 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Adapter++: Task-specific Adaptation with Order-aware Alignment for Few-shot Action Recognition
May 09, 2025Large-scale pre-trained models have achieved remarkable success in language and image tasks, leading an increasing number of studies to explore the application of pre-trained image models, such as CLIP, in the domain of few-shot action recognition (FSAR). However, current methods generally suffer from several problems: 1) Direct fine-tuning often undermines the generalization capability of the pre-trained model; 2) The exploration of task-specific information is insufficient in the visual tasks; 3) The semantic order information is typically overlooked during text modeling; 4) Existing cross-modal alignment techniques ignore the temporal coupling of multimodal information. To address these, we propose Task-Adapter++, a parameter-efficient dual adaptation method for both image and text encoders. Specifically, to make full use of the variations across different few-shot learning tasks, we design a task-specific adaptation for the image encoder so that the most discriminative information can be well noticed during feature extraction. Furthermore, we leverage large language models (LLMs) to generate detailed sequential sub-action descriptions for each action class, and introduce semantic order adapters into the text encoder to effectively model the sequential relationships between these sub-actions. Finally, we develop an innovative fine-grained cross-modal alignment strategy that actively maps visual features to reside in the same temporal stage as semantic descriptions. Extensive experiments fully demonstrate the effectiveness and superiority of the proposed method, which achieves state-of-the-art performance on 5 benchmarks consistently. The code is open-sourced at https://github.com/Jaulin-Bage/Task-Adapter-pp.
Building a Multi-modal Spatiotemporal Expert for Zero-shot Action Recognition with CLIP
Dec 13, 2024Zero-shot action recognition (ZSAR) requires collaborative multi-modal spatiotemporal understanding. However, finetuning CLIP directly for ZSAR yields suboptimal performance, given its inherent constraints in capturing essential temporal dynamics from both vision and text perspectives, especially when encountering novel actions with fine-grained spatiotemporal discrepancies. In this work, we propose Spatiotemporal Dynamic Duo (STDD), a novel CLIP-based framework to comprehend multi-modal spatiotemporal dynamics synergistically. For the vision side, we propose an efficient Space-time Cross Attention, which captures spatiotemporal dynamics flexibly with simple yet effective operations applied before and after spatial attention, without adding additional parameters or increasing computational complexity. For the semantic side, we conduct spatiotemporal text augmentation by comprehensively constructing an Action Semantic Knowledge Graph (ASKG) to derive nuanced text prompts. The ASKG elaborates on static and dynamic concepts and their interrelations, based on the idea of decomposing actions into spatial appearances and temporal motions. During the training phase, the frame-level video representations are meticulously aligned with prompt-level nuanced text representations, which are concurrently regulated by the video representations from the frozen CLIP to enhance generalizability. Extensive experiments validate the effectiveness of our approach, which consistently surpasses state-of-the-art approaches on popular video benchmarks (i.e., Kinetics-600, UCF101, and HMDB51) under challenging ZSAR settings. Code is available at https://github.com/Mia-YatingYu/STDD.
Task-Adapter: Task-specific Adaptation of Image Models for Few-shot Action Recognition
Aug 01, 2024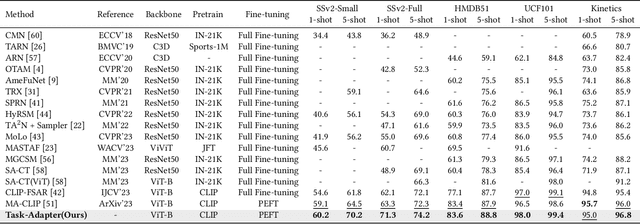
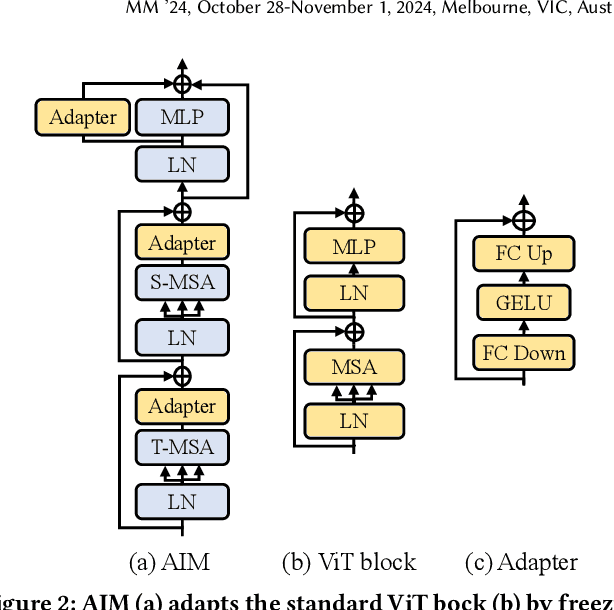
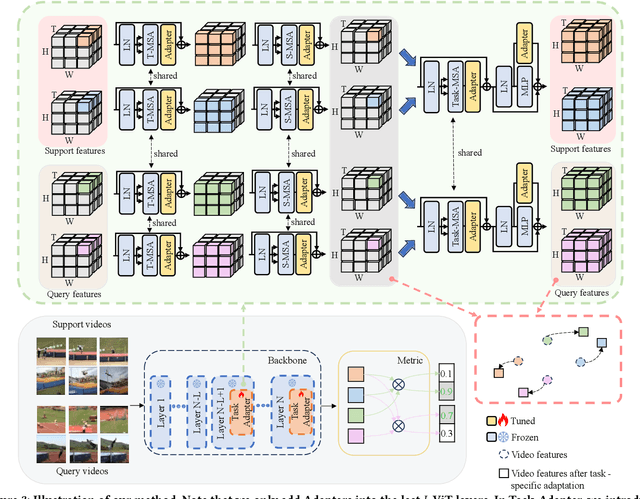
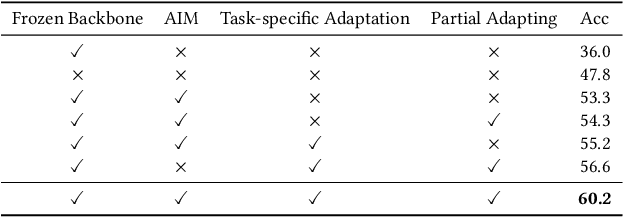
