 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutocorrelation Reintroduces Spectral Bias in KANs for Time Series Forecasting
Apr 26, 2026Existing theory suggests that Kolmogorov-Arnold Networks (KANs) can overcome the spectral bias commonly observed in neural networks under the assumption that inputs are statistically independent. However, this assumption does not hold in time series forecasting (TSF), where inputs are lagged observations with strong temporal autocorrelation. Through theoretical analysis and empirical validation, we obtain an unexpected finding: temporal autocorrelation reintroduces spectral bias in KANs, and the bias becomes increasingly pronounced as the degree of autocorrelation increases. This suggests that standard KANs may face substantial difficulties in TSF with strongly autocorrelated inputs. To address this problem, we introduce the Discrete Cosine Transform (DCT) to reduce the correlations among the network inputs. As expected, experimental results reveal that DCT preprocessing substantially reduces the observed low-frequency preference in TSF. This result also corroborates that the spectral bias of KANs in TSF tasks is indeed induced by the autocorrelation among input variables.
KAN versus MLP on Irregular or Noisy Functions
Aug 15, 2024



In this paper, we compare the performance of Kolmogorov-Arnold Networks (KAN) and Multi-Layer Perceptron (MLP) networks on irregular or noisy functions. We control the number of parameters and the size of the training samples to ensure a fair comparison. For clarity, we categorize the functions into six types: regular functions, continuous functions with local non-differentiable points, functions with jump discontinuities, functions with singularities, functions with coherent oscillations, and noisy functions. Our experimental results indicate that KAN does not always perform best. For some types of functions, MLP outperforms or performs comparably to KAN. Furthermore, increasing the size of training samples can improve performance to some extent. When noise is added to functions, the irregular features are often obscured by the noise, making it challenging for both MLP and KAN to extract these features effectively. We hope these experiments provide valuable insights for future neural network research and encourage further investigations to overcome these challenges.
Reduced Effectiveness of Kolmogorov-Arnold Networks on Functions with Noise
Jul 20, 2024



It has been observed that even a small amount of noise introduced into the dataset can significantly degrade the performance of KAN. In this brief note, we aim to quantitatively evaluate the performance when noise is added to the dataset. We propose an oversampling technique combined with denoising to alleviate the impact of noise. Specifically, we employ kernel filtering based on diffusion maps for pre-filtering the noisy data for training KAN network. Our experiments show that while adding i.i.d. noise with any fixed SNR, when we increase the amount of training data by a factor of $r$, the test-loss (RMSE) of KANs will exhibit a performance trend like $\text{test-loss} \sim \mathcal{O}(r^{-\frac{1}{2}})$ as $r\to +\infty$. We conclude that applying both oversampling and filtering strategies can reduce the detrimental effects of noise. Nevertheless, determining the optimal variance for the kernel filtering process is challenging, and enhancing the volume of training data substantially increases the associated costs, because the training dataset needs to be expanded multiple times in comparison to the initial clean data. As a result, the noise present in the data ultimately diminishes the effectiveness of Kolmogorov-Arnold networks.
Invisible Watermarking for Audio Generation Diffusion Models
Sep 22, 2023Diffusion models have gained prominence in the image domain for their capabilities in data generation and transformation, achieving state-of-the-art performance in various tasks in both image and audio domains. In the rapidly evolving field of audio-based machine learning, safeguarding model integrity and establishing data copyright are of paramount importance. This paper presents the first watermarking technique applied to audio diffusion models trained on mel-spectrograms. This offers a novel approach to the aforementioned challenges. Our model excels not only in benign audio generation, but also incorporates an invisible watermarking trigger mechanism for model verification. This watermark trigger serves as a protective layer, enabling the identification of model ownership and ensuring its integrity. Through extensive experiments, we demonstrate that invisible watermark triggers can effectively protect against unauthorized modifications while maintaining high utility in benign audio generation tasks.
