 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Generalize without Bias for Open-Vocabulary Action Recognition
Paper and Code
Feb 27, 2025

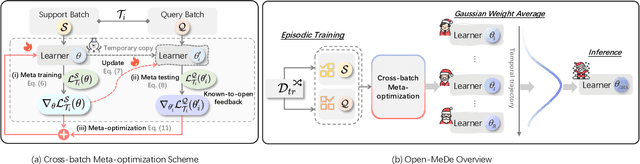

Leveraging the effective visual-text alignment and static generalizability from CLIP, recent video learners adopt CLIP initialization with further regularization or recombination for generalization in open-vocabulary action recognition in-context. However, due to the static bias of CLIP, such video learners tend to overfit on shortcut static features, thereby compromising their generalizability, especially to novel out-of-context actions. To address this issue, we introduce Open-MeDe, a novel Meta-optimization framework with static Debiasing for Open-vocabulary action recognition. From a fresh perspective of generalization, Open-MeDe adopts a meta-learning approach to improve known-to-open generalizing and image-to-video debiasing in a cost-effective manner. Specifically, Open-MeDe introduces a cross-batch meta-optimization scheme that explicitly encourages video learners to quickly generalize to arbitrary subsequent data via virtual evaluation, steering a smoother optimization landscape. In effect, the free of CLIP regularization during optimization implicitly mitigates the inherent static bias of the video meta-learner. We further apply self-ensemble over the optimization trajectory to obtain generic optimal parameters that can achieve robust generalization to both in-context and out-of-context novel data. Extensive evaluations show that Open-MeDe not only surpasses state-of-the-art regularization methods tailored for in-context open-vocabulary action recognition but also substantially excels in out-of-context scenarios.