 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign choices made by LLM-based test generators prevent them from finding bugs
Dec 18, 2024There is an increasing amount of research and commercial tools for automated test case generation using Large Language Models (LLMs). This paper critically examines whether recent LLM-based test generation tools, such as Codium CoverAgent and CoverUp, can effectively find bugs or unintentionally validate faulty code. Considering bugs are only exposed by failing test cases, we explore the question: can these tools truly achieve the intended objectives of software testing when their test oracles are designed to pass? Using real human-written buggy code as input, we evaluate these tools, showing how LLM-generated tests can fail to detect bugs and, more alarmingly, how their design can worsen the situation by validating bugs in the generated test suite and rejecting bug-revealing tests. These findings raise important questions about the validity of the design behind LLM-based test generation tools and their impact on software quality and test suite reliability.
BLAZE: Cross-Language and Cross-Project Bug Localization via Dynamic Chunking and Hard Example Learning
Jul 24, 2024Software bugs require developers to exert significant effort to identify and resolve them, often consuming about one-third of their time. Bug localization, the process of pinpointing the exact source code files that need modification, is crucial in reducing this effort. Existing bug localization tools, typically reliant on deep learning techniques, face limitations in cross-project applicability and effectiveness in multi-language environments. Recent advancements with Large Language Models (LLMs) offer detailed representations for bug localization. However, they encounter challenges with limited context windows and mapping accuracy. To address these issues, we propose BLAZE, an approach that employs dynamic chunking and hard example learning. First, BLAZE dynamically segments source code to minimize continuity loss. Then, BLAZE fine-tunes a GPT-based model using challenging bug cases, in order to enhance cross-project and cross-language bug localization. To support the capability of BLAZE, we create the BEETLEBOX dataset, which comprises 26,321 bugs from 29 large and thriving open-source projects across five different programming languages (Java, C++, Python, Go, and JavaScript). Our evaluations of BLAZE on three benchmark datasets BEETLEBOX, SWE-Bench, and Ye et al. demonstrate substantial improvements compared to six state-of-the-art baselines. Specifically, BLAZE achieves up to an increase of 120% in Top 1 accuracy, 144% in Mean Average Precision (MAP), and 100% in Mean Reciprocal Rank (MRR). An extensive ablation study confirms the contributions of our pipeline components to the overall performance enhancement.
Revisiting the Performance of Deep Learning-Based Vulnerability Detection on Realistic Datasets
Jul 03, 2024



The impact of software vulnerabilities on everyday software systems is significant. Despite deep learning models being proposed for vulnerability detection, their reliability is questionable. Prior evaluations show high recall/F1 scores of up to 99%, but these models underperform in practical scenarios, particularly when assessed on entire codebases rather than just the fixing commit. This paper introduces Real-Vul, a comprehensive dataset representing real-world scenarios for evaluating vulnerability detection models. Evaluating DeepWukong, LineVul, ReVeal, and IVDetect shows a significant drop in performance, with precision decreasing by up to 95 percentage points and F1 scores by up to 91 points. Furthermore, Model performance fluctuates based on vulnerability characteristics, with better F1 scores for information leaks or code injection than for path resolution or predictable return values. The results highlight a significant performance gap that needs addressing before deploying deep learning-based vulnerability detection in practical settings. Overfitting is identified as a key issue, and an augmentation technique is proposed, potentially improving performance by up to 30%. Contributions include a dataset creation approach for better model evaluation, Real-Vul dataset, and empirical evidence of deep learning models struggling in real-world settings.
