 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward function shape exploration in adversarial imitation learning: an empirical study
Paper and Code
Apr 14, 2021
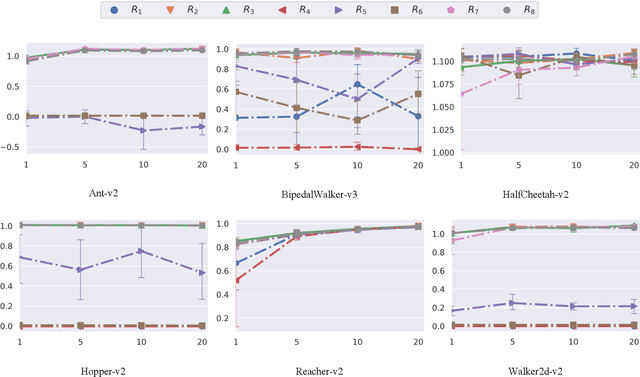
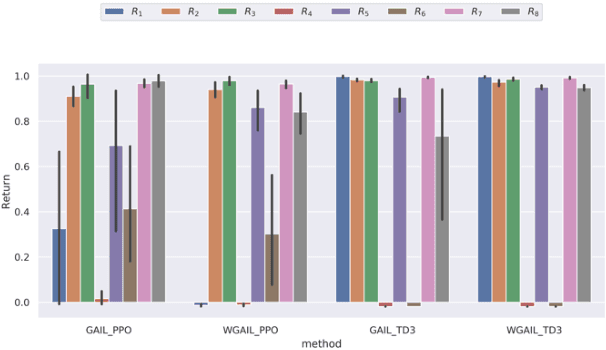
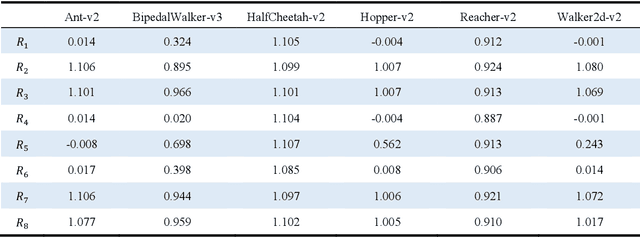
For adversarial imitation learning algorithms (AILs), no true rewards are obtained from the environment for learning the strategy. However, the pseudo rewards based on the output of the discriminator are still required. Given the implicit reward bias problem in AILs, we design several representative reward function shapes and compare their performances by large-scale experiments. To ensure our results' reliability, we conduct the experiments on a series of Mujoco and Box2D continuous control tasks based on four different AILs. Besides, we also compare the performance of various reward function shapes using varying numbers of expert trajectories. The empirical results reveal that the positive logarithmic reward function works well in typical continuous control tasks. In contrast, the so-called unbiased reward function is limited to specific kinds of tasks. Furthermore, several designed reward functions perform excellently in these environments as well.