 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Talent-infused Policy-gradient Approach to Efficient Co-Design of Morphology and Task Allocation Behavior of Multi-Robot Systems
Nov 27, 2024



Interesting and efficient collective behavior observed in multi-robot or swarm systems emerges from the individual behavior of the robots. The functional space of individual robot behaviors is in turn shaped or constrained by the robot's morphology or physical design. Thus the full potential of multi-robot systems can be realized by concurrently optimizing the morphology and behavior of individual robots, informed by the environment's feedback about their collective performance, as opposed to treating morphology and behavior choices disparately or in sequence (the classical approach). This paper presents an efficient concurrent design or co-design method to explore this potential and understand how morphology choices impact collective behavior, particularly in an MRTA problem focused on a flood response scenario, where the individual behavior is designed via graph reinforcement learning. Computational efficiency in this case is attributed to a new way of near exact decomposition of the co-design problem into a series of simpler optimization and learning problems. This is achieved through i) the identification and use of the Pareto front of Talent metrics that represent morphology-dependent robot capabilities, and ii) learning the selection of Talent best trade-offs and individual robot policy that jointly maximizes the MRTA performance. Applied to a multi-unmanned aerial vehicle flood response use case, the co-design outcomes are shown to readily outperform sequential design baselines. Significant differences in morphology and learned behavior are also observed when comparing co-designed single robot vs. co-designed multi-robot systems for similar operations.
A Graph-based Adversarial Imitation Learning Framework for Reliable & Realtime Fleet Scheduling in Urban Air Mobility
Jul 16, 2024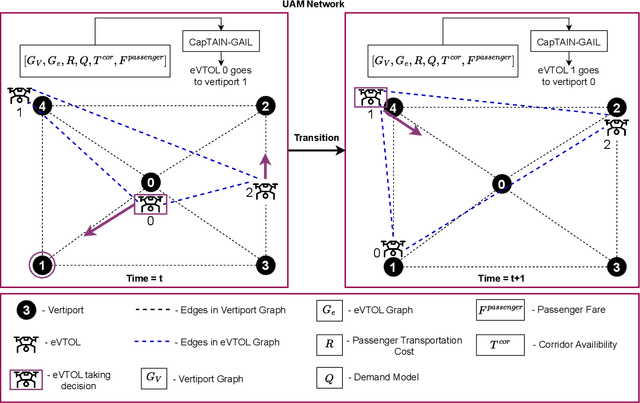
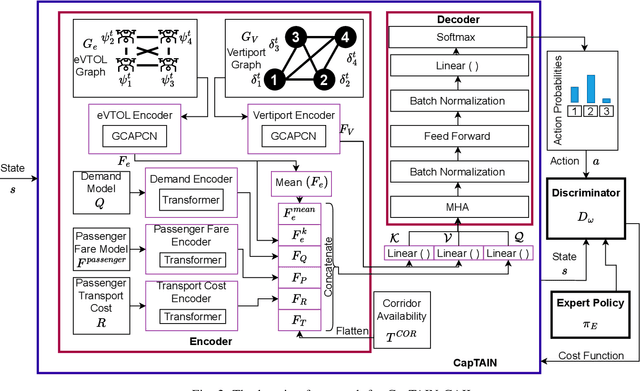
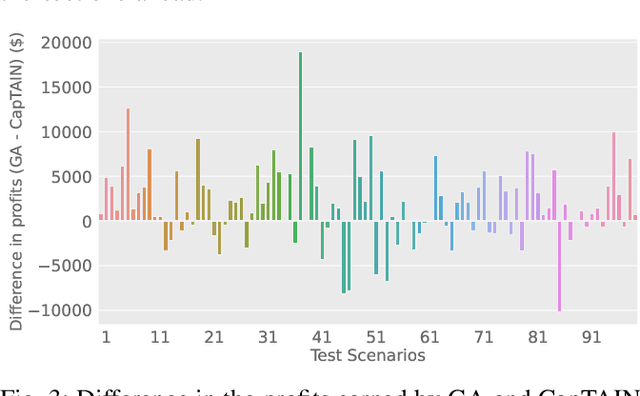
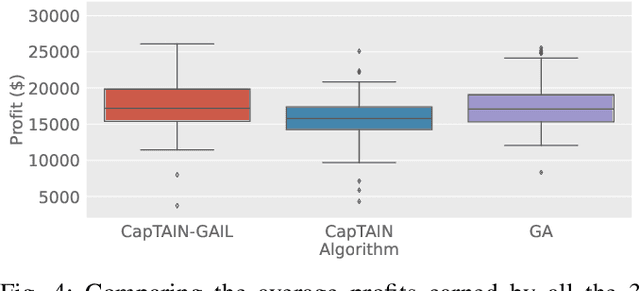
The advent of Urban Air Mobility (UAM) presents the scope for a transformative shift in the domain of urban transportation. However, its widespread adoption and economic viability depends in part on the ability to optimally schedule the fleet of aircraft across vertiports in a UAM network, under uncertainties attributed to airspace congestion, changing weather conditions, and varying demands. This paper presents a comprehensive optimization formulation of the fleet scheduling problem, while also identifying the need for alternate solution approaches, since directly solving the resulting integer nonlinear programming problem is computationally prohibitive for daily fleet scheduling. Previous work has shown the effectiveness of using (graph) reinforcement learning (RL) approaches to train real-time executable policy models for fleet scheduling. However, such policies can often be brittle on out-of-distribution scenarios or edge cases. Moreover, training performance also deteriorates as the complexity (e.g., number of constraints) of the problem increases. To address these issues, this paper presents an imitation learning approach where the RL-based policy exploits expert demonstrations yielded by solving the exact optimization using a Genetic Algorithm. The policy model comprises Graph Neural Network (GNN) based encoders that embed the space of vertiports and aircraft, Transformer networks to encode demand, passenger fare, and transport cost profiles, and a Multi-head attention (MHA) based decoder. Expert demonstrations are used through the Generative Adversarial Imitation Learning (GAIL) algorithm. Interfaced with a UAM simulation environment involving 8 vertiports and 40 aircrafts, in terms of the daily profits earned reward, the new imitative approach achieves better mean performance and remarkable improvement in the case of unseen worst-case scenarios, compared to pure RL results.
