 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Scalable Policies over Graphs for Multi-Robot Task Allocation using Capsule Attention Networks
May 06, 2022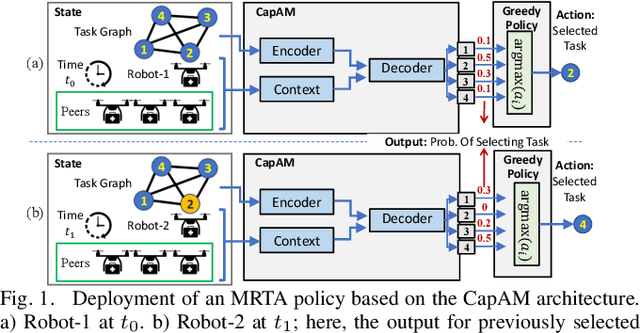
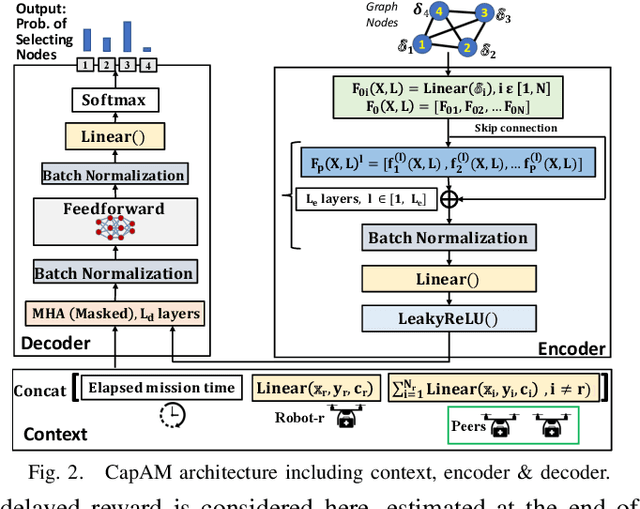
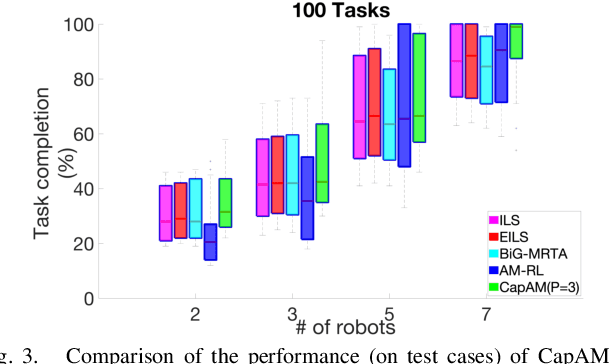
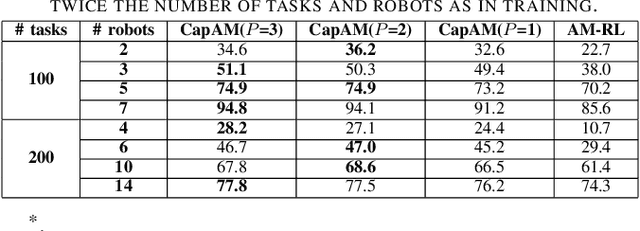
This paper presents a novel graph reinforcement learning (RL) architecture to solve multi-robot task allocation (MRTA) problems that involve tasks with deadlines and workload, and robot constraints such as work capacity. While drawing motivation from recent graph learning methods that learn to solve combinatorial optimization (CO) problems such as multi-Traveling Salesman and Vehicle Routing Problems using RL, this paper seeks to provide better performance (compared to non-learning methods) and important scalability (compared to existing learning architectures) for the stated class of MRTA problems. The proposed neural architecture, called Capsule Attention-based Mechanism or CapAM acts as the policy network, and includes three main components: 1) an encoder: a Capsule Network based node embedding model to represent each task as a learnable feature vector; 2) a decoder: an attention-based model to facilitate a sequential output; and 3) context: that encodes the states of the mission and the robots. To train the CapAM model, the policy-gradient method based on REINFORCE is used. When evaluated over unseen scenarios, CapAM demonstrates better task completion performance and $>$10 times faster decision-making compared to standard non-learning based online MRTA methods. CapAM's advantage in generalizability, and scalability to test problems of size larger than those used in training, are also successfully demonstrated in comparison to a popular approach for learning to solve CO problems, namely the purely attention mechanism.
