 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndoorR2X: Indoor Robot-to-Everything Coordination with LLM-Driven Planning
Mar 20, 2026Although robot-to-robot (R2R) communication improves indoor scene understanding beyond what a single robot can achieve, R2R alone cannot overcome partial observability without substantial exploration overhead or scaling team size. In contrast, many indoor environments already include low-cost Internet of Things (IoT) sensors (e.g., cameras) that provide persistent, building-wide context beyond onboard perception. We therefore introduce IndoorR2X, the first benchmark and simulation framework for Large Language Model (LLM)-driven multi-robot task planning with Robot-to-Everything (R2X) perception and communication in indoor environments. IndoorR2X integrates observations from mobile robots and static IoT devices to construct a global semantic state that supports scalable scene understanding, reduces redundant exploration, and enables high-level coordination through LLM-based planning. IndoorR2X provides configurable simulation environments, sensor layouts, robot teams, and task suites to systematically evaluate high-level semantic coordination strategies. Extensive experiments across diverse settings demonstrate that IoT-augmented world modeling improves multi-robot efficiency and reliability, and we highlight key insights and failure modes for advancing LLM-based collaboration between robot teams and indoor IoT sensors.
A Talent-infused Policy-gradient Approach to Efficient Co-Design of Morphology and Task Allocation Behavior of Multi-Robot Systems
Nov 27, 2024



Interesting and efficient collective behavior observed in multi-robot or swarm systems emerges from the individual behavior of the robots. The functional space of individual robot behaviors is in turn shaped or constrained by the robot's morphology or physical design. Thus the full potential of multi-robot systems can be realized by concurrently optimizing the morphology and behavior of individual robots, informed by the environment's feedback about their collective performance, as opposed to treating morphology and behavior choices disparately or in sequence (the classical approach). This paper presents an efficient concurrent design or co-design method to explore this potential and understand how morphology choices impact collective behavior, particularly in an MRTA problem focused on a flood response scenario, where the individual behavior is designed via graph reinforcement learning. Computational efficiency in this case is attributed to a new way of near exact decomposition of the co-design problem into a series of simpler optimization and learning problems. This is achieved through i) the identification and use of the Pareto front of Talent metrics that represent morphology-dependent robot capabilities, and ii) learning the selection of Talent best trade-offs and individual robot policy that jointly maximizes the MRTA performance. Applied to a multi-unmanned aerial vehicle flood response use case, the co-design outcomes are shown to readily outperform sequential design baselines. Significant differences in morphology and learned behavior are also observed when comparing co-designed single robot vs. co-designed multi-robot systems for similar operations.
Towards Physically Talented Aerial Robots with Tactically Smart Swarm Behavior thereof: An Efficient Co-design Approach
Jun 24, 2024



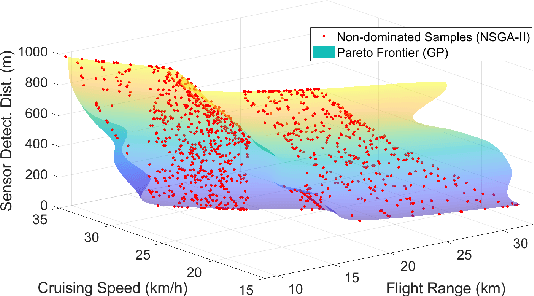
The collective performance or capacity of collaborative autonomous systems such as a swarm of robots is jointly influenced by the morphology and the behavior of individual systems in that collective. In that context, this paper explores how morphology impacts the learned tactical behavior of unmanned aerial/ground robots performing reconnaissance and search & rescue. This is achieved by presenting a computationally efficient framework to solve this otherwise challenging problem of jointly optimizing the morphology and tactical behavior of swarm robots. Key novel developments to this end include the use of physical talent metrics and modification of graph reinforcement learning architectures to allow joint learning of the swarm tactical policy and the talent metrics (search speed, flight range, and cruising speed) that constrain mobility and object/victim search capabilities of the aerial robots executing these tactics. Implementation of this co-design approach is supported by advancements to an open-source Pybullet-based swarm simulator that allows the use of variable aerial asset capabilities. The results of the co-design are observed to outperform those of tactics learning with a fixed Pareto design, when compared in terms of mission performance metrics. Significant differences in morphology and learned behavior are also observed by comparing the baseline design and the co-design outcomes.
Fast Decision Support for Air Traffic Management at Urban Air Mobility Vertiports using Graph Learning
Aug 17, 2023



Urban Air Mobility (UAM) promises a new dimension to decongested, safe, and fast travel in urban and suburban hubs. These UAM aircraft are conceived to operate from small airports called vertiports each comprising multiple take-off/landing and battery-recharging spots. Since they might be situated in dense urban areas and need to handle many aircraft landings and take-offs each hour, managing this schedule in real-time becomes challenging for a traditional air-traffic controller but instead calls for an automated solution. This paper provides a novel approach to this problem of Urban Air Mobility - Vertiport Schedule Management (UAM-VSM), which leverages graph reinforcement learning to generate decision-support policies. Here the designated physical spots within the vertiport's airspace and the vehicles being managed are represented as two separate graphs, with feature extraction performed through a graph convolutional network (GCN). Extracted features are passed onto perceptron layers to decide actions such as continue to hover or cruise, continue idling or take-off, or land on an allocated vertiport spot. Performance is measured based on delays, safety (no. of collisions) and battery consumption. Through realistic simulations in AirSim applied to scaled down multi-rotor vehicles, our results demonstrate the suitability of using graph reinforcement learning to solve the UAM-VSM problem and its superiority to basic reinforcement learning (with graph embeddings) or random choice baselines.