Existing works in few-shot action recognition mostly fine-tune a pre-trained image model and design sophisticated temporal alignment modules at feature level. However, simply fully fine-tuning the pre-trained model could cause overfitting due to the scarcity of video samples. Additionally, we argue that the exploration of task-specific information is insufficient when relying solely on well extracted abstract features. In this work, we propose a simple but effective task-specific adaptation method (Task-Adapter) for few-shot action recognition. By introducing the proposed Task-Adapter into the last several layers of the backbone and keeping the parameters of the original pre-trained model frozen, we mitigate the overfitting problem caused by full fine-tuning and advance the task-specific mechanism into the process of feature extraction. In each Task-Adapter, we reuse the frozen self-attention layer to perform task-specific self-attention across different videos within the given task to capture both distinctive information among classes and shared information within classes, which facilitates task-specific adaptation and enhances subsequent metric measurement between the query feature and support prototypes. Experimental results consistently demonstrate the effectiveness of our proposed Task-Adapter on four standard few-shot action recognition datasets. Especially on temporal challenging SSv2 dataset, our method outperforms the state-of-the-art methods by a large margin.
VS-TransGRU: A Novel Transformer-GRU-based Framework Enhanced by Visual-Semantic Fusion for Egocentric Action Anticipation
Jul 08, 2023



Egocentric action anticipation is a challenging task that aims to make advanced predictions of future actions from current and historical observations in the first-person view. Most existing methods focus on improving the model architecture and loss function based on the visual input and recurrent neural network to boost the anticipation performance. However, these methods, which merely consider visual information and rely on a single network architecture, gradually reach a performance plateau. In order to fully understand what has been observed and capture the dependencies between current observations and future actions well enough, we propose a novel visual-semantic fusion enhanced and Transformer GRU-based action anticipation framework in this paper. Firstly, high-level semantic information is introduced to improve the performance of action anticipation for the first time. We propose to use the semantic features generated based on the class labels or directly from the visual observations to augment the original visual features. Secondly, an effective visual-semantic fusion module is proposed to make up for the semantic gap and fully utilize the complementarity of different modalities. Thirdly, to take advantage of both the parallel and autoregressive models, we design a Transformer based encoder for long-term sequential modeling and a GRU-based decoder for flexible iteration decoding. Extensive experiments on two large-scale first-person view datasets, i.e., EPIC-Kitchens and EGTEA Gaze+, validate the effectiveness of our proposed method, which achieves new state-of-the-art performance, outperforming previous approaches by a large margin.
Cross-Spatial Pixel Integration and Cross-Stage Feature Fusion Based Transformer Network for Remote Sensing Image Super-Resolution
Jul 06, 2023



Remote sensing image super-resolution (RSISR) plays a vital role in enhancing spatial detials and improving the quality of satellite imagery. Recently, Transformer-based models have shown competitive performance in RSISR. To mitigate the quadratic computational complexity resulting from global self-attention, various methods constrain attention to a local window, enhancing its efficiency. Consequently, the receptive fields in a single attention layer are inadequate, leading to insufficient context modeling. Furthermore, while most transform-based approaches reuse shallow features through skip connections, relying solely on these connections treats shallow and deep features equally, impeding the model's ability to characterize them. To address these issues, we propose a novel transformer architecture called Cross-Spatial Pixel Integration and Cross-Stage Feature Fusion Based Transformer Network (SPIFFNet) for RSISR. Our proposed model effectively enhances global cognition and understanding of the entire image, facilitating efficient integration of features cross-stages. The model incorporates cross-spatial pixel integration attention (CSPIA) to introduce contextual information into a local window, while cross-stage feature fusion attention (CSFFA) adaptively fuses features from the previous stage to improve feature expression in line with the requirements of the current stage. We conducted comprehensive experiments on multiple benchmark datasets, demonstrating the superior performance of our proposed SPIFFNet in terms of both quantitative metrics and visual quality when compared to state-of-the-art methods.