 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Adapter++: Task-specific Adaptation with Order-aware Alignment for Few-shot Action Recognition
May 09, 2025Large-scale pre-trained models have achieved remarkable success in language and image tasks, leading an increasing number of studies to explore the application of pre-trained image models, such as CLIP, in the domain of few-shot action recognition (FSAR). However, current methods generally suffer from several problems: 1) Direct fine-tuning often undermines the generalization capability of the pre-trained model; 2) The exploration of task-specific information is insufficient in the visual tasks; 3) The semantic order information is typically overlooked during text modeling; 4) Existing cross-modal alignment techniques ignore the temporal coupling of multimodal information. To address these, we propose Task-Adapter++, a parameter-efficient dual adaptation method for both image and text encoders. Specifically, to make full use of the variations across different few-shot learning tasks, we design a task-specific adaptation for the image encoder so that the most discriminative information can be well noticed during feature extraction. Furthermore, we leverage large language models (LLMs) to generate detailed sequential sub-action descriptions for each action class, and introduce semantic order adapters into the text encoder to effectively model the sequential relationships between these sub-actions. Finally, we develop an innovative fine-grained cross-modal alignment strategy that actively maps visual features to reside in the same temporal stage as semantic descriptions. Extensive experiments fully demonstrate the effectiveness and superiority of the proposed method, which achieves state-of-the-art performance on 5 benchmarks consistently. The code is open-sourced at https://github.com/Jaulin-Bage/Task-Adapter-pp.
Vision and Intention Boost Large Language Model in Long-Term Action Anticipation
May 03, 2025



Long-term action anticipation (LTA) aims to predict future actions over an extended period. Previous approaches primarily focus on learning exclusively from video data but lack prior knowledge. Recent researches leverage large language models (LLMs) by utilizing text-based inputs which suffer severe information loss. To tackle these limitations single-modality methods face, we propose a novel Intention-Conditioned Vision-Language (ICVL) model in this study that fully leverages the rich semantic information of visual data and the powerful reasoning capabilities of LLMs. Considering intention as a high-level concept guiding the evolution of actions, we first propose to employ a vision-language model (VLM) to infer behavioral intentions as comprehensive textual features directly from video inputs. The inferred intentions are then fused with visual features through a multi-modality fusion strategy, resulting in intention-enhanced visual representations. These enhanced visual representations, along with textual prompts, are fed into LLM for future action anticipation. Furthermore, we propose an effective example selection strategy jointly considers visual and textual similarities, providing more relevant and informative examples for in-context learning. Extensive experiments with state-of-the-art performance on Ego4D, EPIC-Kitchens-55, and EGTEA GAZE+ datasets fully demonstrate the effectiveness and superiority of the proposed method.
Learning to Generalize without Bias for Open-Vocabulary Action Recognition
Feb 27, 2025

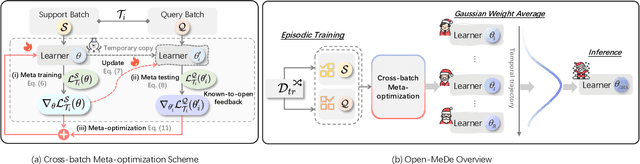

Leveraging the effective visual-text alignment and static generalizability from CLIP, recent video learners adopt CLIP initialization with further regularization or recombination for generalization in open-vocabulary action recognition in-context. However, due to the static bias of CLIP, such video learners tend to overfit on shortcut static features, thereby compromising their generalizability, especially to novel out-of-context actions. To address this issue, we introduce Open-MeDe, a novel Meta-optimization framework with static Debiasing for Open-vocabulary action recognition. From a fresh perspective of generalization, Open-MeDe adopts a meta-learning approach to improve known-to-open generalizing and image-to-video debiasing in a cost-effective manner. Specifically, Open-MeDe introduces a cross-batch meta-optimization scheme that explicitly encourages video learners to quickly generalize to arbitrary subsequent data via virtual evaluation, steering a smoother optimization landscape. In effect, the free of CLIP regularization during optimization implicitly mitigates the inherent static bias of the video meta-learner. We further apply self-ensemble over the optimization trajectory to obtain generic optimal parameters that can achieve robust generalization to both in-context and out-of-context novel data. Extensive evaluations show that Open-MeDe not only surpasses state-of-the-art regularization methods tailored for in-context open-vocabulary action recognition but also substantially excels in out-of-context scenarios.