Learning Robot Swarm Tactics over Complex Adversarial Environments
Sep 13, 2021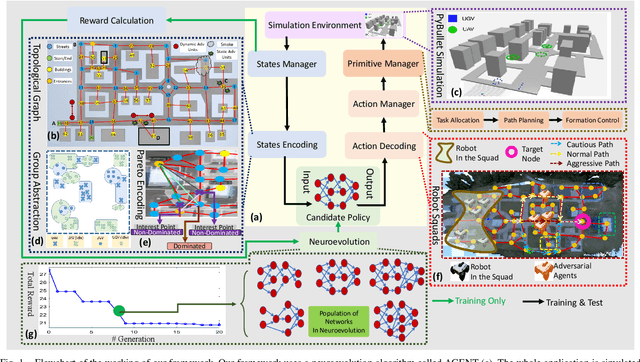
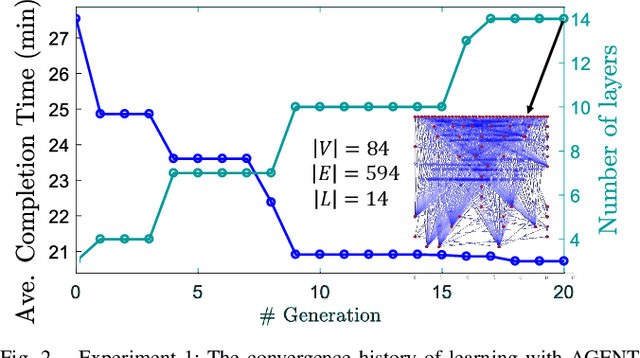
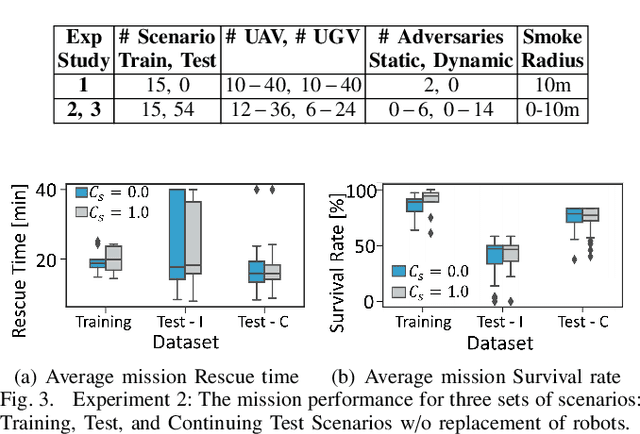
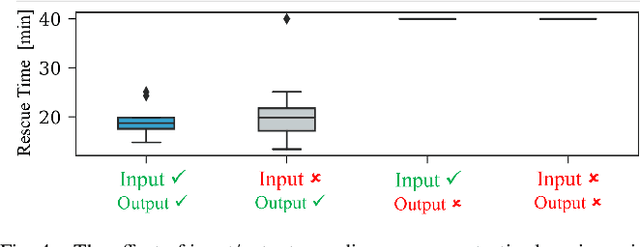
To accomplish complex swarm robotic missions in the real world, one needs to plan and execute a combination of single robot behaviors, group primitives such as task allocation, path planning, and formation control, and mission-specific objectives such as target search and group coverage. Most such missions are designed manually by teams of robotics experts. Recent work in automated approaches to learning swarm behavior has been limited to individual primitives with sparse work on learning complete missions. This paper presents a systematic approach to learn tactical mission-specific policies that compose primitives in a swarm to accomplish the mission efficiently using neural networks with special input and output encoding. To learn swarm tactics in an adversarial environment, we employ a combination of 1) map-to-graph abstraction, 2) input/output encoding via Pareto filtering of points of interest and clustering of robots, and 3) learning via neuroevolution and policy gradient approaches. We illustrate this combination as critical to providing tractable learning, especially given the computational cost of simulating swarm missions of this scale and complexity. Successful mission completion outcomes are demonstrated with up to 60 robots. In addition, a close match in the performance statistics in training and testing scenarios shows the potential generalizability of the proposed framework.
