 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling and unraveling aggregation and dispersion fallacies in group MCDM
Apr 18, 2023Priorities in multi-criteria decision-making (MCDM) convey the relevance preference of one criterion over another, which is usually reflected by imposing the non-negativity and unit-sum constraints. The processing of such priorities is different than other unconstrained data, but this point is often neglected by researchers, which results in fallacious statistical analysis. This article studies three prevalent fallacies in group MCDM along with solutions based on compositional data analysis to avoid misusing statistical operations. First, we use a compositional approach to aggregate the priorities of a group of DMs and show that the outcome of the compositional analysis is identical to the normalized geometric mean, meaning that the arithmetic mean should be avoided. Furthermore, a new aggregation method is developed, which is a robust surrogate for the geometric mean. We also discuss the errors in computing measures of dispersion, including standard deviation and distance functions. Discussing the fallacies in computing the standard deviation, we provide a probabilistic criteria ranking by developing proper Bayesian tests, where we calculate the extent to which a criterion is more important than another. Finally, we explain the errors in computing the distance between priorities, and a clustering algorithm is specially tailored based on proper distance metrics.
Internet-of-Things Architectures for Secure Cyber-Physical Spaces: the VISOR Experience Report
Apr 01, 2022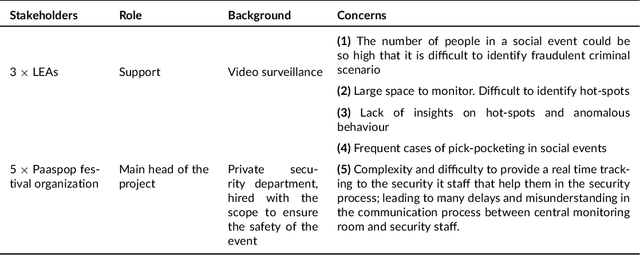
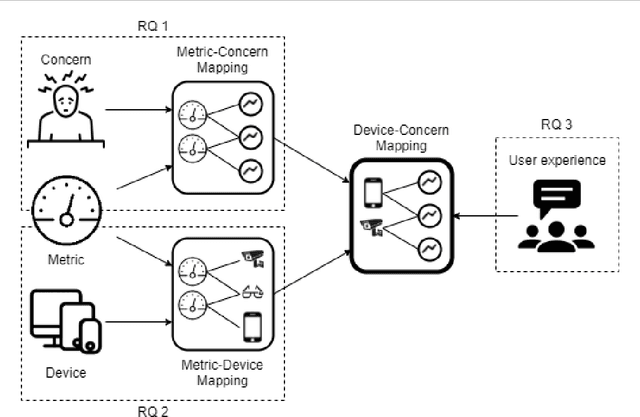


Internet of things (IoT) technologies are becoming a more and more widespread part of civilian life in common urban spaces, which are rapidly turning into cyber-physical spaces. Simultaneously, the fear of terrorism and crime in such public spaces is ever-increasing. Due to the resulting increased demand for security, video-based IoT surveillance systems have become an important area for research. Considering the large number of devices involved in the illicit recognition task, we conducted a field study in a Dutch Easter music festival in a national interest project called VISOR to select the most appropriate device configuration in terms of performance and results. We iteratively architected solutions for the security of cyber-physical spaces using IoT devices. We tested the performance of multiple federated devices encompassing drones, closed-circuit television, smart phone cameras, and smart glasses to detect real-case scenarios of potentially malicious activities such as mosh-pits and pick-pocketing. Our results pave the way to select optimal IoT architecture configurations -- i.e., a mix of CCTV, drones, smart glasses, and camera phones in our case -- to make safer cyber-physical spaces' a reality.
