 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommit2Vec: Learning Distributed Representations of Code Changes
Paper and Code
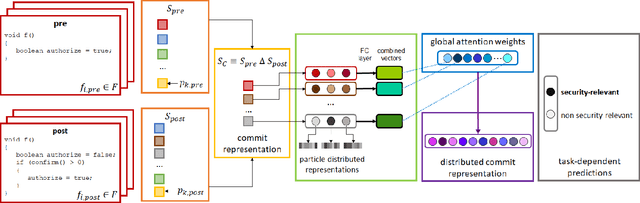
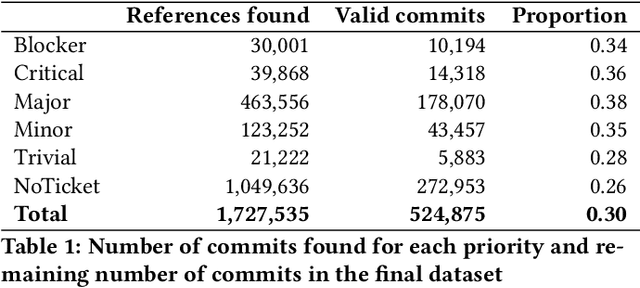

Deep learning methods, which have found successful applications in fields like image classification and natural language processing, have recently been applied to source code analysis too, due to the enormous amount of freely available source code (e.g., from open-source software repositories). In this work, we elaborate upon a state-of-the-art approach to the representation of source code that uses information about its syntactic structure, and we adapt it to represent source changes (i.e., commits). We use this representation to classify security-relevant commits. Because our method uses transfer learning (that is, we train a network on a "pretext task" for which abundant labeled data is available, and then we use such network for the target task of commit classification, for which fewer labeled instances are available), we studied the impact of pre-training the network using two different pretext tasks versus a randomly initialized model. Our results indicate that representations that leverage the structural information obtained through code syntax outperform token-based representations. Furthermore, the performance metrics obtained when pre-training on a loosely related pretext task with a very large dataset ($>10^6$ samples) were surpassed when pretraining on a smaller dataset ($>10^4$ samples) but for a pretext task that is more closely related to the target task.