 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWI: Speaking with Intent in Large Language Models
Mar 27, 2025


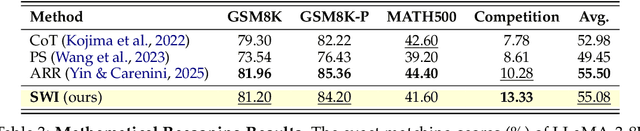
Intent, typically clearly formulated and planned, functions as a cognitive framework for reasoning and problem-solving. This paper introduces the concept of Speaking with Intent (SWI) in large language models (LLMs), where the explicitly generated intent encapsulates the model's underlying intention and provides high-level planning to guide subsequent analysis and communication. By emulating deliberate and purposeful thoughts in the human mind, SWI is hypothesized to enhance the reasoning capabilities and generation quality of LLMs. Extensive experiments on mathematical reasoning benchmarks consistently demonstrate the superiority of Speaking with Intent over Baseline (i.e., generation without explicit intent). Moreover, SWI outperforms answer-trigger prompting methods Chain-of-Thought and Plan-and-Solve and maintains competitive performance with the strong method ARR (Analyzing, Retrieving, and Reasoning). Additionally, the effectiveness and generalizability of SWI are solidified on reasoning-intensive question answering (QA) and text summarization benchmarks, where SWI brings consistent improvement to the Baseline generation. In text summarization, SWI-generated summaries exhibit greater accuracy, conciseness, and factual correctness, with fewer hallucinations. Furthermore, human evaluations verify the coherence, effectiveness, and interpretability of the intent produced by SWI. This proof-of-concept study creates a novel avenue for enhancing LLMs' reasoning abilities with cognitive notions.
BottleHumor: Self-Informed Humor Explanation using the Information Bottleneck Principle
Feb 22, 2025
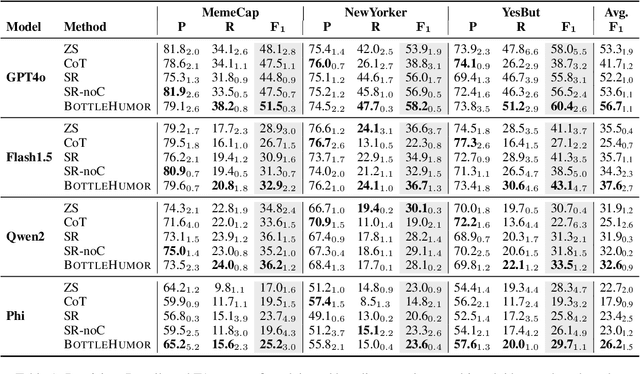


Humor is prevalent in online communications and it often relies on more than one modality (e.g., cartoons and memes). Interpreting humor in multimodal settings requires drawing on diverse types of knowledge, including metaphorical, sociocultural, and commonsense knowledge. However, identifying the most useful knowledge remains an open question. We introduce \method{}, a method inspired by the information bottleneck principle that elicits relevant world knowledge from vision and language models which is iteratively refined for generating an explanation of the humor in an unsupervised manner. Our experiments on three datasets confirm the advantage of our method over a range of baselines. Our method can further be adapted in the future for additional tasks that can benefit from eliciting and conditioning on relevant world knowledge and open new research avenues in this direction.
Enhancing Incremental Summarization with Structured Representations
Jul 21, 2024



Large language models (LLMs) often struggle with processing extensive input contexts, which can lead to redundant, inaccurate, or incoherent summaries. Recent methods have used unstructured memory to incrementally process these contexts, but they still suffer from information overload due to the volume of unstructured data handled. In our study, we introduce structured knowledge representations ($GU_{json}$), which significantly improve summarization performance by 40% and 14% across two public datasets. Most notably, we propose the Chain-of-Key strategy ($CoK_{json}$) that dynamically updates or augments these representations with new information, rather than recreating the structured memory for each new source. This method further enhances performance by 7% and 4% on the datasets.
Aligning Language Models to User Opinions
May 24, 2023An important aspect of developing LLMs that interact with humans is to align models' behavior to their users. It is possible to prompt an LLM into behaving as a certain persona, especially a user group or ideological persona the model captured during its pertaining stage. But, how to best align an LLM with a specific user and not a demographic or ideological group remains an open question. Mining public opinion surveys (by Pew Research), we find that the opinions of a user and their demographics and ideologies are not mutual predictors. We use this insight to align LLMs by modeling both user opinions as well as user demographics and ideology, achieving up to 7 points accuracy gains in predicting public opinions from survey questions across a broad set of topics. In addition to the typical approach of prompting LLMs with demographics and ideology, we discover that utilizing the most relevant past opinions from individual users enables the model to predict user opinions more accurately.
MemeCap: A Dataset for Captioning and Interpreting Memes
May 23, 2023Memes are a widely popular tool for web users to express their thoughts using visual metaphors. Understanding memes requires recognizing and interpreting visual metaphors with respect to the text inside or around the meme, often while employing background knowledge and reasoning abilities. We present the task of meme captioning and release a new dataset, MemeCap. Our dataset contains 6.3K memes along with the title of the post containing the meme, the meme captions, the literal image caption, and the visual metaphors. Despite the recent success of vision and language (VL) models on tasks such as image captioning and visual question answering, our extensive experiments using state-of-the-art VL models show that they still struggle with visual metaphors, and perform substantially worse than humans.