An efficient projection neural network for $\ell_1$-regularized logistic regression
May 12, 2021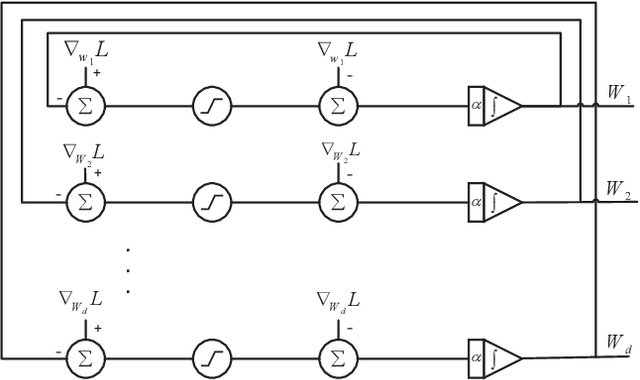
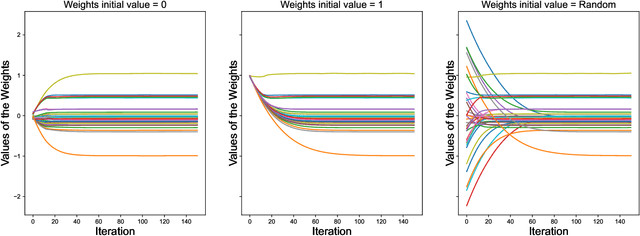
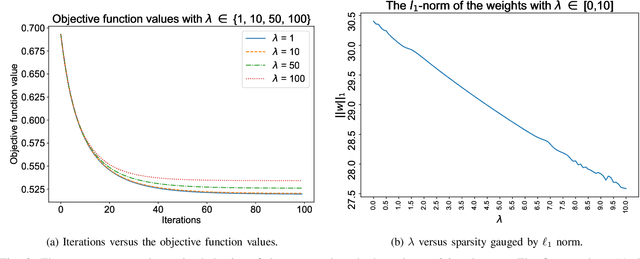
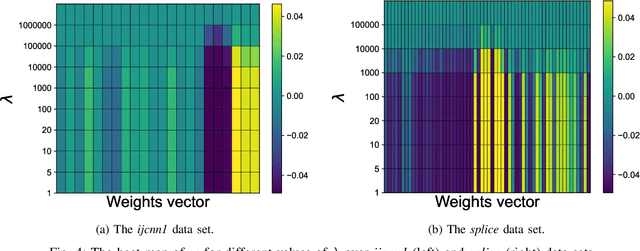
$\ell_1$ regularization has been used for logistic regression to circumvent the overfitting and use the estimated sparse coefficient for feature selection. However, the challenge of such a regularization is that the $\ell_1$ norm is not differentiable, making the standard algorithms for convex optimization not applicable to this problem. This paper presents a simple projection neural network for $\ell_1$-regularized logistics regression. In contrast to many available solvers in the literature, the proposed neural network does not require any extra auxiliary variable nor any smooth approximation, and its complexity is almost identical to that of the gradient descent for logistic regression without $\ell_1$ regularization, thanks to the projection operator. We also investigate the convergence of the proposed neural network by using the Lyapunov theory and show that it converges to a solution of the problem with any arbitrary initial value. The proposed neural solution significantly outperforms state-of-the-art methods with respect to the execution time and is competitive in terms of accuracy and AUROC.
Detecting Security Fixes in Open-Source Repositories using Static Code Analyzers
May 07, 2021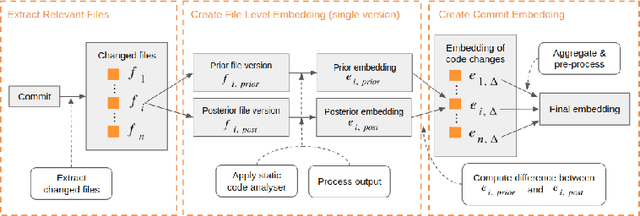
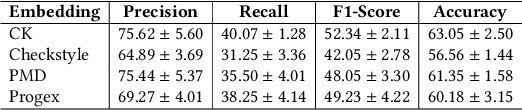
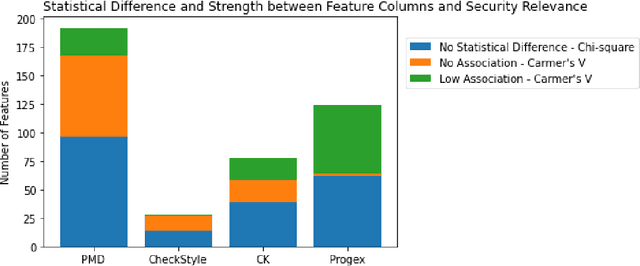
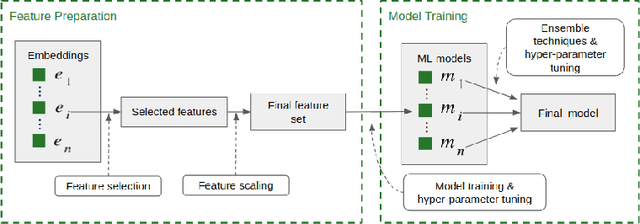
The sources of reliable, code-level information about vulnerabilities that affect open-source software (OSS) are scarce, which hinders a broad adoption of advanced tools that provide code-level detection and assessment of vulnerable OSS dependencies. In this paper, we study the extent to which the output of off-the-shelf static code analyzers can be used as a source of features to represent commits in Machine Learning (ML) applications. In particular, we investigate how such features can be used to construct embeddings and train ML models to automatically identify source code commits that contain vulnerability fixes. We analyze such embeddings for security-relevant and non-security-relevant commits, and we show that, although in isolation they are not different in a statistically significant manner, it is possible to use them to construct a ML pipeline that achieves results comparable with the state of the art. We also found that the combination of our method with commit2vec represents a tangible improvement over the state of the art in the automatic identification of commits that fix vulnerabilities: the ML models we construct and commit2vec are complementary, the former being more generally applicable, albeit not as accurate.
