 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Security Fixes in Open-Source Repositories using Static Code Analyzers
May 07, 2021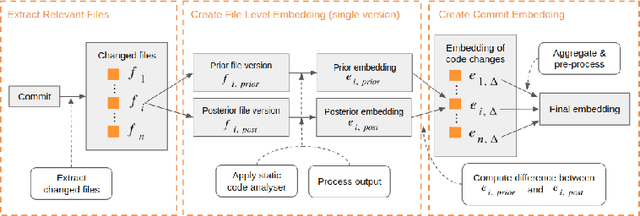
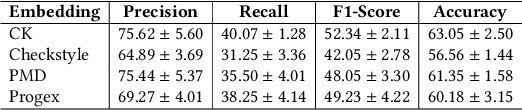
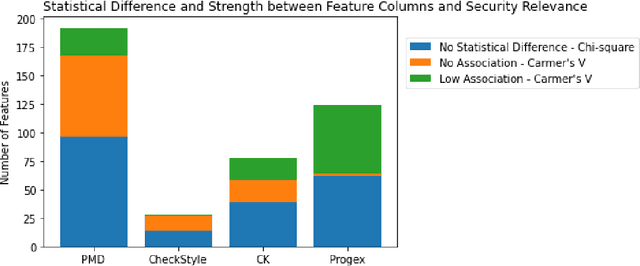
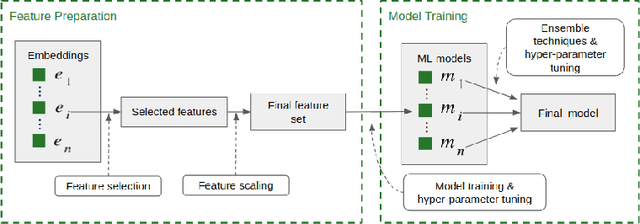
The sources of reliable, code-level information about vulnerabilities that affect open-source software (OSS) are scarce, which hinders a broad adoption of advanced tools that provide code-level detection and assessment of vulnerable OSS dependencies. In this paper, we study the extent to which the output of off-the-shelf static code analyzers can be used as a source of features to represent commits in Machine Learning (ML) applications. In particular, we investigate how such features can be used to construct embeddings and train ML models to automatically identify source code commits that contain vulnerability fixes. We analyze such embeddings for security-relevant and non-security-relevant commits, and we show that, although in isolation they are not different in a statistically significant manner, it is possible to use them to construct a ML pipeline that achieves results comparable with the state of the art. We also found that the combination of our method with commit2vec represents a tangible improvement over the state of the art in the automatic identification of commits that fix vulnerabilities: the ML models we construct and commit2vec are complementary, the former being more generally applicable, albeit not as accurate.
Automated Mapping of Vulnerability Advisories onto their Fix Commits in Open Source Repositories
Mar 24, 2021
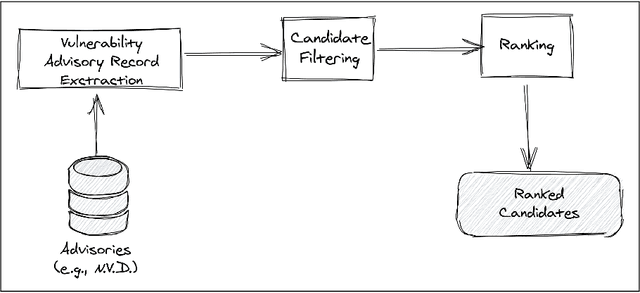

The lack of comprehensive sources of accurate vulnerability data represents a critical obstacle to studying and understanding software vulnerabilities (and their corrections). In this paper, we present an approach that combines heuristics stemming from practical experience and machine-learning (ML) - specifically, natural language processing (NLP) - to address this problem. Our method consists of three phases. First, an advisory record containing key information about a vulnerability is extracted from an advisory (expressed in natural language). Second, using heuristics, a subset of candidate fix commits is obtained from the source code repository of the affected project by filtering out commits that are known to be irrelevant for the task at hand. Finally, for each such candidate commit, our method builds a numerical feature vector reflecting the characteristics of the commit that are relevant to predicting its match with the advisory at hand. The feature vectors are then exploited for building a final ranked list of candidate fixing commits. The score attributed by the ML model to each feature is kept visible to the users, allowing them to interpret of the predictions. We evaluated our approach using a prototype implementation named Prospector on a manually curated data set that comprises 2,391 known fix commits corresponding to 1,248 public vulnerability advisories. When considering the top-10 commits in the ranked results, our implementation could successfully identify at least one fix commit for up to 84.03% of the vulnerabilities (with a fix commit on the first position for 65.06% of the vulnerabilities). In conclusion, our method reduces considerably the effort needed to search OSS repositories for the commits that fix known vulnerabilities.