Aligning Programming Language and Natural Language: Exploring Design Choices in Multi-Modal Transformer-Based Embedding for Bug Localization
Jun 25, 2024



Bug localization refers to the identification of source code files which is in a programming language and also responsible for the unexpected behavior of software using the bug report, which is a natural language. As bug localization is labor-intensive, bug localization models are employed to assist software developers. Due to the domain difference between source code files and bug reports, modern bug-localization systems, based on deep learning models, rely heavily on embedding techniques that project bug reports and source code files into a shared vector space. The creation of an embedding involves several design choices, but the impact of these choices on the quality of embedding and the performance of bug localization models remains unexplained in current research. To address this gap, our study evaluated 14 distinct embedding models to gain insights into the effects of various design choices. Subsequently, we developed bug localization models utilizing these embedding models to assess the influence of these choices on the performance of the localization models. Our findings indicate that the pre-training strategies significantly affect the quality of the embedding. Moreover, we discovered that the familiarity of the embedding models with the data has a notable impact on the bug localization model's performance. Notably, when the training and testing data are collected from different projects, the performance of the bug localization models exhibits substantial fluctuations.
Test-Driven Development for Code Generation
Feb 21, 2024



Large language models (LLMs) like GPT4, have shown proficiency in generating code snippets from problem statements. Traditionally software development by humans followed a similar methodology of writing code from problem statements or requirements. However, in the past, there have been several studies that have shown the value of test-driven development (TDD) where humans write tests based on problem statements before the code for the functionality is written. In the context of LLM-based code generation, one obvious benefit of TDD is that the developer then knows for sure if the generated code has passed all the given tests or not. Therefore, in this paper, we want to empirically evaluate the hypothesis: giving the problem statements and tests as input to GPT4 is better than just giving the problem statement as input. To test our hypothesis, we build a framework TGen. In our experiments on the MBPP, HumanEval and CodeChef datasets, we consistently find that including tests solves more programming problems than not including them. Thus we show that TDD is a better development model than just using a problem statement when using GPT4 for code generation tasks.
RLocator: Reinforcement Learning for Bug Localization
May 09, 2023Software developers spend a significant portion of time fixing bugs in their projects. To streamline this process, bug localization approaches have been proposed to identify the source code files that are likely responsible for a particular bug. Prior work proposed several similarity-based machine-learning techniques for bug localization. Despite significant advances in these techniques, they do not directly optimize the evaluation measures. Instead, they use different metrics in the training and testing phases, which can negatively impact the model performance in retrieval tasks. In this paper, we propose RLocator, a Reinforcement Learning-based (RL) bug localization approach. We formulate the bug localization problem using a Markov Decision Process (MDP) to optimize the evaluation measures directly. We present the technique and experimentally evaluate it based on a benchmark dataset of 8,316 bug reports from six highly popular Apache projects. Our evaluation shows that RLocator achieves up to a Mean Reciprocal Rank (MRR) of 0.62 and a Mean Average Precision (MAP) of 0.59. Our results demonstrate that directly optimizing evaluation measures considerably contributes to performance improvement of the bug localization problem.
ApacheJIT: A Large Dataset for Just-In-Time Defect Prediction
Feb 28, 2022
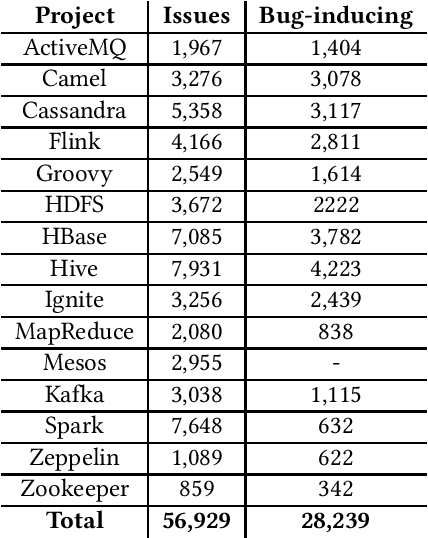
In this paper, we present ApacheJIT, a large dataset for Just-In-Time defect prediction. ApacheJIT consists of clean and bug-inducing software changes in popular Apache projects. ApacheJIT has a total of 106,674 commits (28,239 bug-inducing and 78,435 clean commits). Having a large number of commits makes ApacheJIT a suitable dataset for machine learning models, especially deep learning models that require large training sets to effectively generalize the patterns present in the historical data to future data. In addition to the original dataset, we also present carefully selected training and test sets that we recommend to be used in training and evaluating machine learning models.