Building a Multi-modal Spatiotemporal Expert for Zero-shot Action Recognition with CLIP
Dec 13, 2024Zero-shot action recognition (ZSAR) requires collaborative multi-modal spatiotemporal understanding. However, finetuning CLIP directly for ZSAR yields suboptimal performance, given its inherent constraints in capturing essential temporal dynamics from both vision and text perspectives, especially when encountering novel actions with fine-grained spatiotemporal discrepancies. In this work, we propose Spatiotemporal Dynamic Duo (STDD), a novel CLIP-based framework to comprehend multi-modal spatiotemporal dynamics synergistically. For the vision side, we propose an efficient Space-time Cross Attention, which captures spatiotemporal dynamics flexibly with simple yet effective operations applied before and after spatial attention, without adding additional parameters or increasing computational complexity. For the semantic side, we conduct spatiotemporal text augmentation by comprehensively constructing an Action Semantic Knowledge Graph (ASKG) to derive nuanced text prompts. The ASKG elaborates on static and dynamic concepts and their interrelations, based on the idea of decomposing actions into spatial appearances and temporal motions. During the training phase, the frame-level video representations are meticulously aligned with prompt-level nuanced text representations, which are concurrently regulated by the video representations from the frozen CLIP to enhance generalizability. Extensive experiments validate the effectiveness of our approach, which consistently surpasses state-of-the-art approaches on popular video benchmarks (i.e., Kinetics-600, UCF101, and HMDB51) under challenging ZSAR settings. Code is available at https://github.com/Mia-YatingYu/STDD.
Task-Adapter: Task-specific Adaptation of Image Models for Few-shot Action Recognition
Aug 01, 2024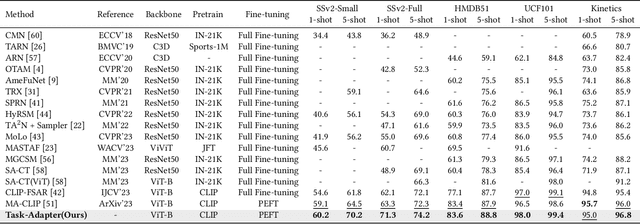
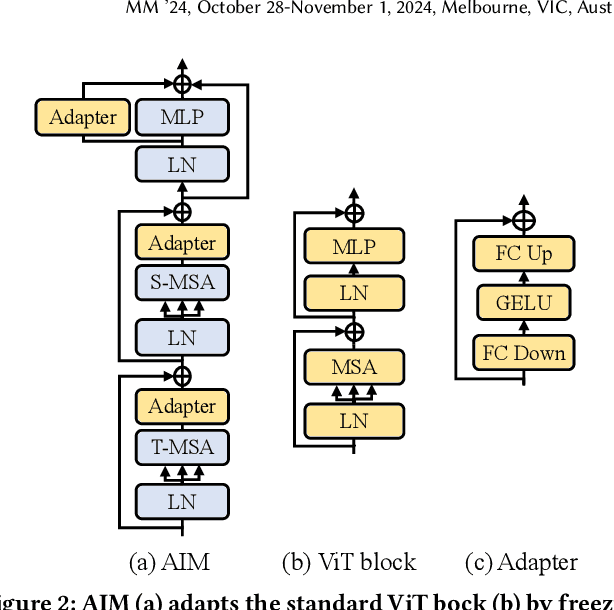
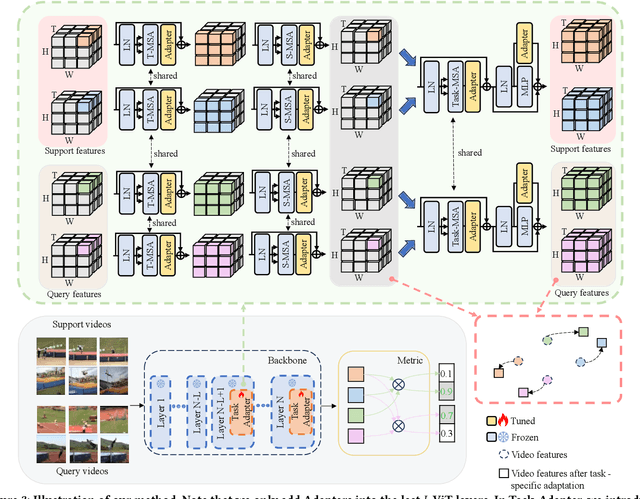
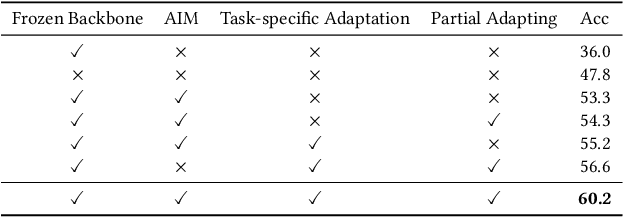
Existing works in few-shot action recognition mostly fine-tune a pre-trained image model and design sophisticated temporal alignment modules at feature level. However, simply fully fine-tuning the pre-trained model could cause overfitting due to the scarcity of video samples. Additionally, we argue that the exploration of task-specific information is insufficient when relying solely on well extracted abstract features. In this work, we propose a simple but effective task-specific adaptation method (Task-Adapter) for few-shot action recognition. By introducing the proposed Task-Adapter into the last several layers of the