observations. To train this model to build useful graph representations, we introduce and analyze a set of graph-related pre-training tasks. We demonstrate empirically that KG-based representations from our model help agents to converge faster to better policies for multiple text-based games, and further, enable stronger zero-shot performance on unseen games. Experiments on unseen games show that our best agent outperforms text-based baselines by 21.6%.
DocBERT: BERT for Document Classification
Apr 17, 2019
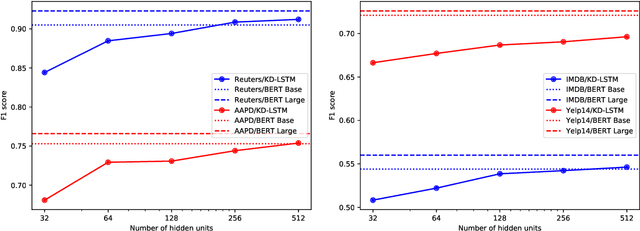
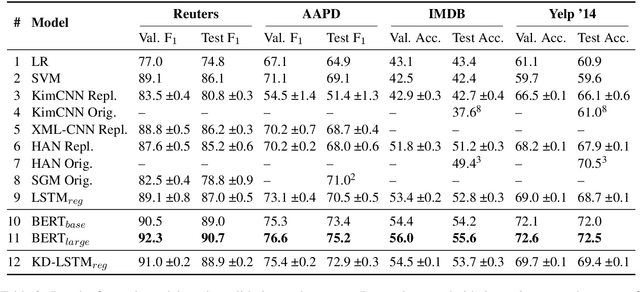
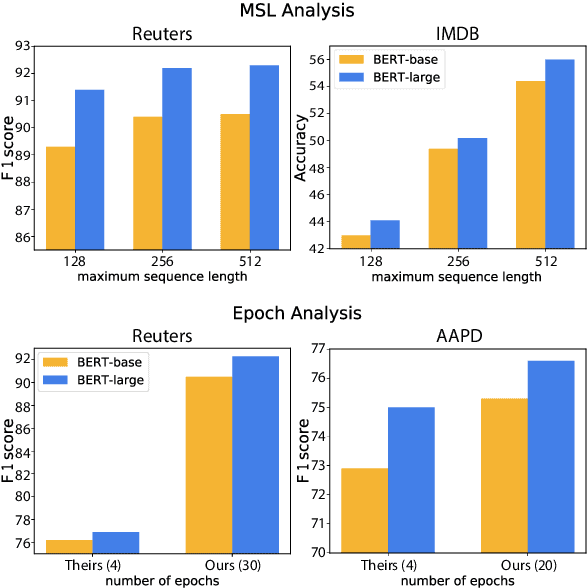
Pre-trained language representation models achieve remarkable state of the art across a wide range of tasks in natural language processing. One of the latest advancements is BERT, a deep pre-trained transformer that yields much better results than its predecessors do. Despite its burgeoning popularity, however, BERT has not yet been applied to document classification. This task deserves attention, since it contains a few nuances: first, modeling syntactic structure matters less for document classification than for other problems, such as natural language inference and sentiment classification. Second, documents often have multiple labels across dozens of classes, which is uncharacteristic of the tasks that BERT explores. In this paper, we describe fine-tuning BERT for document classification. We are the first to demonstrate the success of BERT on this task, achieving state of the art across four popular datasets.
FLOPs as a Direct Optimization Objective for Learning Sparse Neural Networks
Nov 23, 2018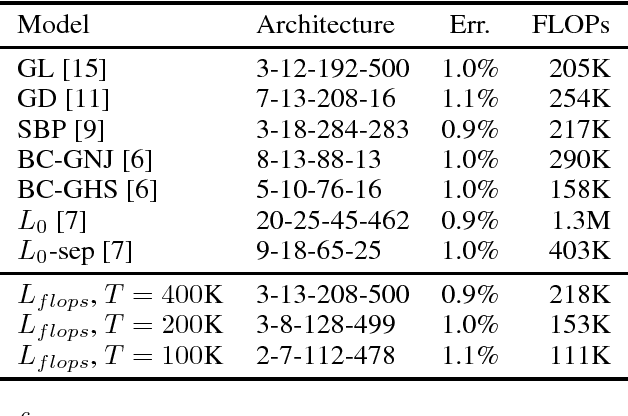

There exists a plethora of techniques for inducing structured sparsity in parametric models during the optimization process, with the final goal of resource-efficient inference. However, few methods target a specific number of floating-point operations (FLOPs) as part of the optimization objective, despite many reporting FLOPs as part of the results. Furthermore, a one-size-fits-all approach ignores realistic system constraints, which differ significantly between, say, a GPU and a mobile phone -- FLOPs on the former incur less latency than on the latter; thus, it is important for practitioners to be able to specify a target number of FLOPs during model compression. In this work, we extend a state-of-the-art technique to directly incorporate FLOPs as part of the optimization objective and show that, given a desired FLOPs requirement, different neural networks can be successfully trained for image classification.