Exploiting Token and Path-based Representations of Code for Identifying Security-Relevant Commits
Nov 15, 2019
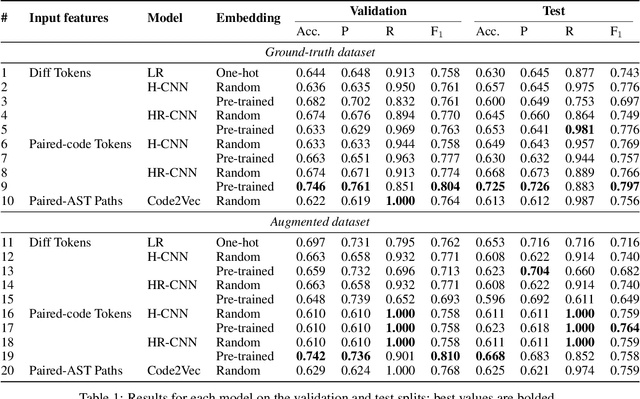
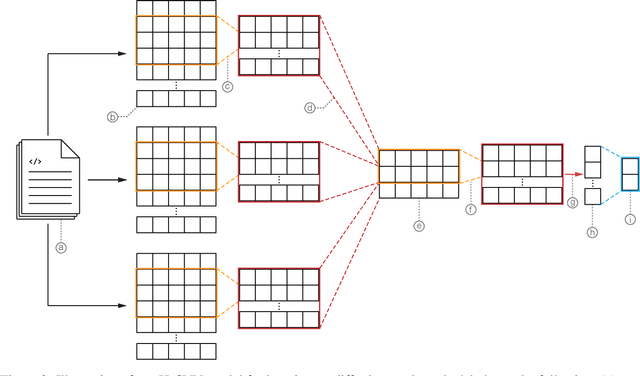
Public vulnerability databases such as CVE and NVD account for only 60% of security vulnerabilities present in open-source projects, and are known to suffer from inconsistent quality. Over the last two years, there has been considerable growth in the number of known vulnerabilities across projects available in various repositories such as NPM and Maven Central. Such an increasing risk calls for a mechanism to infer the presence of security threats in a timely manner. We propose novel hierarchical deep learning models for the identification of security-relevant commits from either the commit diff or the source code for the Java classes. By comparing the performance of our model against code2vec, a state-of-the-art model that learns from path-based representations of code, and a logistic regression baseline, we show that deep learning models show promising results in identifying security-related commits. We also conduct a comparative analysis of how various deep learning models learn across different input representations and the effect of regularization on the generalization of our models.
Supervised Sentiment Classification with CNNs for Diverse SE Datasets