Commit2Vec: Learning Distributed Representations of Code Changes
Nov 20, 2019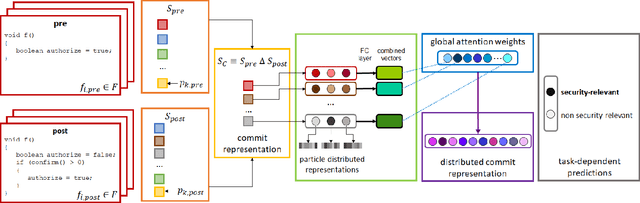

Deep learning methods, which have found successful applications in fields like image classification and natural language processing, have recently been applied to source code analysis too, due to the enormous amount of freely available source code (e.g., from open-source software repositories). In this work, we elaborate upon a state-of-the-art approach to the representation of source code that uses information about its syntactic structure, and we adapt it to represent source changes (i.e., commits). We use this representation to classify security-relevant commits. Because our method uses transfer learning (that is, we train a network on a "pretext task" for which abundant labeled data is available, and then we use such network for the target task of commit classification, for which fewer labeled instances are available), we studied the impact of pre-training the network using two different pretext tasks versus a randomly initialized model. Our results indicate that representations that leverage the structural information obtained through code syntax outperform token-based representations. Furthermore, the performance metrics obtained when pre-training on a loosely related pretext task with a very large dataset ($>10^6$ samples) were surpassed when pretraining on a smaller dataset ($>10^4$ samples) but for a pretext task that is more closely related to the target task.
Exploiting Token and Path-based Representations of Code for Identifying Security-Relevant Commits
Nov 15, 2019
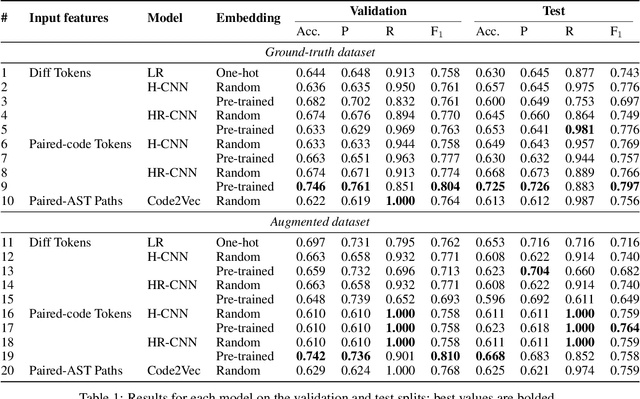
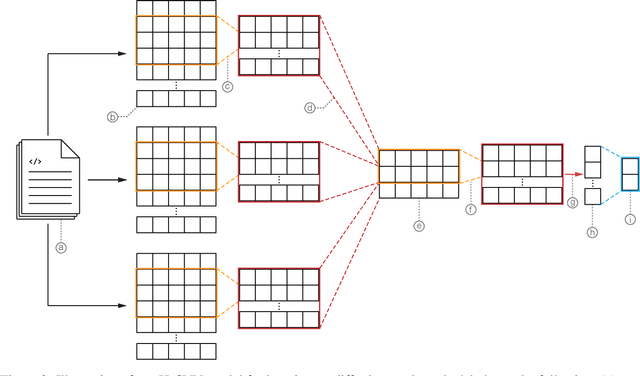
Public vulnerability databases such as CVE and NVD account for only 60% of security vulnerabilities present in open-source projects, and are known to suffer from inconsistent quality. Over the last two years, there has been considerable growth in the number of known vulnerabilities across projects available in various repositories such as NPM and Maven Central. Such an increasing risk calls for a mechanism to infer the presence of security threats in a timely manner. We propose novel hierarchical deep learning models for the identification of security-relevant commits from either the commit diff or the source code for the Java classes. By comparing the performance of our model against code2vec, a state-of-the-art model that learns from path-based representations of code, and a logistic regression baseline, we show that deep learning models show promising results in identifying security-related commits. We also conduct a comparative analysis of how various deep learning models learn across different input representations and the effect of regularization on the generalization of our models.