Towards Physically Talented Aerial Robots with Tactically Smart Swarm Behavior thereof: An Efficient Co-design Approach
Jun 24, 2024



The collective performance or capacity of collaborative autonomous systems such as a swarm of robots is jointly influenced by the morphology and the behavior of individual systems in that collective. In that context, this paper explores how morphology impacts the learned tactical behavior of unmanned aerial/ground robots performing reconnaissance and search & rescue. This is achieved by presenting a computationally efficient framework to solve this otherwise challenging problem of jointly optimizing the morphology and tactical behavior of swarm robots. Key novel developments to this end include the use of physical talent metrics and modification of graph reinforcement learning architectures to allow joint learning of the swarm tactical policy and the talent metrics (search speed, flight range, and cruising speed) that constrain mobility and object/victim search capabilities of the aerial robots executing these tactics. Implementation of this co-design approach is supported by advancements to an open-source Pybullet-based swarm simulator that allows the use of variable aerial asset capabilities. The results of the co-design are observed to outperform those of tactics learning with a fixed Pareto design, when compared in terms of mission performance metrics. Significant differences in morphology and learned behavior are also observed by comparing the baseline design and the co-design outcomes.
Bigraph Matching Weighted with Learnt Incentive Function for Multi-Robot Task Allocation
Mar 11, 2024



Most real-world Multi-Robot Task Allocation (MRTA) problems require fast and efficient decision-making, which is often achieved using heuristics-aided methods such as genetic algorithms, auction-based methods, and bipartite graph matching methods. These methods often assume a form that lends better explainability compared to an end-to-end (learnt) neural network based policy for MRTA. However, deriving suitable heuristics can be tedious, risky and in some cases impractical if problems are too complex. This raises the question: can these heuristics be learned? To this end, this paper particularly develops a Graph Reinforcement Learning (GRL) framework to learn the heuristics or incentives for a bipartite graph matching approach to MRTA. Specifically a Capsule Attention policy model is used to learn how to weight task/robot pairings (edges) in the bipartite graph that connects the set of tasks to the set of robots. The original capsule attention network architecture is fundamentally modified by adding encoding of robots' state graph, and two Multihead Attention based decoders whose output are used to construct a LogNormal distribution matrix from which positive bigraph weights can be drawn. The performance of this new bigraph matching approach augmented with a GRL-derived incentive is found to be at par with the original bigraph matching approach that used expert-specified heuristics, with the former offering notable robustness benefits. During training, the learned incentive policy is found to get initially closer to the expert-specified incentive and then slightly deviate from its trend.
