 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Physically Talented Aerial Robots with Tactically Smart Swarm Behavior thereof: An Efficient Co-design Approach
Jun 24, 2024



The collective performance or capacity of collaborative autonomous systems such as a swarm of robots is jointly influenced by the morphology and the behavior of individual systems in that collective. In that context, this paper explores how morphology impacts the learned tactical behavior of unmanned aerial/ground robots performing reconnaissance and search & rescue. This is achieved by presenting a computationally efficient framework to solve this otherwise challenging problem of jointly optimizing the morphology and tactical behavior of swarm robots. Key novel developments to this end include the use of physical talent metrics and modification of graph reinforcement learning architectures to allow joint learning of the swarm tactical policy and the talent metrics (search speed, flight range, and cruising speed) that constrain mobility and object/victim search capabilities of the aerial robots executing these tactics. Implementation of this co-design approach is supported by advancements to an open-source Pybullet-based swarm simulator that allows the use of variable aerial asset capabilities. The results of the co-design are observed to outperform those of tactics learning with a fixed Pareto design, when compared in terms of mission performance metrics. Significant differences in morphology and learned behavior are also observed by comparing the baseline design and the co-design outcomes.
Beyond One Model Fits All: Ensemble Deep Learning for Autonomous Vehicles
Dec 10, 2023



Deep learning has revolutionized autonomous driving by enabling vehicles to perceive and interpret their surroundings with remarkable accuracy. This progress is attributed to various deep learning models, including Mediated Perception, Behavior Reflex, and Direct Perception, each offering unique advantages and challenges in enhancing autonomous driving capabilities. However, there is a gap in research addressing integrating these approaches and understanding their relevance in diverse driving scenarios. This study introduces three distinct neural network models corresponding to Mediated Perception, Behavior Reflex, and Direct Perception approaches. We explore their significance across varying driving conditions, shedding light on the strengths and limitations of each approach. Our architecture fuses information from the base, future latent vector prediction, and auxiliary task networks, using global routing commands to select appropriate action sub-networks. We aim to provide insights into effectively utilizing diverse modeling strategies in autonomous driving by conducting experiments and evaluations. The results show that the ensemble model performs better than the individual approaches, suggesting that each modality contributes uniquely toward the performance of the overall model. Moreover, by exploring the significance of each modality, this study offers a roadmap for future research in autonomous driving, emphasizing the importance of leveraging multiple models to achieve robust performance.
KARNet: Kalman Filter Augmented Recurrent Neural Network for Learning World Models in Autonomous Driving Tasks
May 24, 2023



Autonomous driving has received a great deal of attention in the automotive industry and is often seen as the future of transportation. The development of autonomous driving technology has been greatly accelerated by the growth of end-to-end machine learning techniques that have been successfully used for perception, planning, and control tasks. An important aspect of autonomous driving planning is knowing how the environment evolves in the immediate future and taking appropriate actions. An autonomous driving system should effectively use the information collected from the various sensors to form an abstract representation of the world to maintain situational awareness. For this purpose, deep learning models can be used to learn compact latent representations from a stream of incoming data. However, most deep learning models are trained end-to-end and do not incorporate any prior knowledge (e.g., from physics) of the vehicle in the architecture. In this direction, many works have explored physics-infused neural network (PINN) architectures to infuse physics models during training. Inspired by this observation, we present a Kalman filter augmented recurrent neural network architecture to learn the latent representation of the traffic flow using front camera images only. We demonstrate the efficacy of the proposed model in both imitation and reinforcement learning settings using both simulated and real-world datasets. The results show that incorporating an explicit model of the vehicle (states estimated using Kalman filtering) in the end-to-end learning significantly increases performance.
Effect of Haptic Assistance Strategy on Mental Engagement in Fine Motor Tasks
Mar 16, 2023