A Manually-Curated Dataset of Fixes to Vulnerabilities of Open-Source Software
Mar 19, 2019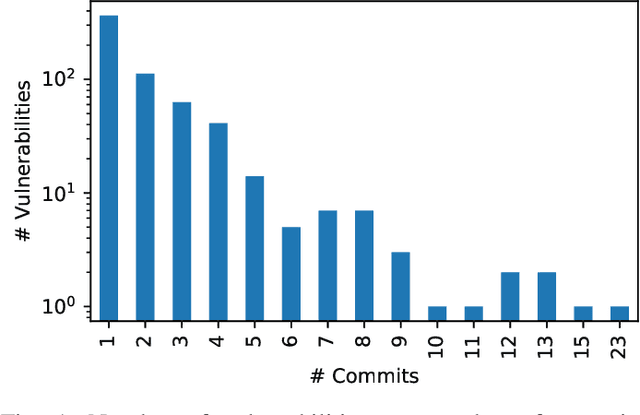

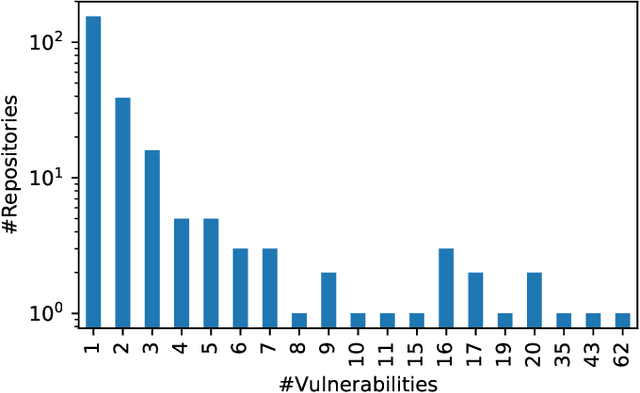
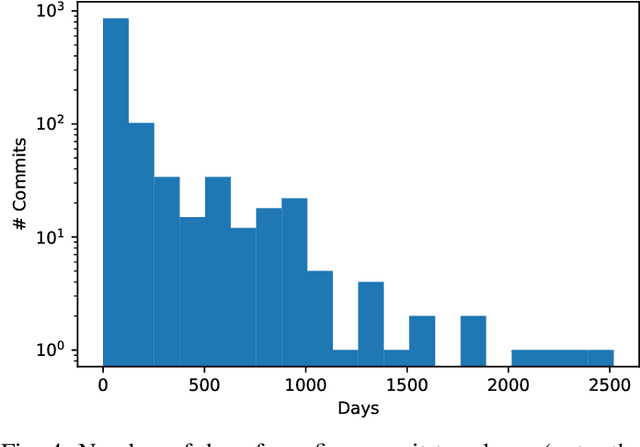
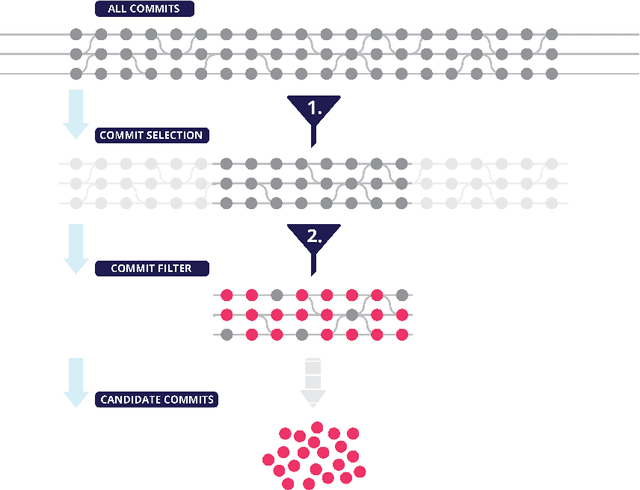
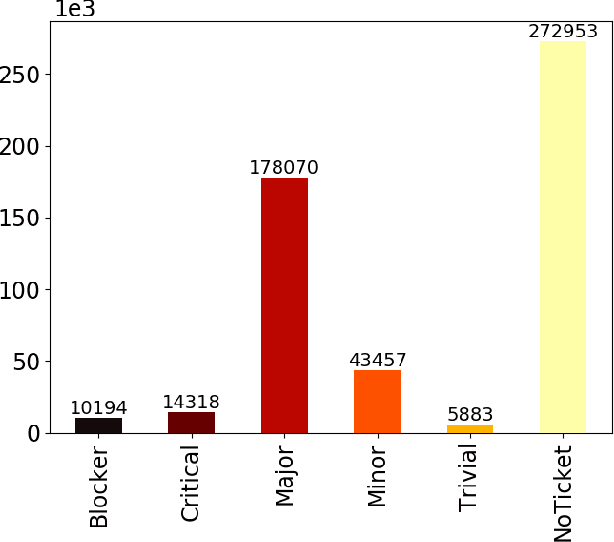
Advancing our understanding of software vulnerabilities, automating their identification, the analysis of their impact, and ultimately their mitigation is necessary to enable the development of software that is more secure. While operating a vulnerability assessment tool that we developed and that is currently used by hundreds of development units at SAP, we manually collected and curated a dataset of vulnerabilities of open-source software and the commits fixing them. The data was obtained both from the National Vulnerability Database (NVD) and from project-specific Web resources that we monitor on a continuous basis. From that data, we extracted a dataset that maps 624 publicly disclosed vulnerabilities affecting 205 distinct open-source Java projects, used in SAP products or internal tools, onto the 1282 commits that fix them. Out of 624 vulnerabilities, 29 do not have a CVE identifier at all and 46, which do have a CVE identifier assigned by a numbering authority, are not available in the NVD yet. The dataset is released under an open-source license, together with supporting scripts that allow researchers to automatically retrieve the actual content of the commits from the corresponding repositories and to augment the attributes available for each instance. Also, these scripts allow to complement the dataset with additional instances that are not security fixes (which is useful, for example, in machine learning applications). Our dataset has been successfully used to train classifiers that could automatically identify security-relevant commits in code repositories. The release of this dataset and the supporting code as open-source will allow future research to be based on data of industrial relevance; also, it represents a concrete step towards making the maintenance of this dataset a shared effort involving open-source communities, academia, and the industry.
* This is a pre-print version of the paper that appears in the proceedings of The 16th International Conference on Mining Software Repositories (MSR), Data Showcase track