Graph Learning-based Fleet Scheduling for Urban Air Mobility under Operational Constraints, Varying Demand & Uncertainties
Jan 09, 2024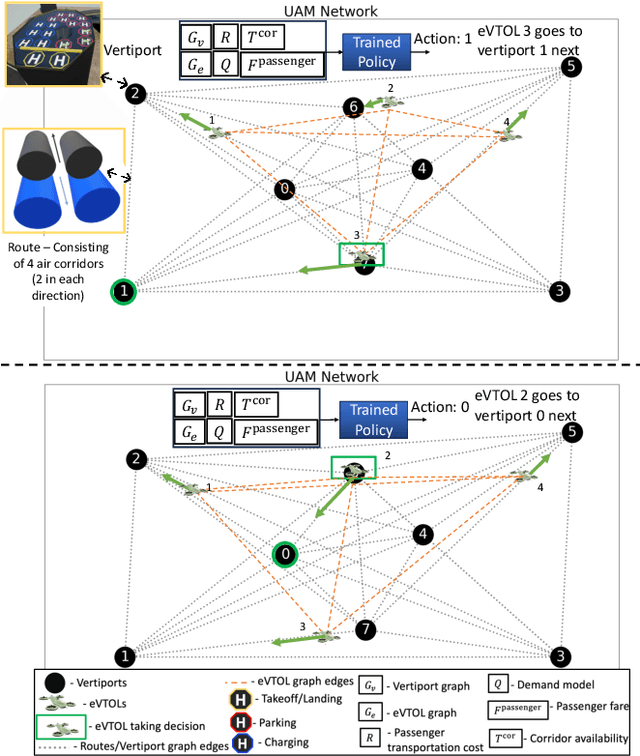
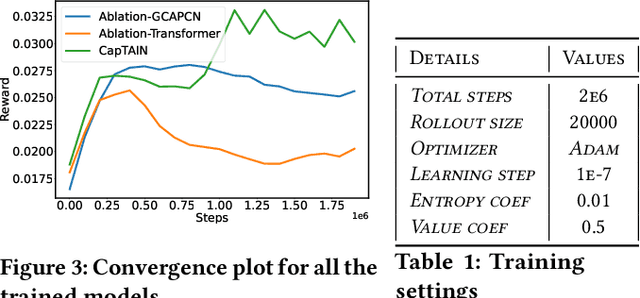
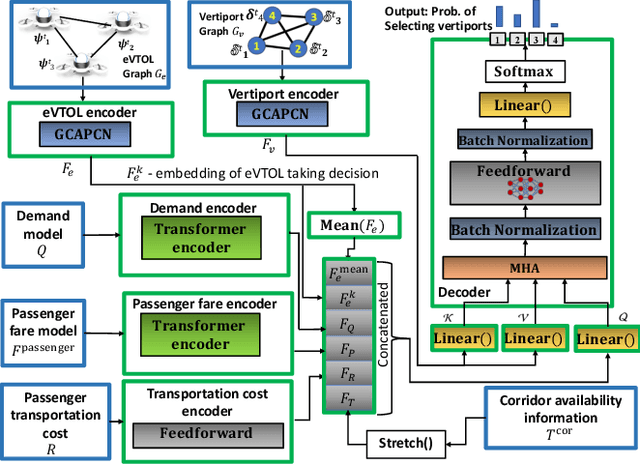

This paper develops a graph reinforcement learning approach to online planning of the schedule and destinations of electric aircraft that comprise an urban air mobility (UAM) fleet operating across multiple vertiports. This fleet scheduling problem is formulated to consider time-varying demand, constraints related to vertiport capacity, aircraft capacity and airspace safety guidelines, uncertainties related to take-off delay, weather-induced route closures, and unanticipated aircraft downtime. Collectively, such a formulation presents greater complexity, and potentially increased realism, than in existing UAM fleet planning implementations. To address these complexities, a new policy architecture is constructed, primary components of which include: graph capsule conv-nets for encoding vertiport and aircraft-fleet states both abstracted as graphs; transformer layers encoding time series information on demand and passenger fare; and a Multi-head Attention-based decoder that uses the encoded information to compute the probability of selecting each available destination for an aircraft. Trained with Proximal Policy Optimization, this policy architecture shows significantly better performance in terms of daily averaged profits on unseen test scenarios involving 8 vertiports and 40 aircraft, when compared to a random baseline and genetic algorithm-derived optimal solutions, while being nearly 1000 times faster in execution than the latter.