Scalable Coverage Path Planning of Multi-Robot Teams for Monitoring Non-Convex Areas
Mar 26, 2021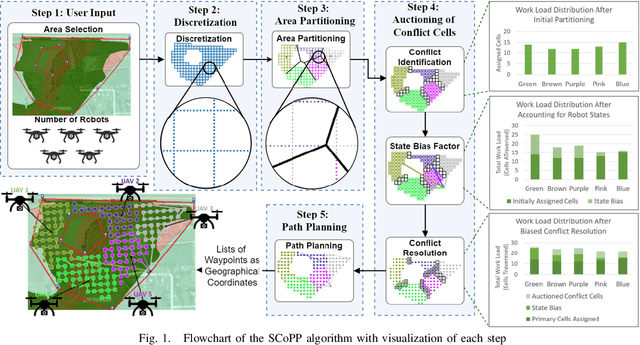

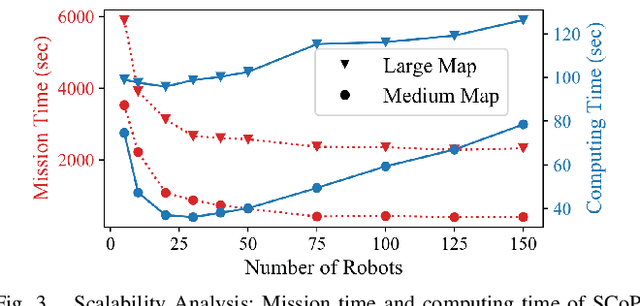
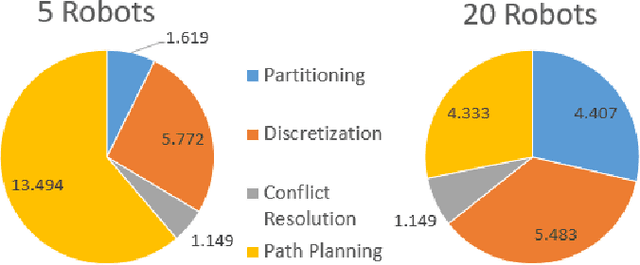
This paper presents a novel multi-robot coverage path planning (CPP) algorithm - aka SCoPP - that provides a time-efficient solution, with workload balanced plans for each robot in a multi-robot system, based on their initial states. This algorithm accounts for discontinuities (e.g., no-fly zones) in a specified area of interest, and provides an optimized ordered list of way-points per robot using a discrete, computationally efficient, nearest neighbor path planning algorithm. This algorithm involves five main stages, which include the transformation of the user's input as a set of vertices in geographical coordinates, discretization, load-balanced partitioning, auctioning of conflict cells in a discretized space, and a path planning procedure. To evaluate the effectiveness of the primary algorithm, a multi-unmanned aerial vehicle (UAV) post-flood assessment application is considered, and the performance of the algorithm is tested on three test maps of varying sizes. Additionally, our method is compared with a state-of-the-art method created by Guasella et al. Further analyses on scalability and computational time of SCoPP are conducted. The results show that SCoPP is superior in terms of mission completion time; its computing time is found to be under 2 mins for a large map covered by a 150-robot team, thereby demonstrating its computationally scalability.
