 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Token and Path-based Representations of Code for Identifying Security-Relevant Commits
Nov 15, 2019
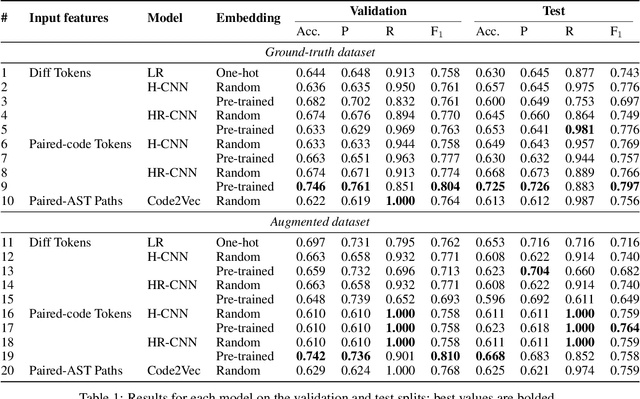
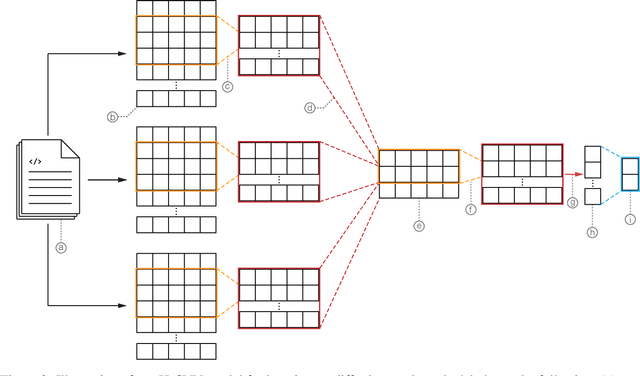
Public vulnerability databases such as CVE and NVD account for only 60% of security vulnerabilities present in open-source projects, and are known to suffer from inconsistent quality. Over the last two years, there has been considerable growth in the number of known vulnerabilities across projects available in various repositories such as NPM and Maven Central. Such an increasing risk calls for a mechanism to infer the presence of security threats in a timely manner. We propose novel hierarchical deep learning models for the identification of security-relevant commits from either the commit diff or the source code for the Java classes. By comparing the performance of our model against code2vec, a state-of-the-art model that learns from path-based representations of code, and a logistic regression baseline, we show that deep learning models show promising results in identifying security-related commits. We also conduct a comparative analysis of how various deep learning models learn across different input representations and the effect of regularization on the generalization of our models.
DocBERT: BERT for Document Classification
Apr 17, 2019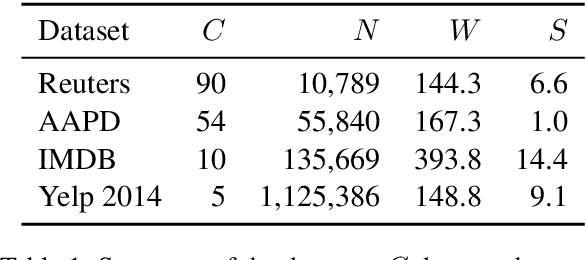
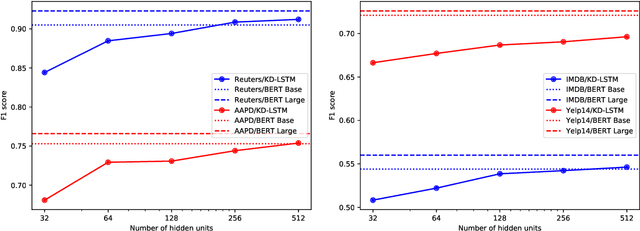
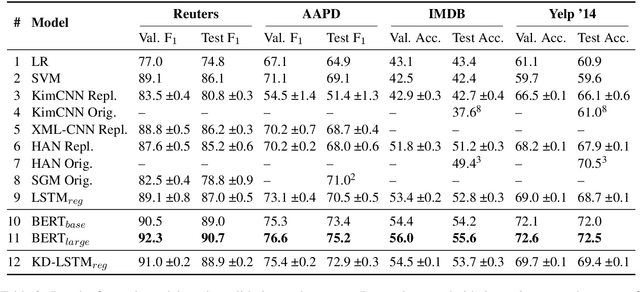
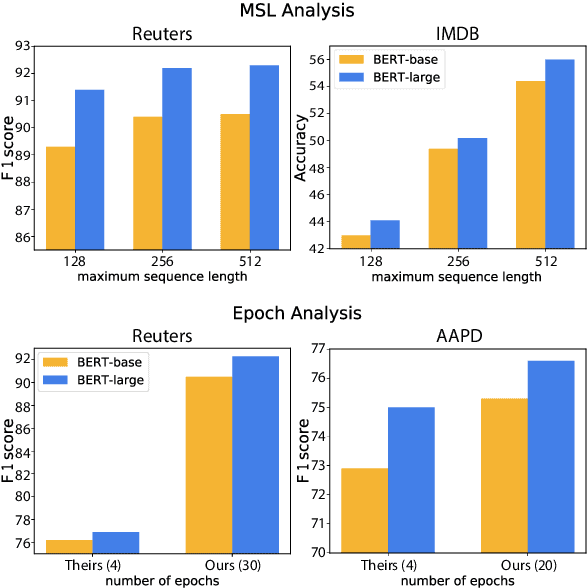
Pre-trained language representation models achieve remarkable state of the art across a wide range of tasks in natural language processing. One of the latest advancements is BERT, a deep pre-trained transformer that yields much better results than its predecessors do. Despite its burgeoning popularity, however, BERT has not yet been applied to document classification. This task deserves attention, since it contains a few nuances: first, modeling syntactic structure matters less for document classification than for other problems, such as natural language inference and sentiment classification. Second, documents often have multiple labels across dozens of classes, which is uncharacteristic of the tasks that BERT explores. In this paper, we describe fine-tuning BERT for document classification. We are the first to demonstrate the success of BERT on this task, achieving state of the art across four popular datasets.