Fast Decision Support for Air Traffic Management at Urban Air Mobility Vertiports using Graph Learning
Aug 17, 2023



Urban Air Mobility (UAM) promises a new dimension to decongested, safe, and fast travel in urban and suburban hubs. These UAM aircraft are conceived to operate from small airports called vertiports each comprising multiple take-off/landing and battery-recharging spots. Since they might be situated in dense urban areas and need to handle many aircraft landings and take-offs each hour, managing this schedule in real-time becomes challenging for a traditional air-traffic controller but instead calls for an automated solution. This paper provides a novel approach to this problem of Urban Air Mobility - Vertiport Schedule Management (UAM-VSM), which leverages graph reinforcement learning to generate decision-support policies. Here the designated physical spots within the vertiport's airspace and the vehicles being managed are represented as two separate graphs, with feature extraction performed through a graph convolutional network (GCN). Extracted features are passed onto perceptron layers to decide actions such as continue to hover or cruise, continue idling or take-off, or land on an allocated vertiport spot. Performance is measured based on delays, safety (no. of collisions) and battery consumption. Through realistic simulations in AirSim applied to scaled down multi-rotor vehicles, our results demonstrate the suitability of using graph reinforcement learning to solve the UAM-VSM problem and its superiority to basic reinforcement learning (with graph embeddings) or random choice baselines.
Efficient Planning of Multi-Robot Collective Transport using Graph Reinforcement Learning with Higher Order Topological Abstraction
Mar 15, 2023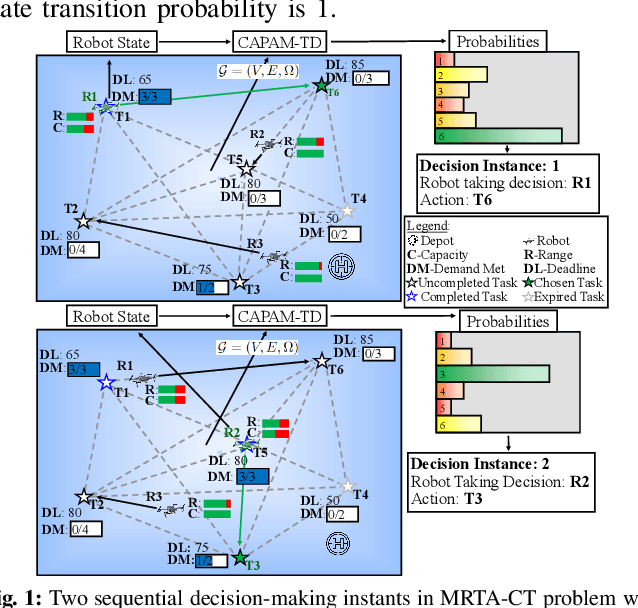
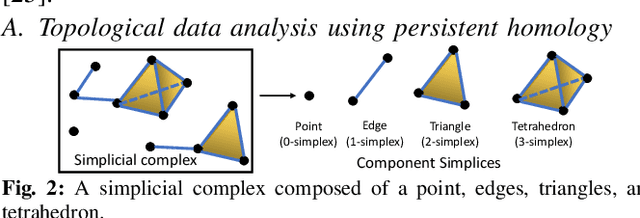

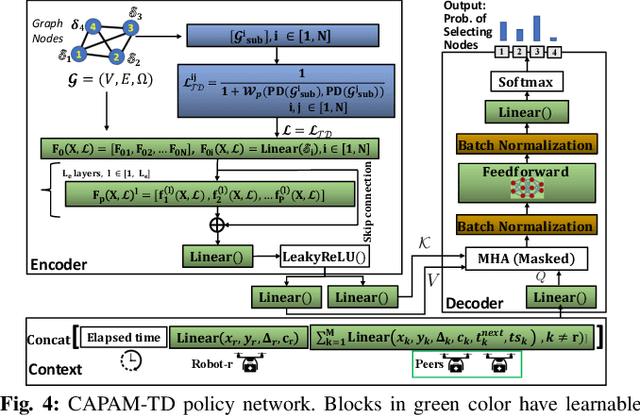
Efficient multi-robot task allocation (MRTA) is fundamental to various time-sensitive applications such as disaster response, warehouse operations, and construction. This paper tackles a particular class of these problems that we call MRTA-collective transport or MRTA-CT -- here tasks present varying workloads and deadlines, and robots are subject to flight range, communication range, and payload constraints. For large instances of these problems involving 100s-1000's of tasks and 10s-100s of robots, traditional non-learning solvers are often time-inefficient, and emerging learning-based policies do not scale well to larger-sized problems without costly retraining. To address this gap, we use a recently proposed encoder-decoder graph neural network involving Capsule networks and multi-head attention mechanism, and innovatively add topological descriptors (TD) as new features to improve transferability to unseen problems of similar and larger size. Persistent homology is used to derive the TD, and proximal policy optimization is used to train our TD-augmented graph neural network. The resulting policy model compares favorably to state-of-the-art non-learning baselines while being much faster. The benefit of using TD is readily evident when scaling to test problems of size larger than those used in training.