A Multi-Task Semantic Decomposition Framework with Task-specific Pre-training for Few-Shot NER
Aug 28, 2023
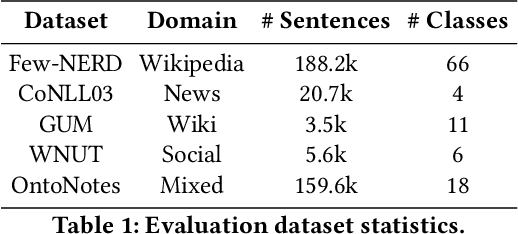
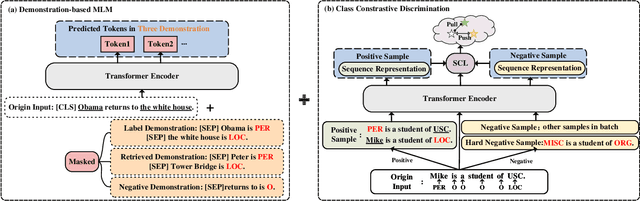

The objective of few-shot named entity recognition is to identify named entities with limited labeled instances. Previous works have primarily focused on optimizing the traditional token-wise classification framework, while neglecting the exploration of information based on NER data characteristics. To address this issue, we propose a Multi-Task Semantic Decomposition Framework via Joint Task-specific Pre-training (MSDP) for few-shot NER. Drawing inspiration from demonstration-based and contrastive learning, we introduce two novel pre-training tasks: Demonstration-based Masked Language Modeling (MLM) and Class Contrastive Discrimination. These tasks effectively incorporate entity boundary information and enhance entity representation in Pre-trained Language Models (PLMs). In the downstream main task, we introduce a multi-task joint optimization framework with the semantic decomposing method, which facilitates the model to integrate two different semantic information for entity classification. Experimental results of two few-shot NER benchmarks demonstrate that MSDP consistently outperforms strong baselines by a large margin. Extensive analyses validate the effectiveness and generalization of MSDP.
FutureTOD: Teaching Future Knowledge to Pre-trained Language Model for Task-Oriented Dialogue
Jun 17, 2023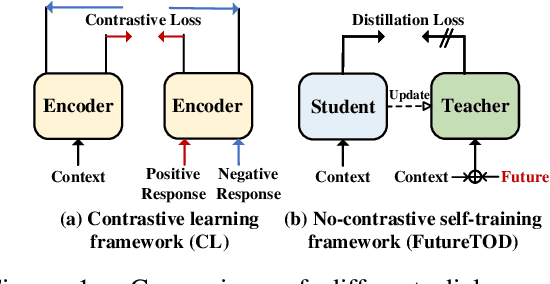
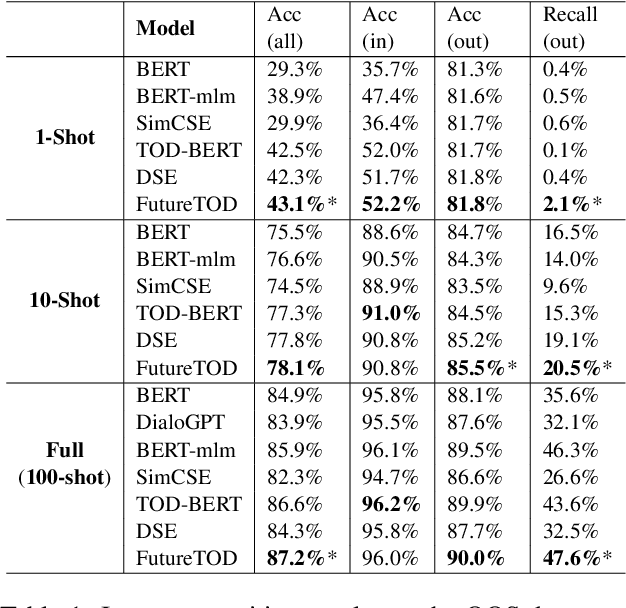
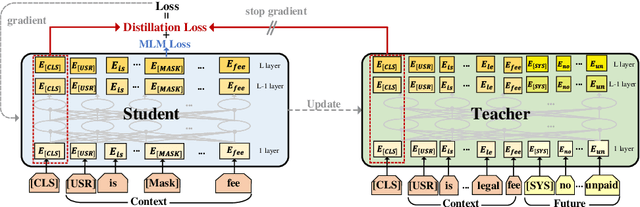
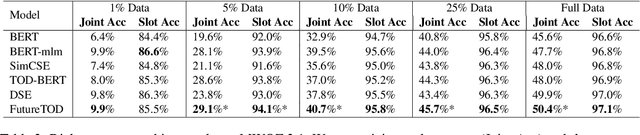
Pre-trained language models based on general text enable huge success in the NLP scenario. But the intrinsical difference of linguistic patterns between general text and task-oriented dialogues makes existing pre-trained language models less useful in practice. Current dialogue pre-training methods rely on a contrastive framework and face the challenges of both selecting true positives and hard negatives. In this paper, we propose a novel dialogue pre-training model, FutureTOD, which distills future knowledge to the representation of the previous dialogue context using a self-training framework. Our intuition is that a good dialogue representation both learns local context information and predicts future information. Extensive experiments on diverse downstream dialogue tasks demonstrate the effectiveness of our model, especially the generalization, robustness, and learning discriminative dialogue representations capabilities.