backbone and keeping the parameters of the original pre-trained model frozen, we mitigate the overfitting problem caused by full fine-tuning and advance the task-specific mechanism into the process of feature extraction. In each Task-Adapter, we reuse the frozen self-attention layer to perform task-specific self-attention across different videos within the given task to capture both distinctive information among classes and shared information within classes, which facilitates task-specific adaptation and enhances subsequent metric measurement between the query feature and support prototypes. Experimental results consistently demonstrate the effectiveness of our proposed Task-Adapter on four standard few-shot action recognition datasets. Especially on temporal challenging SSv2 dataset, our method outperforms the state-of-the-art methods by a large margin.
VS-TransGRU: A Novel Transformer-GRU-based Framework Enhanced by Visual-Semantic Fusion for Egocentric Action Anticipation
Jul 08, 2023



Egocentric action anticipation is a challenging task that aims to make advanced predictions of future actions from current and historical observations in the first-person view. Most existing methods focus on improving the model architecture and loss function based on the visual input and recurrent neural network to boost the anticipation performance. However, these methods, which merely consider visual information and rely on a single network architecture, gradually reach a performance plateau. In order to fully understand what has been observed and capture the dependencies between current observations and future actions well enough, we propose a novel visual-semantic fusion enhanced and Transformer GRU-based action anticipation framework in this paper. Firstly, high-level semantic information is introduced to improve the performance of action anticipation for the first time. We propose to use the semantic features generated based on the class labels or directly from the visual observations to augment the original visual features. Secondly, an effective visual-semantic fusion module is proposed to make up for the semantic gap and fully utilize the complementarity of different modalities. Thirdly, to take advantage of both the parallel and autoregressive models, we design a Transformer based encoder for long-term sequential modeling and a GRU-based decoder for flexible iteration decoding. Extensive experiments on two large-scale first-person view datasets, i.e., EPIC-Kitchens and EGTEA Gaze+, validate the effectiveness of our proposed method, which achieves new state-of-the-art performance, outperforming previous approaches by a large margin.
