 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommit2Vec: Learning Distributed Representations of Code Changes
Nov 20, 2019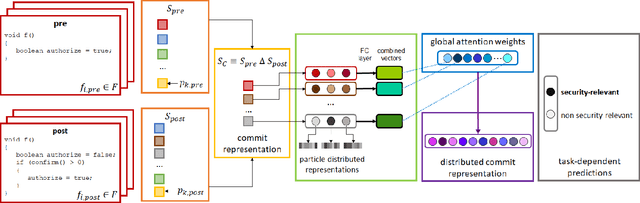

Deep learning methods, which have found successful applications in fields like image classification and natural language processing, have recently been applied to source code analysis too, due to the enormous amount of freely available source code (e.g., from open-source software repositories). In this work, we elaborate upon a state-of-the-art approach to the representation of source code that uses information about its syntactic structure, and we adapt it to represent source changes (i.e., commits). We use this representation to classify security-relevant commits. Because our method uses transfer learning (that is, we train a network on a "pretext task" for which abundant labeled data is available, and then we use such network for the target task of commit classification, for which fewer labeled instances are available), we studied the impact of pre-training the network using two different pretext tasks versus a randomly initialized model. Our results indicate that representations that leverage the structural information obtained through code syntax outperform token-based representations. Furthermore, the performance metrics obtained when pre-training on a loosely related pretext task with a very large dataset ($>10^6$ samples) were surpassed when pretraining on a smaller dataset ($>10^4$ samples) but for a pretext task that is more closely related to the target task.
A Manually-Curated Dataset of Fixes to Vulnerabilities of Open-Source Software
Mar 19, 2019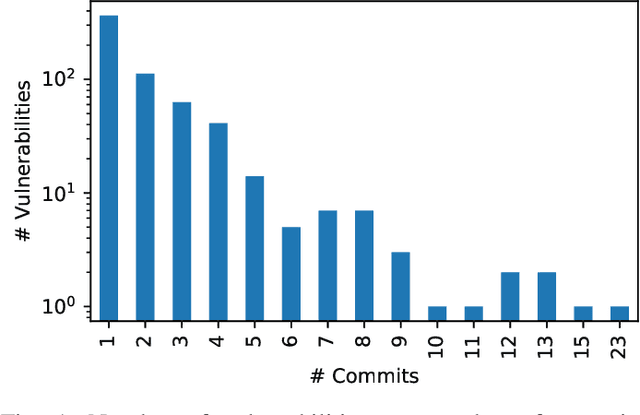

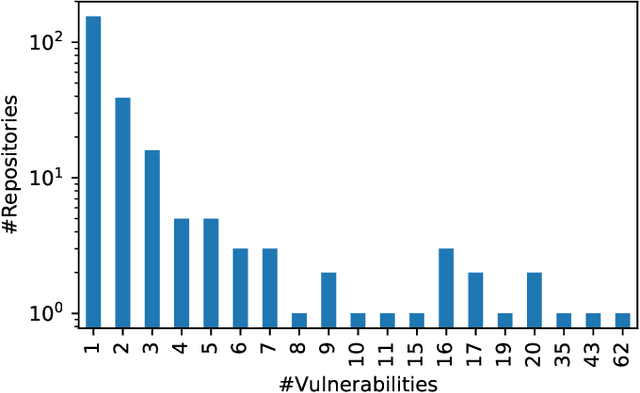
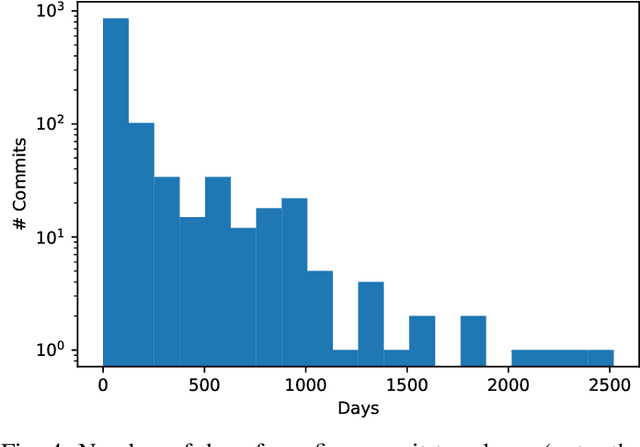
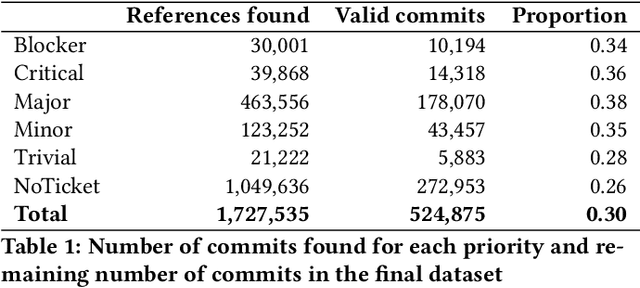
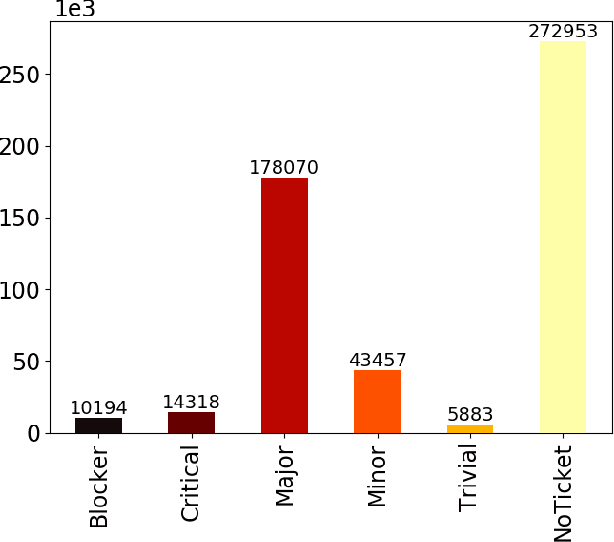
Advancing our understanding of software vulnerabilities, automating their identification, the analysis of their impact, and ultimately their mitigation is necessary to enable the development of software that is more secure. While operating a vulnerability assessment tool that we developed and that is currently used by hundreds of development units at SAP, we manually collected and curated