Supervised Sentiment Classification with CNNs for Diverse SE Datasets
Dec 23, 2018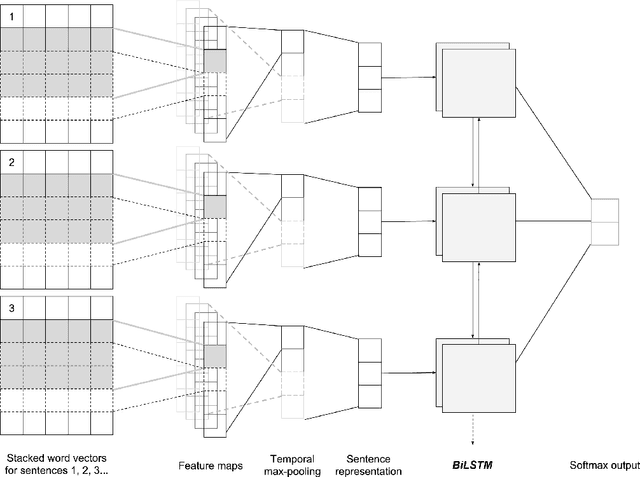
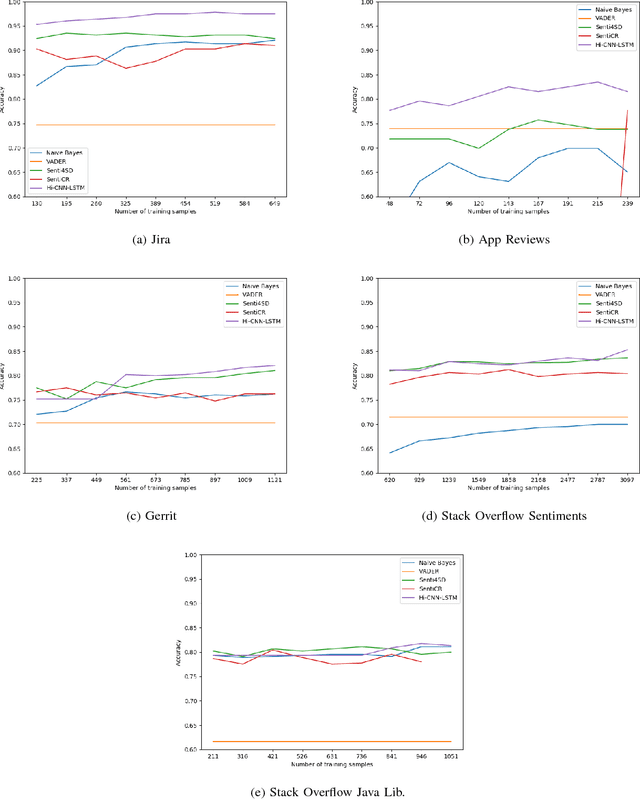
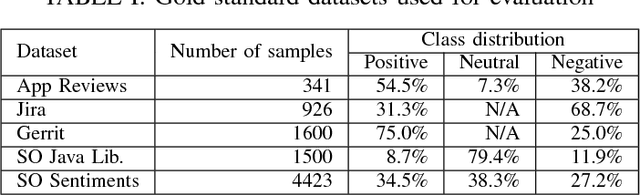
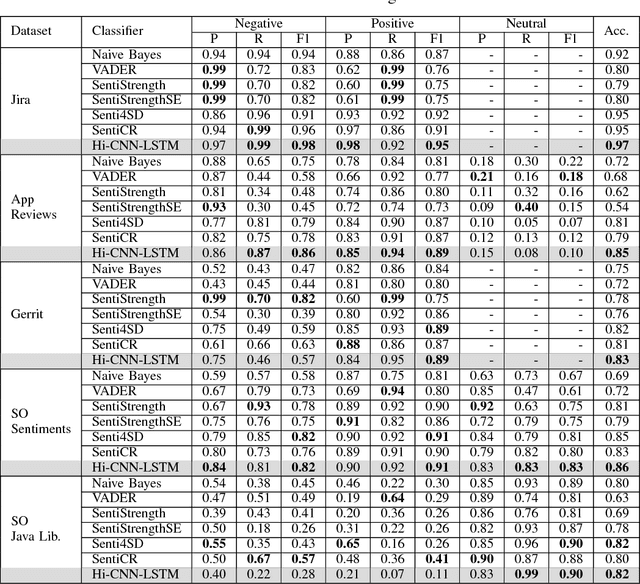
Sentiment analysis, a popular technique for opinion mining, has been used by the software engineering research community for tasks such as assessing app reviews, developer emotions in issue trackers and developer opinions on APIs. Past research indicates that state-of-the-art sentiment analysis techniques have poor performance on SE data. This is because sentiment analysis tools are often designed to work on non-technical documents such as movie reviews. In this study, we attempt to solve the issues with existing sentiment analysis techniques for SE texts by proposing a hierarchical model based on convolutional neural networks (CNN) and long short-term memory (LSTM) trained on top of pre-trained word vectors. We assessed our model's performance and reliability by comparing it with a number of frequently used sentiment analysis tools on five gold standard datasets. Our results show that our model pushes the state of the art further on all datasets in terms of accuracy. We also show that it is possible to get better accuracy after labelling a small sample of the dataset and re-training our model rather than using an unsupervised classifier.