Efficient Concurrent Design of the Morphology of Unmanned Aerial Systems and their Collective-Search Behavior
Sep 26, 2022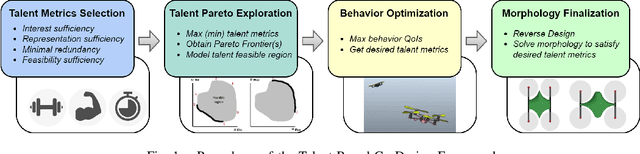
The collective operation of robots, such as unmanned aerial vehicles (UAVs) operating as a team or swarm, is affected by their individual capabilities, which in turn is dependent on their physical design, aka morphology. However, with the exception of a few (albeit ad hoc) evolutionary robotics methods, there has been very little work on understanding the interplay of morphology and collective behavior. There is especially a lack of computational frameworks to concurrently search for the robot morphology and the hyper-parameters of their behavior model that jointly optimize the collective (team) performance. To address this gap, this paper proposes a new co-design framework. Here the exploding computational cost of an otherwise nested morphology/behavior co-design is effectively alleviated through the novel concept of ``talent" metrics; while also allowing significantly better solutions compared to the typically sub-optimal sequential morphology$\to$behavior design approach. This framework comprises four major steps: talent metrics selection, talent Pareto exploration (a multi-objective morphology optimization process), behavior optimization, and morphology finalization. This co-design concept is demonstrated by applying it to design UAVs that operate as a team to localize signal sources, e.g., in victim search and hazard localization. Here, the collective behavior is driven by a recently reported batch Bayesian search algorithm called Bayes-Swarm. Our case studies show that the outcome of co-design provides significantly higher success rates in signal source localization compared to a baseline design, across a variety of signal environments and teams with 6 to 15 UAVs. Moreover, this co-design process provides two orders of magnitude reduction in computing time compared to a projected nested design approach.
Learning Robust Policies for Generalized Debris Capture with an Automated Tether-Net System
Jan 11, 2022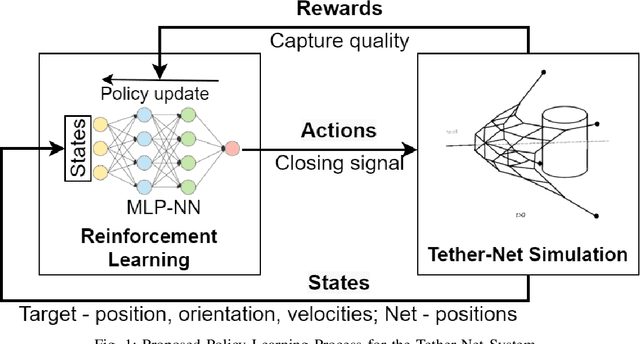
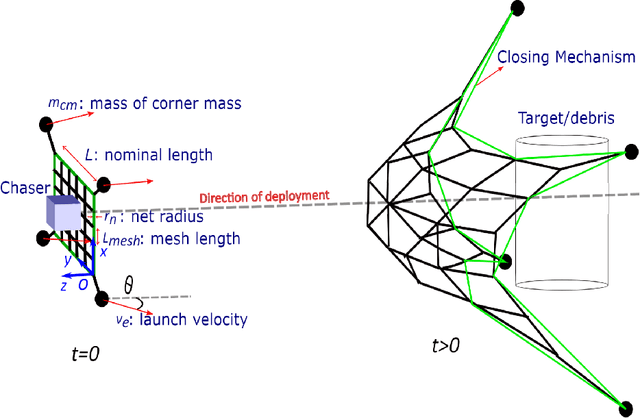

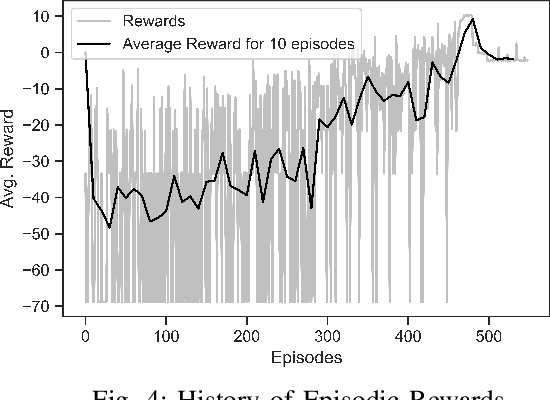
Tether-net launched from a chaser spacecraft provides a promising method to capture and dispose of large space debris in orbit. This tether-net system is subject to several sources of uncertainty in sensing and actuation that affect the performance of its net launch and closing control. Earlier reliability-based optimization approaches to design control actions however remain challenging and computationally prohibitive to generalize over varying launch scenarios and target (debris) state relative to the chaser. To search for a general and reliable control policy, this paper presents a reinforcement learning framework that integrates a proximal policy optimization (PPO2) approach with net dynamics simulations. The latter allows evaluating the episodes of net-based target capture, and estimate the capture quality index that serves as the reward feedback to PPO2. Here, the learned policy is designed to model the timing of the net closing action based on the state of the moving net and the target, under any given launch scenario. A stochastic state transition model is considered in order to incorporate synthetic uncertainties in state estimation and launch actuation. Along with notable reward improvement during training, the trained policy demonstrates capture performance (over a wide range of launch/target scenarios) that is close to that obtained with reliability-based optimization run over an individual scenario.
