 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning-based Directed Graph Abstraction of Combinatorial Spaces for Order-Preserving Search in Mixed-Combinatorial Nonlinear Optimization
May 31, 2026Mixed-combinatorial nonlinear programming (MCNLP) problems arise in many engineering design and planning applications, e.g., due to categorical, component, and geometric design choices, as well as joint task and motion planning. Traditional representations of combinatorial spaces, such as integer or binary encoding, often introduce spurious relations, increase dimensionality, and require additional compatibility constraints. Instead, this paper draws on recent developments in robot planning and vehicle/network routing domains that aim to learn search heuristics over combinatorial spaces using graph neural networks (GNNs). More specifically, this paper presents a first-of-its-kind structured abstraction of the combinatorial space by learning a mapping from an undirected fully connected graph of combinations to a directed graph indicating improvement directions using an Edge Field Graph Network (EFGN). To demonstrate the utility of this new way of abstracting the combinatorial space in solving MCNLPs, we adopt a recent optimization framework that purely searches over the non-combinatorial (e.g., continuous) variables and retrieves the best-suited combination for each candidate design by using the abstraction model, akin to a recommender system. The presented direction-aware abstraction model provides a potentially more scalable and interpretable retrieval of combinations compared to the original recommendation system in that framework. For evaluation, the proposed method is integrated with a well-known particle swarm optimization and genetic algorithm solvers on three benchmark nonlinear problems with varying numbers of combinations and variables. Compared to baseline solvers using indexified combinations, the GNN-based recommender consistently achieves better mean optimum values and robustness across multiple runs.
Designing Active Tether-Net Systems for Space Debris Capture with Graph-Learning-Aided Mixed-Combinatorial Optimization
May 27, 2026Active tether-net systems are a promising solution for capturing large non-cooperative targets, such as space debris, by deploying a flexible net manipulated by maneuverable units (MUs). However, concurrent systematic explorations of design and control choices of the tether-net system to understand its full potential remain limited, partly due to the complex, constrained, nonlinear optimization problem that it presents -- one that involves a mixture of continuous, integer and categorical variables, with the latter two arising from net connectivity and component choices, respectively. Classical binary encoding methods are often ineffective for solving highly nonlinear and multimodal Mixed Combinatorial Nonlinear Programmings (MCNLPs) in engineering design, while integer coding approaches can introduce spurious relations among combinations. Given the graph-structured characteristics of the combinatorial space, this paper adopts and extends a new graph-learning-aided optimization approach to solve this MCNLP problem. Here, a Graph Neural Network (GNN) is trained to score (as output) and thereof recommend candidate combinations represented as nodes in a graph, with the continuous variable vector portion of a candidate design given as input. As a result, the MCNLP optimization reduces to an NLP, which can be solved using standard solvers. While this reduction approach is agnostic to the choice of the NLP solver, here a state-of-the-art Particle Swarm Optimization (PSO) algorithm with gradient-based fine-tuning is used as the solver. Demonstrated on the problem of concurrently designing the morphology of the net, choice of mass and thrusters in the MUs and aiming points used by the controller of the tether-net system, the GNN-based recommender is shown to provide significantly faster convergence to similar optimal solutions, compared to direct solution of the MCNLP problem.
Faster Thermal Profiling of a Lunar Rover with Machine Learning Adapted Finite Difference Model
May 26, 2026Autonomous space systems operating in extreme thermal environments require accurate and efficient thermal modeling to support both pre-mission system design and onboard autonomy. For lunar rovers, large temperature gradients, radiative heat transfer, and variable surface conditions make reliable thermal prediction especially challenging. High-fidelity physics-based simulations provide accurate results but are computationally expensive, while simplified models and lookup-table approach often lack sufficient accuracy. Physics-informed machine learning (PIML) offers a promising alternative by combining data-driven models with embedded physical knowledge. This paper presents a PIML framework for thermal analysis of a simplified lunar rover with internal heat sources, where machine learning enables environment-adaptive coarse meshing. The proposed architecture integrates a transfer neural network (TNN) that adaptively determines 3D finite-difference nodalization based on thermal loads and initial conditions, enabling more accurate coarse-mesh calculations. A differentiable finite-difference thermal simulator is embedded within the framework to enforce physical consistency and support efficient training, while an upscaling layer reconstructs high-resolution temperature fields from the coarse-grid solution. The proposed PIML approach is evaluated against high-fidelity fine-mesh simulations, low-fidelity fixed coarse-mesh models, and a purely data-driven artificial neural network (ANN). Results show that the PIML framework improves prediction accuracy by 50% and 39% relative to the coarse-mesh physics model and ANN model, respectively, while maintaining physically consistent thermal distributions. Computationally, the framework is also 3x faster than high-fidelity simulations, demonstrating an effective balance between accuracy and efficiency for thermal modeling of lunar rover systems.