Decoupling Pseudo Label Disambiguation and Representation Learning for Generalized Intent Discovery
May 28, 2023Generalized intent discovery aims to extend a closed-set in-domain intent classifier to an open-world intent set including in-domain and out-of-domain intents. The key challenges lie in pseudo label disambiguation and representation learning. Previous methods suffer from a coupling of pseudo label disambiguation and representation learning, that is, the reliability of pseudo labels relies on representation learning, and representation learning is restricted by pseudo labels in turn. In this paper, we propose a decoupled prototype learning framework (DPL) to decouple pseudo label disambiguation and representation learning. Specifically, we firstly introduce prototypical contrastive representation learning (PCL) to get discriminative representations. And then we adopt a prototype-based label disambiguation method (PLD) to obtain pseudo labels. We theoretically prove that PCL and PLD work in a collaborative fashion and facilitate pseudo label disambiguation. Experiments and analysis on three benchmark datasets show the effectiveness of our method.
Revisit Out-Of-Vocabulary Problem for Slot Filling: A Unified Contrastive Frameword with Multi-level Data Augmentations
Feb 27, 2023In real dialogue scenarios, the existing slot filling model, which tends to memorize entity patterns, has a significantly reduced generalization facing Out-of-Vocabulary (OOV) problems. To address this issue, we propose an OOV robust slot filling model based on multi-level data augmentations to solve the OOV problem from both word and slot perspectives. We present a unified contrastive learning framework, which pull representations of the origin sample and augmentation samples together, to make the model resistant to OOV problems. We evaluate the performance of the model from some specific slots and carefully design test data with OOV word perturbation to further demonstrate the effectiveness of OOV words. Experiments on two datasets show that our approach outperforms the previous sota methods in terms of both OOV slots and words.
A Prototypical Semantic Decoupling Method via Joint Contrastive Learning for Few-Shot Name Entity Recognition
Feb 27, 2023



Few-shot named entity recognition (NER) aims at identifying named entities based on only few labeled instances. Most existing prototype-based sequence labeling models tend to memorize entity mentions which would be easily confused by close prototypes. In this paper, we proposed a Prototypical Semantic Decoupling method via joint Contrastive learning (PSDC) for few-shot NER. Specifically, we decouple class-specific prototypes and contextual semantic prototypes by two masking strategies to lead the model to focus on two different semantic information for inference. Besides, we further introduce joint contrastive learning objectives to better integrate two kinds of decoupling information and prevent semantic collapse. Experimental results on two few-shot NER benchmarks demonstrate that PSDC consistently outperforms the previous SOTA methods in terms of overall performance. Extensive analysis further validates the effectiveness and generalization of PSDC.
Knowledge from Large-Scale Protein Contact Prediction Models Can Be Transferred to the Data-Scarce RNA Contact Prediction Task
Feb 13, 2023RNA, whose functionality is largely determined by its structure, plays an important role in many biological activities. The prediction of pairwise structural proximity between each nucleotide of an RNA sequence can characterize the structural information of the RNA. Historically, this problem has been tackled by machine learning models using expert-engineered features and trained on scarce labeled datasets. Here, we find that the knowledge learned by a protein-coevolution Transformer-based deep neural network can be transferred to the RNA contact prediction task. As protein datasets are orders of magnitude larger than those for RNA contact prediction, our findings and the subsequent framework greatly reduce the data scarcity bottleneck. Experiments confirm that RNA contact prediction through transfer learning using a publicly available protein model is greatly improved. Our findings indicate that the learned structural patterns of proteins can be transferred to RNAs, opening up potential new avenues for research.