A New Comprehensive Benchmark for Semi-supervised Video Anomaly Detection and Anticipation
May 23, 2023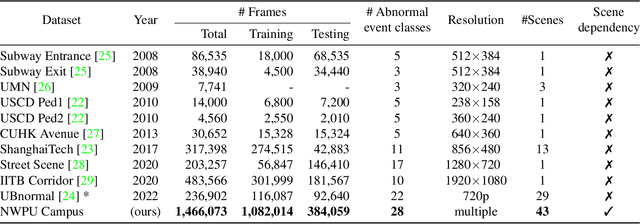

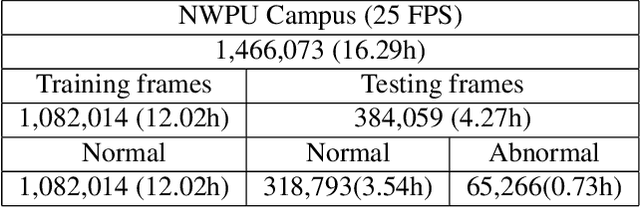
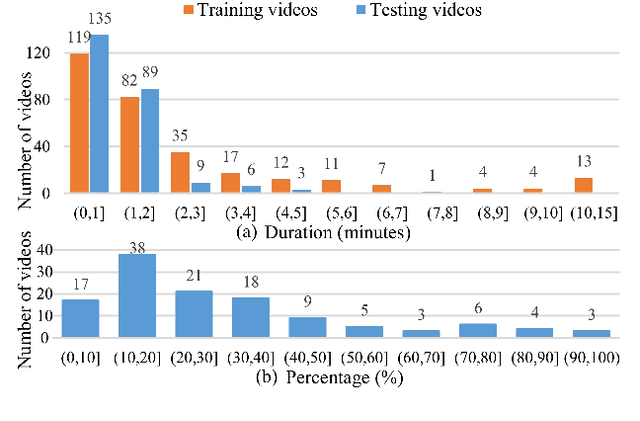
Semi-supervised video anomaly detection (VAD) is a critical task in the intelligent surveillance system. However, an essential type of anomaly in VAD named scene-dependent anomaly has not received the attention of researchers. Moreover, there is no research investigating anomaly anticipation, a more significant task for preventing the occurrence of anomalous events. To this end, we propose a new comprehensive dataset, NWPU Campus, containing 43 scenes, 28 classes of abnormal events, and 16 hours of videos. At present, it is the largest semi-supervised VAD dataset with the largest number of scenes and classes of anomalies, the longest duration, and the only one considering the scene-dependent anomaly. Meanwhile, it is also the first dataset proposed for video anomaly anticipation. We further propose a novel model capable of detecting and anticipating anomalous events simultaneously. Compared with 7 outstanding VAD algorithms in recent years, our method can cope with scene-dependent anomaly detection and anomaly anticipation both well, achieving state-of-the-art performance on ShanghaiTech, CUHK Avenue, IITB Corridor and the newly proposed NWPU Campus datasets consistently. Our dataset and code is available at: https://campusvad.github.io.
Co-Occurrence Matters: Learning Action Relation for Temporal Action Localization
Mar 15, 2023Temporal action localization (TAL) is a prevailing task due to its great application potential. Existing works in this field mainly suffer from two weaknesses: (1) They often neglect the multi-label case and only focus on temporal modeling. (2) They ignore the semantic information in class labels and only use the visual information. To solve these problems, we propose a novel Co-Occurrence Relation Module (CORM) that explicitly models the co-occurrence relationship between actions. Besides the visual information, it further utilizes the semantic embeddings of class labels to model the co-occurrence relationship. The CORM works in a plug-and-play manner and can be easily incorporated with the existing sequence models. By considering both visual and semantic co-occurrence, our method achieves high multi-label relationship modeling capacity. Meanwhile, existing datasets in TAL always focus on low-semantic atomic actions. Thus we construct a challenging multi-label dataset UCF-Crime-TAL that focuses on high-semantic actions by annotating the UCF-Crime dataset at frame level and considering the semantic overlap of different events. Extensive experiments on two commonly used TAL datasets, \textit{i.e.}, MultiTHUMOS and TSU, and our newly proposed UCF-Crime-TAL demenstrate the effectiveness of the proposed CORM, which achieves state-of-the-art performance on these datasets.