Informative Path Planning with Local Penalization for Decentralized and Asynchronous Swarm Robotic Search
Jul 09, 2019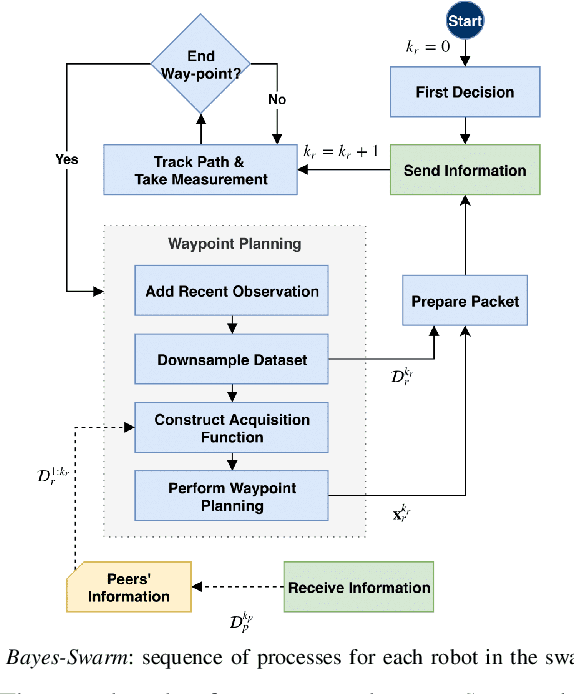
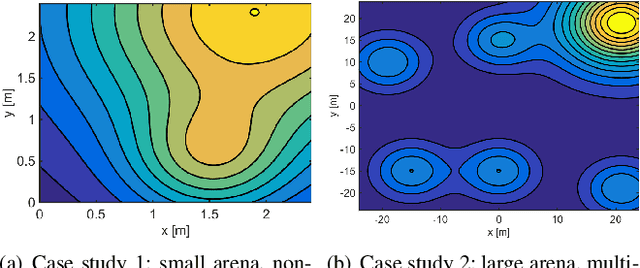
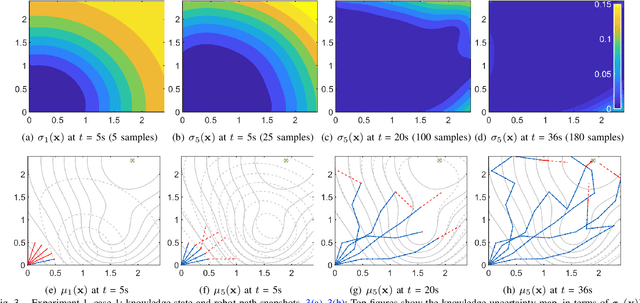
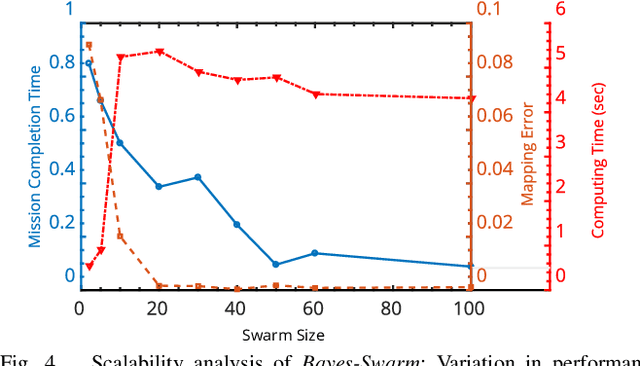
Decentralized swarm robotic solutions to searching for targets that emit a spatially varying signal promise task parallelism, time efficiency, and fault tolerance. It is, however, challenging for swarm algorithms to offer scalability and efficiency, while preserving mathematical insights into the exhibited behavior. A new decentralized search method (called Bayes-Swarm), founded on batch Bayesian Optimization (BO) principles, is presented here to address these challenges. Unlike swarm heuristics approaches, Bayes-Swarm decouples the knowledge generation and task planning process, thus preserving insights into the emergent behavior. Key contributions lie in: 1) modeling knowledge extraction over trajectories, unlike in BO; 2) time-adaptively balancing exploration/exploitation and using an efficient local penalization approach to account for potential interactions among different robots' planned samples; and 3) presenting an asynchronous implementation of the algorithm. This algorithm is tested on case studies with bimodal and highly multimodal signal distributions. Up to 76 times better efficiency is demonstrated compared to an exhaustive search baseline. The benefits of exploitation/exploration balancing, asynchronous planning, and local penalization, and scalability with swarm size, are also demonstrated.