Dec 23, 2018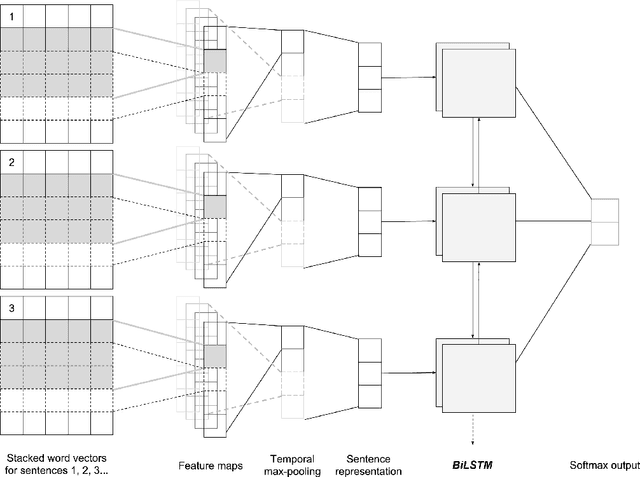
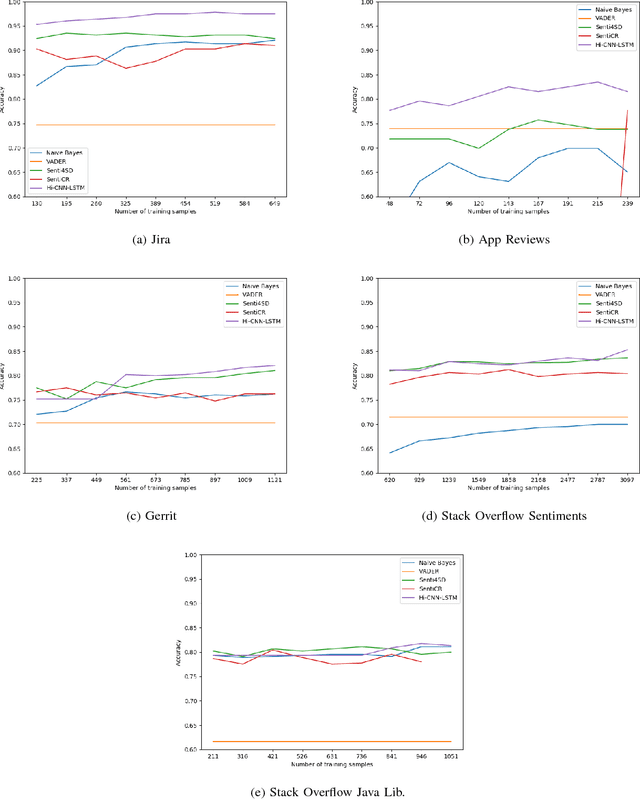
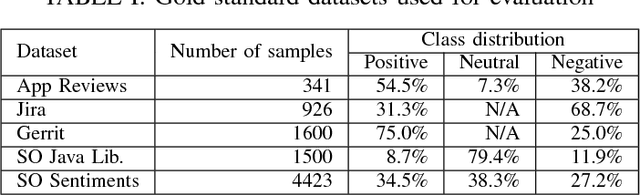
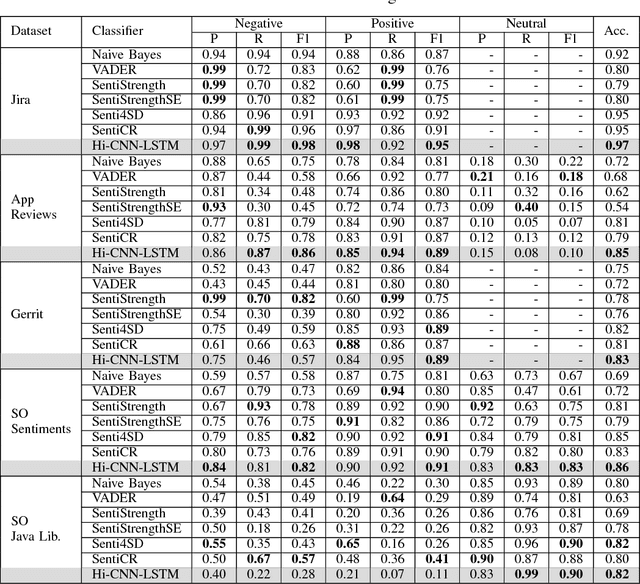
Sentiment analysis, a popular technique for opinion mining, has been used by the software engineering research community for tasks such as assessing app reviews, developer emotions in issue trackers and developer opinions on APIs. Past research indicates that state-of-the-art sentiment analysis techniques have poor performance on SE data. This is because sentiment analysis tools are often designed to work on non-technical documents such as movie reviews. In this study, we attempt to solve the issues with existing sentiment analysis techniques for SE texts by proposing a hierarchical model based on convolutional neural networks (CNN) and long short-term memory (LSTM) trained on top of pre-trained word vectors. We assessed our model's performance and reliability by comparing it with a number of frequently used sentiment analysis tools on five gold standard datasets. Our results show that our model pushes the state of the art further on all datasets in terms of accuracy. We also show that it is possible to get better accuracy after labelling a small sample of the dataset and re-training our model rather than using an unsupervised classifier.