 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding a Multi-modal Spatiotemporal Expert for Zero-shot Action Recognition with CLIP
Dec 13, 2024Zero-shot action recognition (ZSAR) requires collaborative multi-modal spatiotemporal understanding. However, finetuning CLIP directly for ZSAR yields suboptimal performance, given its inherent constraints in capturing essential temporal dynamics from both vision and text perspectives, especially when encountering novel actions with fine-grained spatiotemporal discrepancies. In this work, we propose Spatiotemporal Dynamic Duo (STDD), a novel CLIP-based framework to comprehend multi-modal spatiotemporal dynamics synergistically. For the vision side, we propose an efficient Space-time Cross Attention, which captures spatiotemporal dynamics flexibly with simple yet effective operations applied before and after spatial attention, without adding additional parameters or increasing computational complexity. For the semantic side, we conduct spatiotemporal text augmentation by comprehensively constructing an Action Semantic Knowledge Graph (ASKG) to derive nuanced text prompts. The ASKG elaborates on static and dynamic concepts and their interrelations, based on the idea of decomposing actions into spatial appearances and temporal motions. During the training phase, the frame-level video representations are meticulously aligned with prompt-level nuanced text representations, which are concurrently regulated by the video representations from the frozen CLIP to enhance generalizability. Extensive experiments validate the effectiveness of our approach, which consistently surpasses state-of-the-art approaches on popular video benchmarks (i.e., Kinetics-600, UCF101, and HMDB51) under challenging ZSAR settings. Code is available at https://github.com/Mia-YatingYu/STDD.
Task-Adapter: Task-specific Adaptation of Image Models for Few-shot Action Recognition
Aug 01, 2024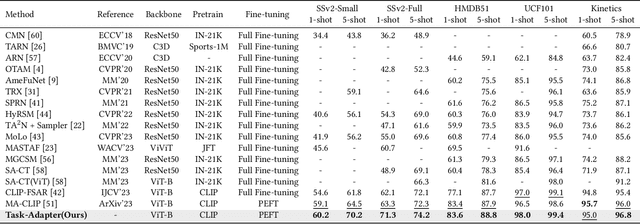
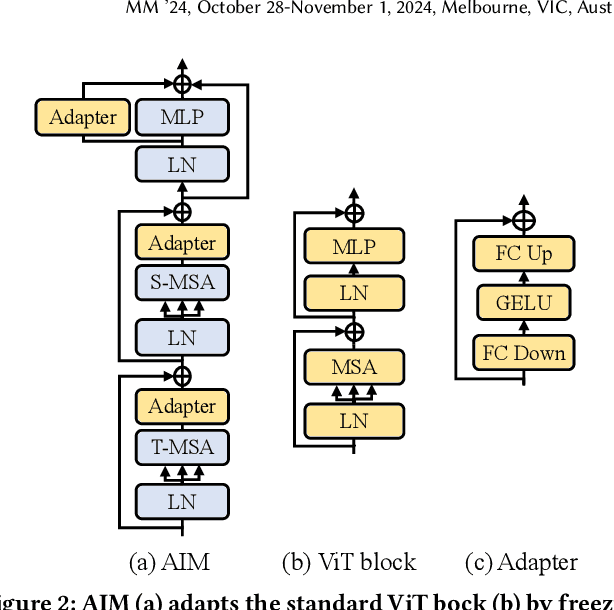
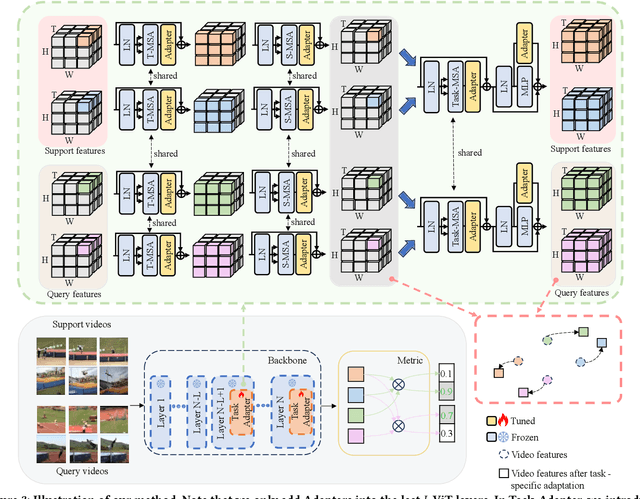
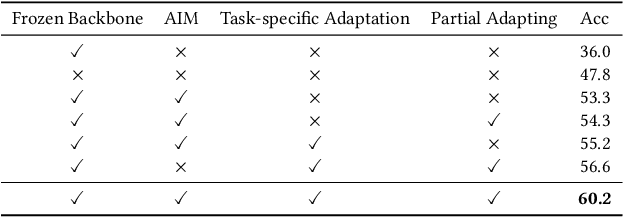
Existing works in few-shot action recognition mostly fine-tune a pre-trained image model and design sophisticated temporal alignment modules at feature level. However, simply fully fine-tuning the pre-trained model could cause overfitting due to the scarcity of video samples. Additionally, we argue that the exploration of task-specific information is insufficient when relying solely on well extracted abstract features. In this work, we propose a simple but effective task-specific adaptation method (Task-Adapter) for few-shot action recognition. By introducing the proposed Task-Adapter into the last several layers of the backbone and keeping the parameters of the original pre-trained model frozen, we mitigate the overfitting problem caused by full fine-tuning and advance the task-specific mechanism into the process of feature extraction. In each Task-Adapter, we reuse the frozen self-attention layer to perform task-specific self-attention across different videos within the given task to capture both distinctive information among classes and shared information within classes, which facilitates task-specific adaptation and enhances subsequent metric measurement between the query feature and support prototypes. Experimental results consistently demonstrate the effectiveness of our proposed Task-Adapter on four standard few-shot action recognition datasets. Especially on temporal challenging SSv2 dataset, our method outperforms the state-of-the-art methods by a large margin.