Weakly Supervised Video Anomaly Detection Based on Cross-Batch Clustering Guidance
Dec 16, 2022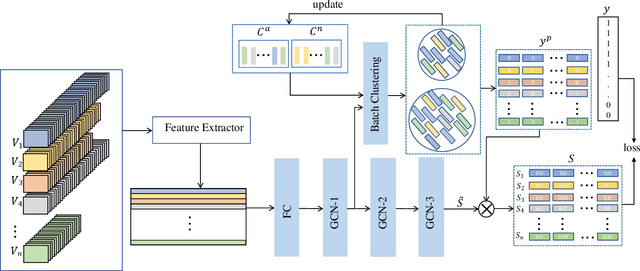
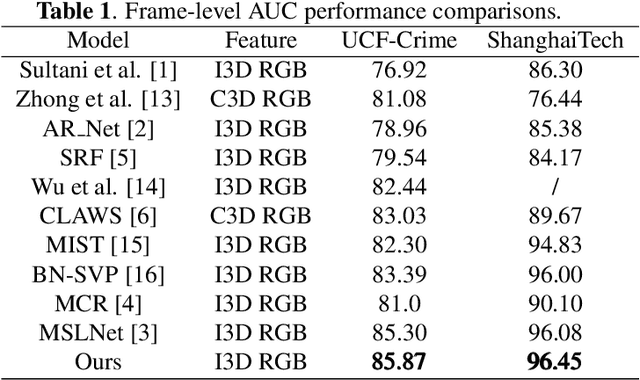
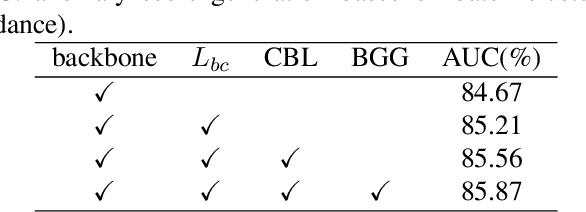
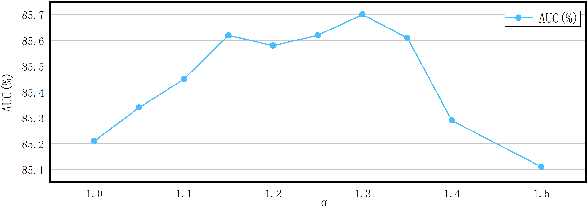
Weakly supervised video anomaly detection (WSVAD) is a challenging task since only video-level labels are available for training. In previous studies, the discriminative power of the learned features is not strong enough, and the data imbalance resulting from the mini-batch training strategy is ignored. To address these two issues, we propose a novel WSVAD method based on cross-batch clustering guidance. To enhance the discriminative power of features, we propose a batch clustering based loss to encourage a clustering branch to generate distinct normal and abnormal clusters based on a batch of data. Meanwhile, we design a cross-batch learning strategy by introducing clustering results from previous mini-batches to reduce the impact of data imbalance. In addition, we propose to generate more accurate segment-level anomaly scores based on batch clustering guidance further improving the performance of WSVAD. Extensive experiments on two public datasets demonstrate the effectiveness of our approach.