Learning Scalable Policies over Graphs for Multi-Robot Task Allocation using Capsule Attention Networks
May 06, 2022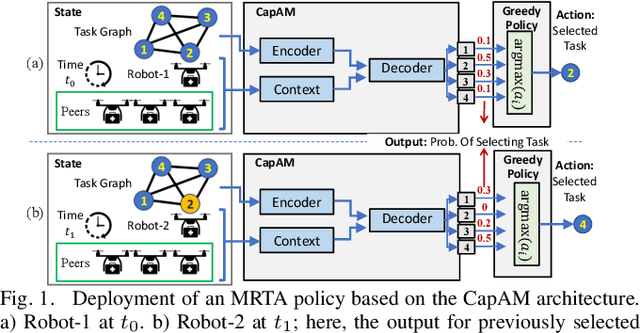
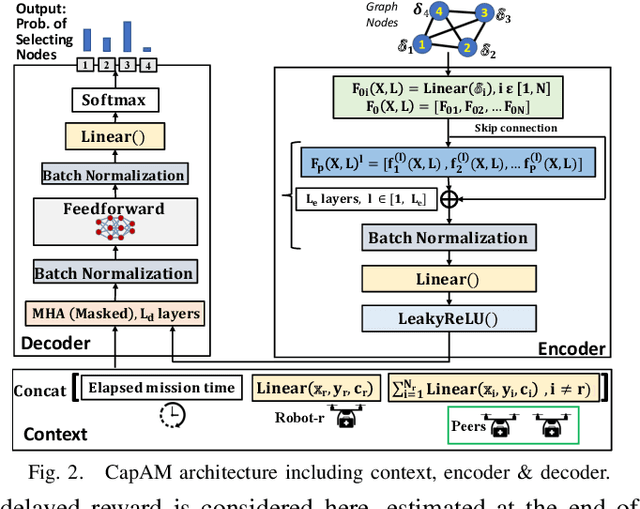
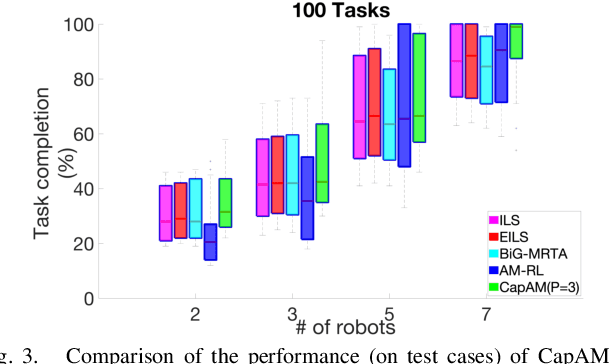
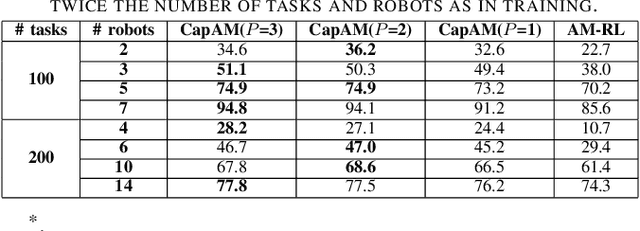
This paper presents a novel graph reinforcement learning (RL) architecture to solve multi-robot task allocation (MRTA) problems that involve tasks with deadlines and workload, and robot constraints such as work capacity. While drawing motivation from recent graph learning methods that learn to solve combinatorial optimization (CO) problems such as multi-Traveling Salesman and Vehicle Routing Problems using RL, this paper seeks to provide better performance (compared to non-learning methods) and important scalability (compared to existing learning architectures) for the stated class of MRTA problems. The proposed neural architecture, called Capsule Attention-based Mechanism or CapAM acts as the policy network, and includes three main components: 1) an encoder: a Capsule Network based node embedding model to represent each task as a learnable feature vector; 2) a decoder: an attention-based model to facilitate a sequential output; and 3) context: that encodes the states of the mission and the robots. To train the CapAM model, the policy-gradient method based on REINFORCE is used. When evaluated over unseen scenarios, CapAM demonstrates better task completion performance and $>$10 times faster decision-making compared to standard non-learning based online MRTA methods. CapAM's advantage in generalizability, and scalability to test problems of size larger than those used in training, are also successfully demonstrated in comparison to a popular approach for learning to solve CO problems, namely the purely attention mechanism.