 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWasserstein Distance guided Adversarial Imitation Learning with Reward Shape Exploration
Paper and Code
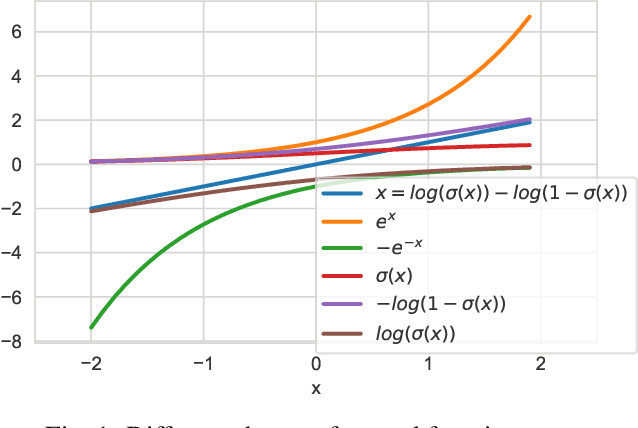
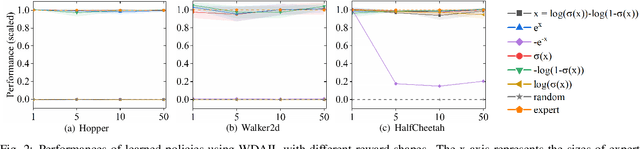

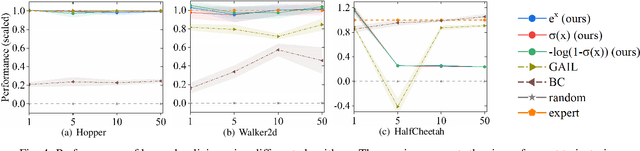
The generative adversarial imitation learning (GAIL) has provided an adversarial learning framework for imitating expert policy from demonstrations in high-dimensional continuous tasks. However, almost all GAIL and its extensions only design a kind of reward function of logarithmic form in the adversarial training strategy with the Jensen-Shannon (JS) divergence for all complex environments. The fixed logarithmic type of reward function may be difficult to solve all complex tasks, and the vanishing gradients problem caused by the JS divergence will harm the adversarial learning process. In this paper, we propose a new algorithm named Wasserstein Distance guided Adversarial Imitation Learning (WDAIL) for promoting the performance of imitation learning (IL). There are three improvements in our method: (a) introducing the Wasserstein distance to obtain more appropriate measure in adversarial training process, (b) using proximal policy optimization (PPO) in the reinforcement learning stage which is much simpler to implement and makes the algorithm more efficient, and (c) exploring different reward function shapes to suit different tasks for improving the performance. The experiment results show that the learning procedure remains remarkably stable, and achieves significant performance in the complex continuous control tasks of MuJoCo.