Context Recovery and Knowledge Retrieval: A Novel Two-Stream Framework for Video Anomaly Detection
Sep 07, 2022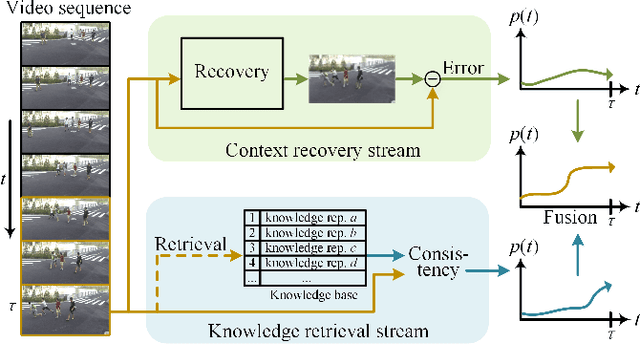
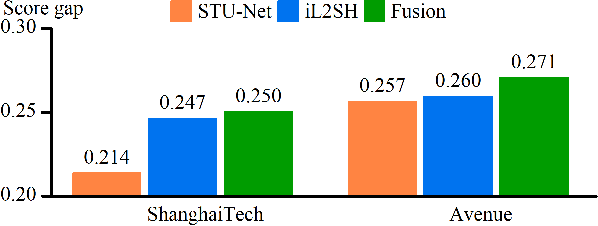
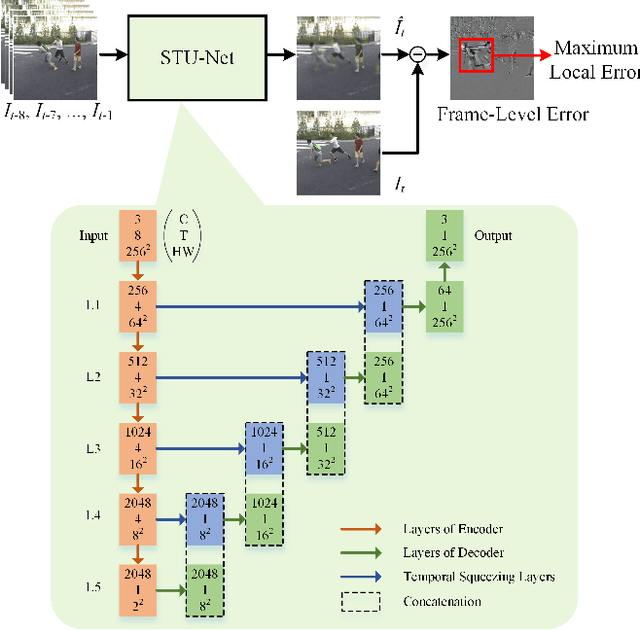
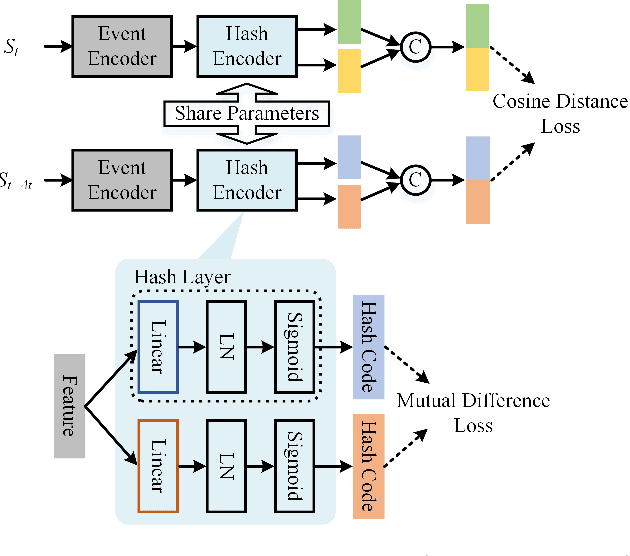
Video anomaly detection aims to find the events in a video that do not conform to the expected behavior. The prevalent methods mainly detect anomalies by snippet reconstruction or future frame prediction error. However, the error is highly dependent on the local context of the current snippet and lacks the understanding of normality. To address this issue, we propose to detect anomalous events not only by the local context, but also according to the consistency between the testing event and the knowledge about normality from the training data. Concretely, we propose a novel two-stream framework based on context recovery and knowledge retrieval, where the two streams can complement each other. For the context recovery stream, we propose a spatiotemporal U-Net which can fully utilize the motion information to predict the future frame. Furthermore, we propose a maximum local error mechanism to alleviate the problem of large recovery errors caused by complex foreground objects. For the knowledge retrieval stream, we propose an improved learnable locality-sensitive hashing, which optimizes hash functions via a Siamese network and a mutual difference loss. The knowledge about normality is encoded and stored in hash tables, and the distance between the testing event and the knowledge representation is used to reveal the probability of anomaly. Finally, we fuse the anomaly scores from the two streams to detect anomalies. Extensive experiments demonstrate the effectiveness and complementarity of the two streams, whereby the proposed two-stream framework achieves state-of-the-art performance on four datasets.