Decentralized Dynamic Task Allocation in Swarm Robotic Systems for Disaster Response
Jul 09, 2019
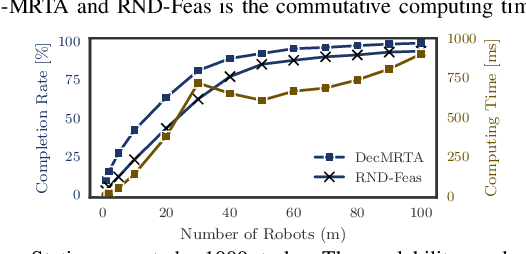
Multiple robotic systems, working together, can provide important solutions to different real-world applications (e.g., disaster response), among which task allocation problems feature prominently. Very few existing decentralized multi-robotic task allocation (MRTA) methods simultaneously offer the following capabilities: consideration of task deadlines, consideration of robot range and task completion capacity limitations, and allowing asynchronous decision-making under dynamic task spaces. To provision these capabilities, this paper presents a computationally efficient algorithm that involves novel construction and matching of bipartite graphs. Its performance is tested on a multi-UAV flood response application.
Adaptive Model Refinement with Batch Bayesian Sampling for Optimization of Bio-inspired Flow Tailoring
May 31, 2019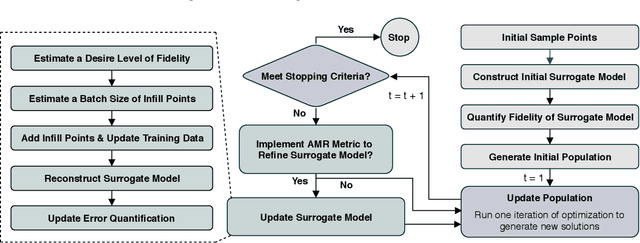
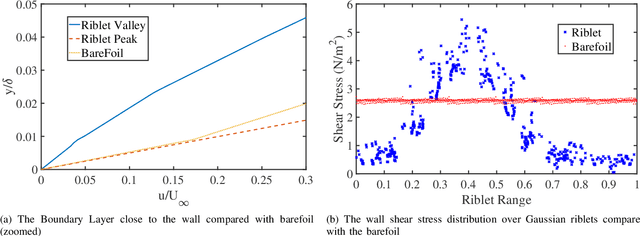
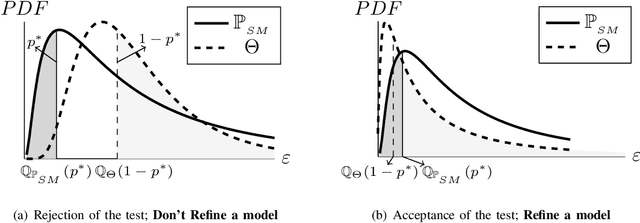
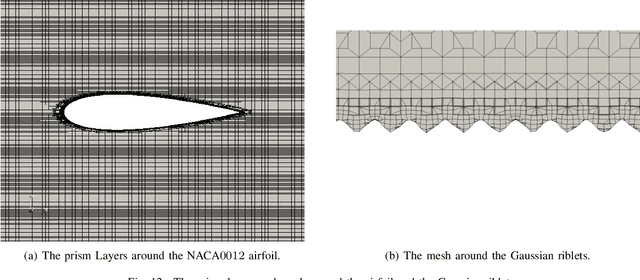
This paper presents an advancement to an approach for model-independent surrogate-based optimization with adaptive batch sampling, known as Adaptive Model Refinement (AMR). While the original AMR method provides unique decisions with regards to "when" to sample and "how many" samples to add (to preserve the credibility of the optimization search process), it did not provide specific direction towards "where" to sample in the design variable space. This paper thus introduces the capability to identify optimum location to add new samples. The location of the infill points is decided by integrating a Gaussian Process-based criteria ("q-EI"), adopted from Bayesian optimization. The consideration of a penalization term to mitigate interaction among samples (in a batch) is crucial to effective integration of the q-EI criteria into AMR. The new AMR method, called AMR with Penalized Batch Bayesian Sampling (AMR-PBS) is tested on benchmark functions, demonstrating better performance compared to Bayesian EGO. In addition, it is successfully applied to design surface riblets for bio-inspired passive flow control (where high-fidelity samples are given by costly RANS CFD simulations), leading to a 10% drag reduction over the corresponding baseline (i.e., riblet-free aerodynamic surface).