Learning Robot Swarm Tactics over Complex Adversarial Environments
Sep 13, 2021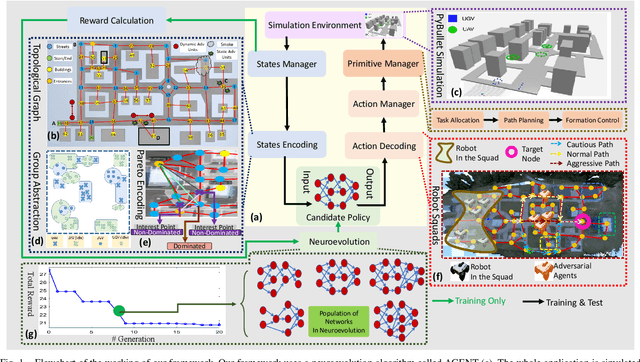
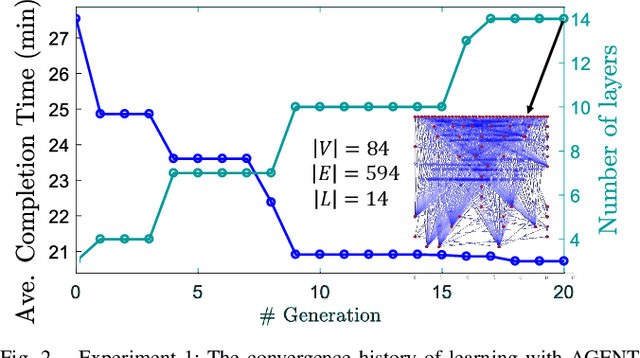
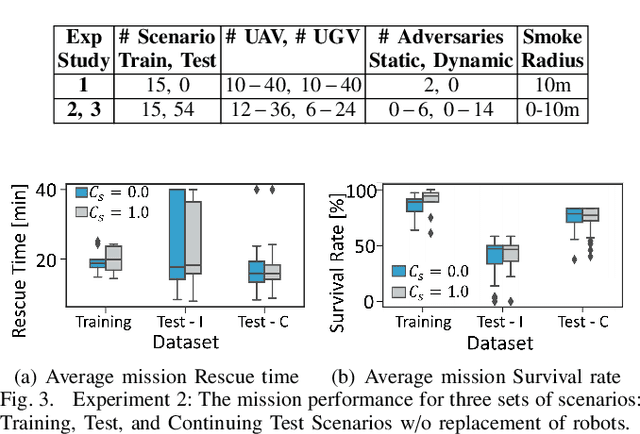
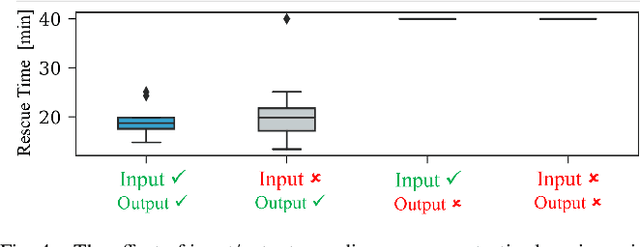
To accomplish complex swarm robotic missions in the real world, one needs to plan and execute a combination of single robot behaviors, group primitives such as task allocation, path planning, and formation control, and mission-specific objectives such as target search and group coverage. Most such missions are designed manually by teams of robotics experts. Recent work in automated approaches to learning swarm behavior has been limited to individual primitives with sparse work on learning complete missions. This paper presents a systematic approach to learn tactical mission-specific policies that compose primitives in a swarm to accomplish the mission efficiently using neural networks with special input and output encoding. To learn swarm tactics in an adversarial environment, we employ a combination of 1) map-to-graph abstraction, 2) input/output encoding via Pareto filtering of points of interest and clustering of robots, and 3) learning via neuroevolution and policy gradient approaches. We illustrate this combination as critical to providing tractable learning, especially given the computational cost of simulating swarm missions of this scale and complexity. Successful mission completion outcomes are demonstrated with up to 60 robots. In addition, a close match in the performance statistics in training and testing scenarios shows the potential generalizability of the proposed framework.