This study investigates the effect of haptic control strategies on a subject's mental engagement during a fine motor handwriting rehabilitation task. The considered control strategies include an error-reduction (ER) and an error-augmentation (EA), which are tested on both dominant and non-dominant hand. A non-invasive brain-computer interface is used to monitor the electroencephalogram (EEG) activities of the subjects and evaluate the subject's mental engagement using the power of multiple frequency bands (theta, alpha, and beta). Statistical analysis of the effect of the control strategy on mental engagement revealed that the choice of the haptic control strategy has a significant effect (p < 0.001) on mental engagement depending on the type of hand (dominant or non-dominant). Among the evaluated strategies, EA is shown to be more mentally engaging when compared with the ER under the non-dominant hand.
* 18 Pages, 11 Figures, Journal Pre-print
CARNet: A Dynamic Autoencoder for Learning Latent Dynamics in Autonomous Driving Tasks
May 26, 2022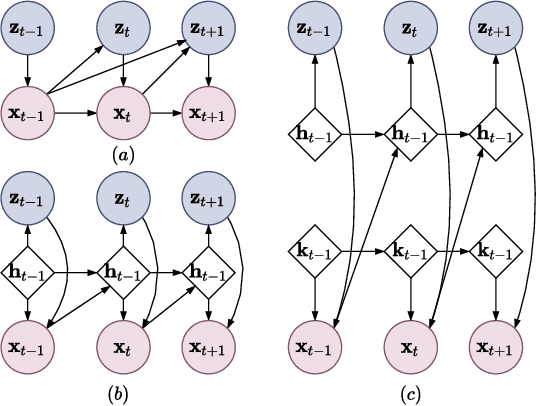
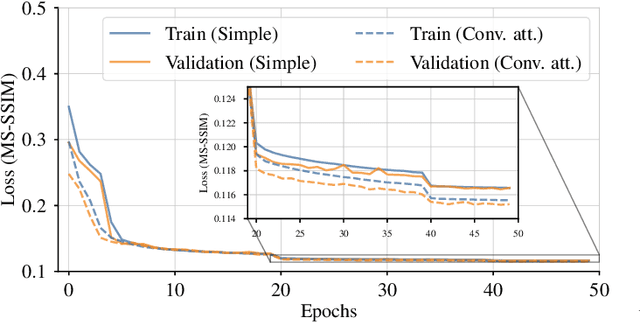


Autonomous driving has received a lot of attention in the automotive industry and is often seen as the future of transportation. Passenger vehicles equipped with a wide array of sensors (e.g., cameras, front-facing radars, LiDARs, and IMUs) capable of continuous perception of the environment are becoming increasingly prevalent. These sensors provide a stream of high-dimensional, temporally correlated data that is essential for reliable autonomous driving. An autonomous driving system should effectively use the information collected from the various sensors in order to form an abstract description of the world and maintain situational awareness. Deep learning models, such as autoencoders, can be used for that purpose, as they can learn compact latent representations from a stream of incoming data. However, most autoencoder models process the data independently, without assuming any temporal interdependencies. Thus, there is a need for deep learning models that explicitly consider the temporal dependence of the data in their architecture. This work proposes CARNet, a Combined dynAmic autoencodeR NETwork architecture that utilizes an autoencoder combined with a recurrent neural network to learn the current latent representation and, in addition, also predict future latent representations in the context of autonomous driving. We demonstrate the efficacy of the proposed model in both imitation and reinforcement learning settings using both simulated and real datasets. Our results show that the proposed model outperforms the baseline state-of-the-art model, while having significantly fewer trainable parameters.
Learning Robot Swarm Tactics over Complex Adversarial Environments
Sep 13, 2021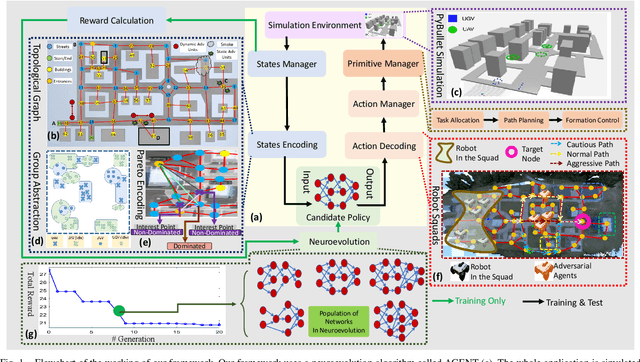
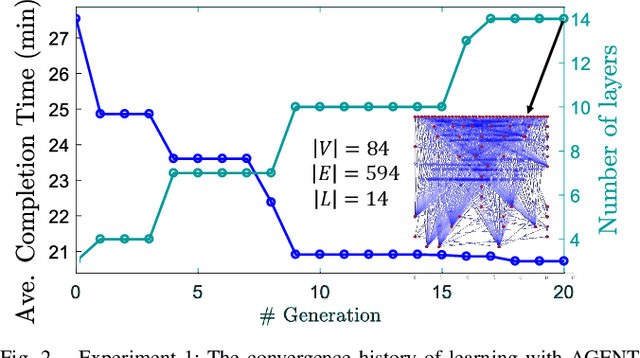
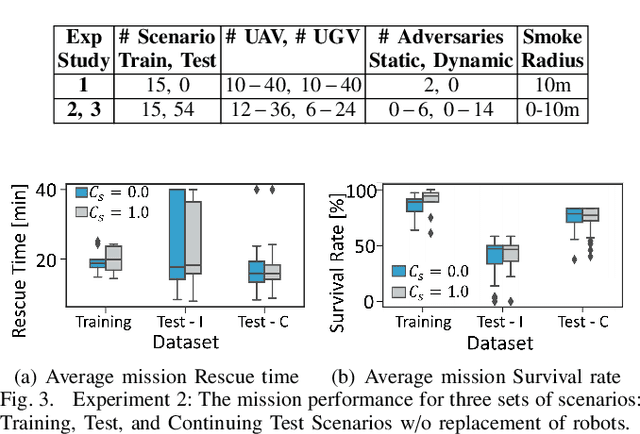
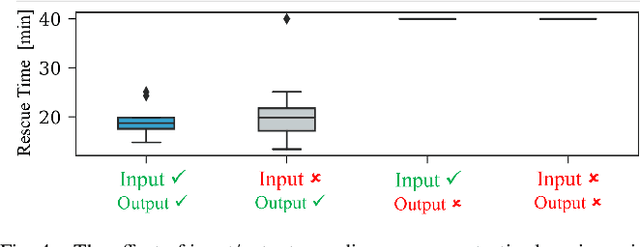
To accomplish complex swarm robotic missions in the real world, one needs to plan and execute a combination of single robot behaviors, group primitives such as task allocation, path planning, and formation control, and mission-specific objectives such as target search and group coverage. Most such missions are designed manually by teams of robotics experts. Recent work in automated approaches to learning swarm behavior has been limited to individual primitives with sparse work on learning complete missions. This paper presents a systematic approach to learn tactical mission-specific policies that compose primitives in a swarm to accomplish the mission efficiently using neural networks with special input and output encoding. To learn swarm tactics in an adversarial environment, we employ a combination of 1) map-to-graph abstraction, 2) input/output encoding via Pareto filtering of points of interest and clustering of robots, and 3) learning via neuroevolution and policy gradient approaches. We illustrate this combination as critical to providing tractable learning, especially given the computational cost of simulating swarm missions of this scale and complexity. Successful mission completion outcomes are demonstrated with up to 60 robots. In addition, a close match in the performance statistics in training and testing scenarios shows the potential generalizability of the proposed framework.
Selective Eye-gaze Augmentation To Enhance Imitation Learning In Atari Games
Dec 05, 2020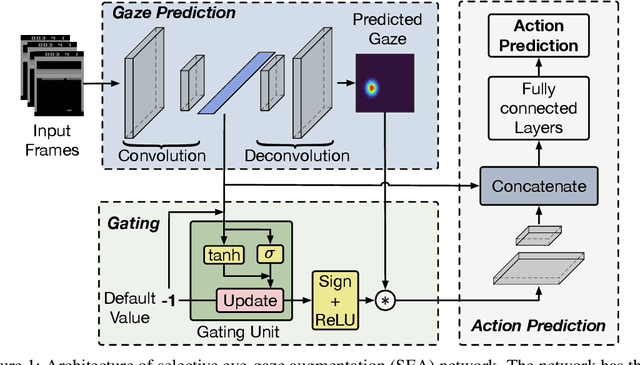