Automated Mapping of Vulnerability Advisories onto their Fix Commits in Open Source Repositories
Mar 24, 2021
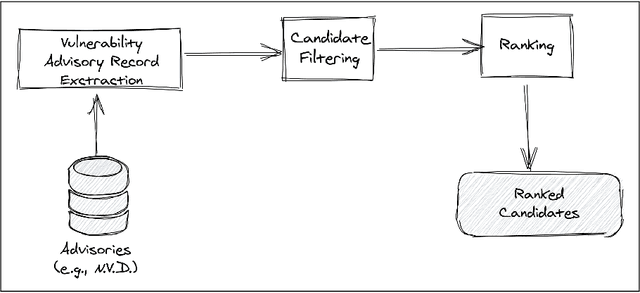
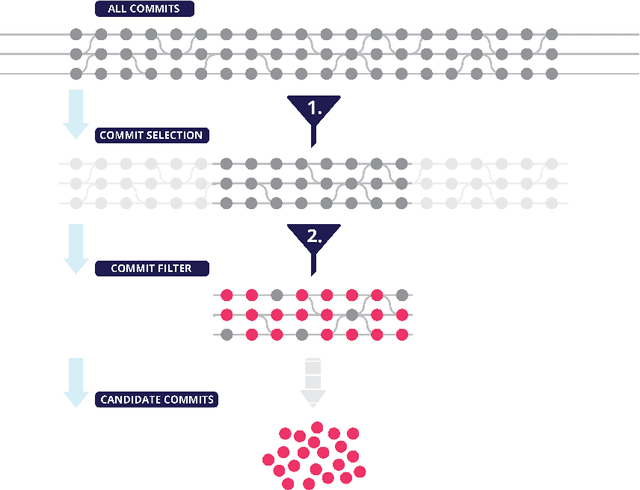

The lack of comprehensive sources of accurate vulnerability data represents a critical obstacle to studying and understanding software vulnerabilities (and their corrections). In this paper, we present an approach that combines heuristics stemming from practical experience and machine-learning (ML) - specifically, natural language processing (NLP) - to address this problem. Our method consists of three phases. First, an advisory record containing key information about a vulnerability is extracted from an advisory (expressed in natural language). Second, using heuristics, a subset of candidate fix commits is obtained from the source code repository of the affected project by filtering out commits that are known to be irrelevant for the task at hand. Finally, for each such candidate commit, our method builds a numerical feature vector reflecting the characteristics of the commit that are relevant to predicting its match with the advisory at hand. The feature vectors are then exploited for building a final ranked list of candidate fixing commits. The score attributed by the ML model to each feature is kept visible to the users, allowing them to interpret of the predictions. We evaluated our approach using a prototype implementation named Prospector on a manually curated data set that comprises 2,391 known fix commits corresponding to 1,248 public vulnerability advisories. When considering the top-10 commits in the ranked results, our implementation could successfully identify at least one fix commit for up to 84.03% of the vulnerabilities (with a fix commit on the first position for 65.06% of the vulnerabilities). In conclusion, our method reduces considerably the effort needed to search OSS repositories for the commits that fix known vulnerabilities.