Decentralized Informative Path Planning with Exploration-Exploitation Balance for Swarm Robotic Search
May 31, 2019
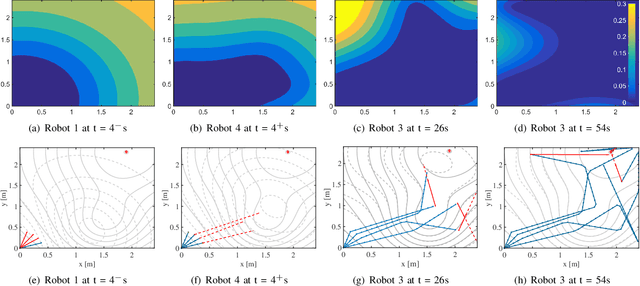


Swarm robotic search is concerned with searching targets in unknown environments (e.g., for search and rescue or hazard localization), using a large number of collaborating simple mobile robots. In such applications, decentralized swarm systems are touted for their task/coverage scalability, time efficiency, and fault tolerance. To guide the behavior of such swarm systems, two broad classes of approaches are available, namely nature-inspired swarm heuristics and multi-robotic search methods. However, simultaneously offering computationally-efficient scalability and fundamental insights into the exhibited behavior (instead of a black-box behavior model), remains challenging under either of these two class of approaches. In this paper, we develop an important extension of the batch Bayesian search method for application to embodied swarm systems, searching in a physical 2D space. Key contributions lie in: 1) designing an acquisition function that not only balances exploration and exploitation across the swarm, but also allows modeling knowledge extraction over trajectories; and 2) developing its distributed implementation to allow asynchronous task inference and path planning by the swarm robots. The resulting collective informative path planning approach is tested on target search case studies of varying complexity, where the target produces a spatially varying (measurable) signal. Significantly superior performance, in terms of mission completion efficiency, is observed compared to exhaustive search and random walk baselines, along with favorable performance scalability with increasing swarm size.
Decentralized Task Allocation in Multi-Robot Systems via Bipartite Graph Matching Augmented with Fuzzy Clustering
Jul 20, 2018



Robotic systems, working together as a team, are becoming valuable players in different real-world applications, from disaster response to warehouse fulfillment services. Centralized solutions for coordinating multi-robot teams often suffer from poor scalability and vulnerability to communication disruptions. This paper develops a decentralized multi-agent task allocation (Dec-MATA) algorithm for multi-robot applications. The task planning problem is posed as a maximum-weighted matching of a bipartite graph, the solution of which using the blossom algorithm allows each robot to autonomously identify the optimal sequence of tasks it should undertake. The graph weights are determined based on a soft clustering process, which also plays a problem decomposition role seeking to reduce the complexity of the individual-agents' task assignment problems. To evaluate the new Dec-MATA algorithm, a series of case studies (of varying complexity) are performed, with tasks being distributed randomly over an observable 2D environment. A centralized approach, based on a state-of-the-art MILP formulation of the multi-Traveling Salesman problem is used for comparative analysis. While getting within 7-28% of the optimal cost obtained by the centralized algorithm, the Dec-MATA algorithm is found to be 1-3 orders of magnitude faster and minimally sensitive to task-to-robot ratios, unlike the centralized algorithm.