 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Mapping of Vulnerability Advisories onto their Fix Commits in Open Source Repositories
Paper and Code

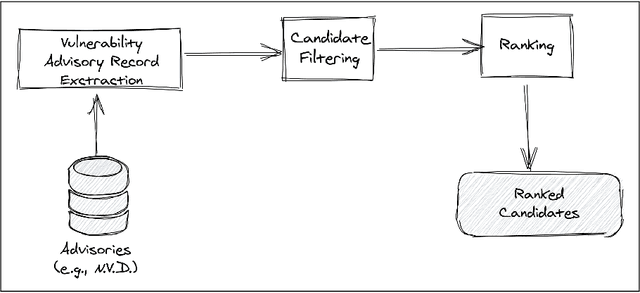
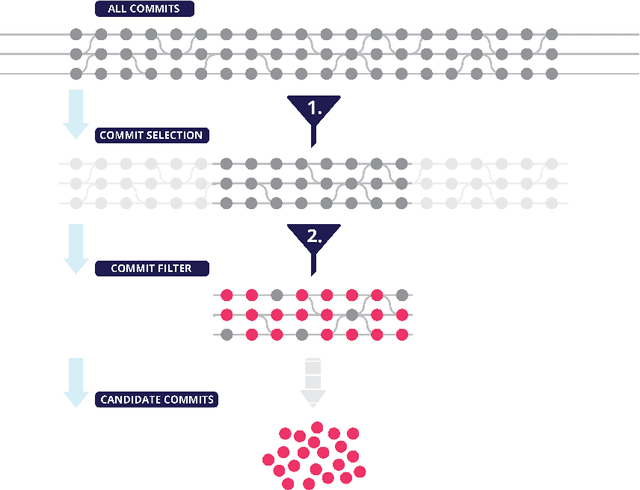

The lack of comprehensive sources of accurate vulnerability data represents a critical obstacle to studying and understanding software vulnerabilities (and their corrections). In this paper, we present an approach that combines heuristics stemming from practical experience and machine-learning (ML) - specifically, natural language processing (NLP) - to address this problem. Our method consists of three phases. First, an advisory record containing key information about a vulnerability is extracted from an advisory (expressed in natural language). Second, using heuristics, a subset of candidate fix commits is obtained from the source code repository of the affected project by filtering out commits that are known to be irrelevant for the task at hand. Finally, for each such candidate commit, our method builds a numerical feature vector reflecting the characteristics of the commit that are relevant to predicting its match with the advisory at hand. The feature vectors are then exploited for building a final ranked list of candidate fixing commits. The score attributed by the ML model to each feature is kept visible to the users, allowing them to interpret of the predictions. We evaluated our approach using a prototype implementation named Prospector on a manually curated data set that comprises 2,391 known fix commits corresponding to 1,248 public vulnerability advisories. When considering the top-10 commits in the ranked results, our implementation could successfully identify at least one fix commit for up to 84.03% of the vulnerabilities (with a fix commit on the first position for 65.06% of the vulnerabilities). In conclusion, our method reduces considerably the effort needed to search OSS repositories for the commits that fix known vulnerabilities.