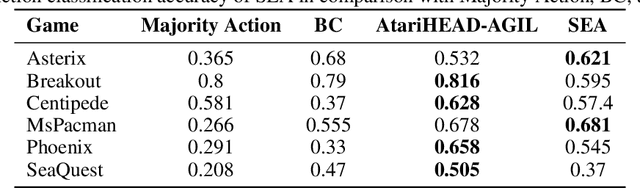
This paper presents the selective use of eye-gaze information in learning human actions in Atari games. Vast evidence suggests that our eye movement convey a wealth of information about the direction of our attention and mental states and encode the information necessary to complete a task. Based on this evidence, we hypothesize that selective use of eye-gaze, as a clue for attention direction, will enhance the learning from demonstration. For this purpose, we propose a selective eye-gaze augmentation (SEA) network that learns when to use the eye-gaze information. The proposed network architecture consists of three sub-networks: gaze prediction, gating, and action prediction network. Using the prior 4 game frames, a gaze map is predicted by the gaze prediction network which is used for augmenting the input frame. The gating network will determine whether the predicted gaze map should be used in learning and is fed to the final network to predict the action at the current frame. To validate this approach, we use publicly available Atari Human Eye-Tracking And Demonstration (Atari-HEAD) dataset consists of 20 Atari games with 28 million human demonstrations and 328 million eye-gazes (over game frames) collected from four subjects. We demonstrate the efficacy of selective eye-gaze augmentation in comparison with state of the art Attention Guided Imitation Learning (AGIL), Behavior Cloning (BC). The results indicate that the selective augmentation approach (the SEA network) performs significantly better than the AGIL and BC. Moreover, to demonstrate the significance of selective use of gaze through the gating network, we compare our approach with the random selection of the gaze. Even in this case, the SEA network performs significantly better validating the advantage of selectively using the gaze in demonstration learning.