 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Security Fixes in Open-Source Repositories using Static Code Analyzers
May 07, 2021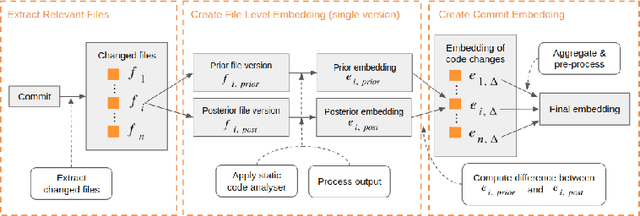
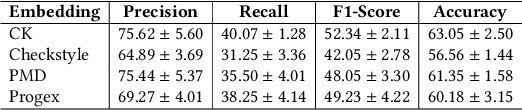
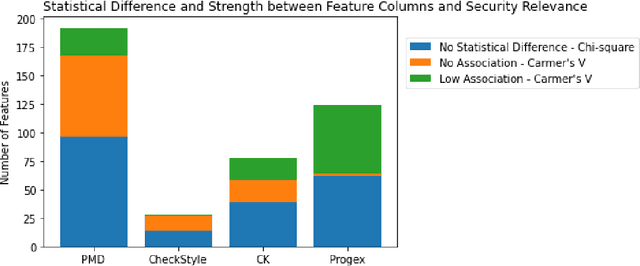
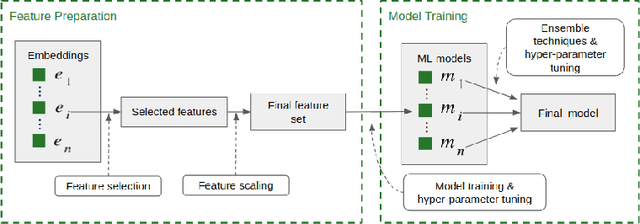
The sources of reliable, code-level information about vulnerabilities that affect open-source software (OSS) are scarce, which hinders a broad adoption of advanced tools that provide code-level detection and assessment of vulnerable OSS dependencies. In this paper, we study the extent to which the output of off-the-shelf static code analyzers can be used as a source of features to represent commits in Machine Learning (ML) applications. In particular, we investigate how such features can be used to construct embeddings and train ML models to automatically identify source code commits that contain vulnerability fixes. We analyze such embeddings for security-relevant and non-security-relevant commits, and we show that, although in isolation they are not different in a statistically significant manner, it is possible to use them to construct a ML pipeline that achieves results comparable with the state of the art. We also found that the combination of our method with commit2vec represents a tangible improvement over the state of the art in the automatic identification of commits that fix vulnerabilities: the ML models we construct and commit2vec are complementary, the former being more generally applicable, albeit not as accurate.