a dataset of vulnerabilities of open-source software and the commits fixing them. The data was obtained both from the National Vulnerability Database (NVD) and from project-specific Web resources that we monitor on a continuous basis. From that data, we extracted a dataset that maps 624 publicly disclosed vulnerabilities affecting 205 distinct open-source Java projects, used in SAP products or internal tools, onto the 1282 commits that fix them. Out of 624 vulnerabilities, 29 do not have a CVE identifier at all and 46, which do have a CVE identifier assigned by a numbering authority, are not available in the NVD yet. The dataset is released under an open-source license, together with supporting scripts that allow researchers to automatically retrieve the actual content of the commits from the corresponding repositories and to augment the attributes available for each instance. Also, these scripts allow to complement the dataset with additional instances that are not security fixes (which is useful, for example, in machine learning applications). Our dataset has been successfully used to train classifiers that could automatically identify security-relevant commits in code repositories. The release of this dataset and the supporting code as open-source will allow future research to be based on data of industrial relevance; also, it represents a concrete step towards making the maintenance of this dataset a shared effort involving open-source communities, academia, and the industry.
* This is a pre-print version of the paper that appears in the proceedings of The 16th International Conference on Mining Software Repositories (MSR), Data Showcase track
Towards understanding and modelling office daily life
Jun 13, 2007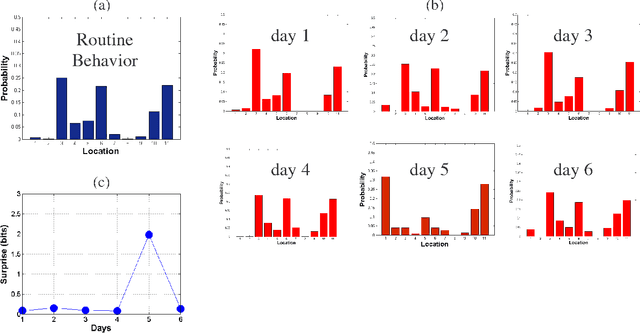
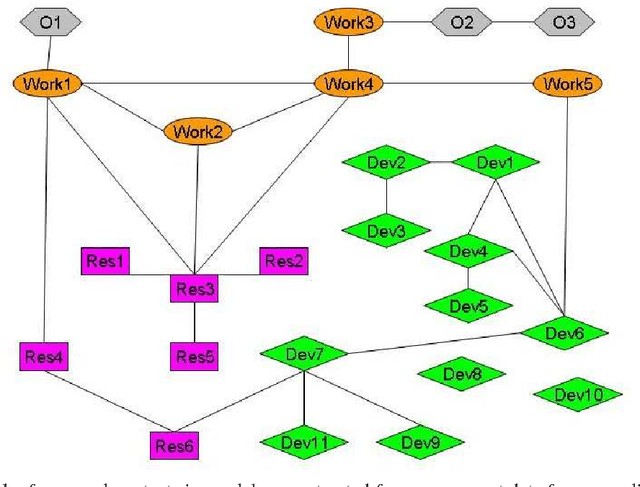
Measuring and modeling human behavior is a very complex task. In this paper we present our initial thoughts on modeling and automatic recognition of some human activities in an office. We argue that to successfully model human activities, we need to consider both individual behavior and group dynamics. To demonstrate these theoretical approaches, we introduce an experimental system for analyzing everyday activity in our office.