Multi-Robot Box Transport over Different Surfaces with Decentralized Role-based Proportional Control
May 26, 2026Collaborative transport of objects via pushing by multiple robots has many applications, ranging from construction and warehouse environments to post disaster debris clean-up. Achieving collaborative transport over surfaces with different inclination and friction properties however poses unique challenges. To address these challenges, this paper presents an asynchronous decentralized task and motion planning approach for transporting rectangular boxes of varying mass over flat, uphill and downhill terrain. Such a decentralized approach alleviates communication, synchronization and consensus needs and mitigates single point of failure issues. Our approach, called R2P2 or Roles with Rules and Proportional-control Primitive, assigns roles (e.g., push, support and prevent) to robots based on rules cognizant of the mode of manipulation needed (box rotation vs translation); this is followed by either rule-based control or proportional control of robot velocity based on the roles. Each robot is assumed to observe the location and heading of self and the box in executing the role and controls. R2P2 is evaluated with a six-robot team deployed in a simulator built using NVIDIA IsaacSim -- demonstrating generalizability across different surface friction/inclination and box mass scenarios, and better success rate compared to a standard virtual-leader-follower method. R2P2 is also successfully validated with a physical experiment, where it is executed onboard four turtlebots tasked with moving a 1.2 kg box.
Learning When to Jump for Off-road Navigation
Jan 31, 2026Low speed does not always guarantee safety in off-road driving. For instance, crossing a ditch may be risky at a low speed due to the risk of getting stuck, yet safe at a higher speed with a controlled, accelerated jump. Achieving such behavior requires path planning that explicitly models complex motion dynamics, whereas existing methods often neglect this aspect and plan solely based on positions or a fixed velocity. To address this gap, we introduce Motion-aware Traversability (MAT) representation to explicitly model terrain cost conditioned on actual robot motion. Instead of assigning a single scalar score for traversability, MAT models each terrain region as a Gaussian function of velocity. During online planning, we decompose the terrain cost computation into two stages: (1) predict terrain-dependent Gaussian parameters from perception in a single forward pass, (2) efficiently update terrain costs for new velocities inferred from current dynamics by evaluating these functions without repeated inference. We develop a system that integrates MAT to enable agile off-road navigation and evaluate it in both simulated and real-world environments with various obstacles. Results show that MAT achieves real-time efficiency and enhances the performance of off-road navigation, reducing path detours by 75% while maintaining safety across challenging terrains.
CLEAR: A Semantic-Geometric Terrain Abstraction for Large-Scale Unstructured Environments
Jan 19, 2026Long-horizon navigation in unstructured environments demands terrain abstractions that scale to tens of km$^2$ while preserving semantic and geometric structure, a combination existing methods fail to achieve. Grids scale poorly; quadtrees misalign with terrain boundaries; neither encodes landcover semantics essential for traversability-aware planning. This yields infeasible or unreliable paths for autonomous ground vehicles operating over 10+ km$^2$ under real-time constraints. CLEAR (Connected Landcover Elevation Abstract Representation) couples boundary-aware spatial decomposition with recursive plane fitting to produce convex, semantically aligned regions encoded as a terrain-aware graph. Evaluated on maps spanning 9-100~km$^2$ using a physics-based simulator, CLEAR achieves up to 10x faster planning than raw grids with only 6.7% cost overhead and delivers 6-9% shorter, more reliable paths than other abstraction baselines. These results highlight CLEAR's scalability and utility for long-range navigation in applications such as disaster response, defense, and planetary exploration.
Learning-aided Bigraph Matching Approach to Multi-Crew Restoration of Damaged Power Networks Coupled with Road Transportation Networks
Jun 24, 2025The resilience of critical infrastructure networks (CINs) after disruptions, such as those caused by natural hazards, depends on both the speed of restoration and the extent to which operational functionality can be regained. Allocating resources for restoration is a combinatorial optimal planning problem that involves determining which crews will repair specific network nodes and in what order. This paper presents a novel graph-based formulation that merges two interconnected graphs, representing crew and transportation nodes and power grid nodes, into a single heterogeneous graph. To enable efficient planning, graph reinforcement learning (GRL) is integrated with bigraph matching. GRL is utilized to design the incentive function for assigning crews to repair tasks based on the graph-abstracted state of the environment, ensuring generalization across damage scenarios. Two learning techniques are employed: a graph neural network trained using Proximal Policy Optimization and another trained via Neuroevolution. The learned incentive functions inform a bipartite graph that links crews to repair tasks, enabling weighted maximum matching for crew-to-task allocations. An efficient simulation environment that pre-computes optimal node-to-node path plans is used to train the proposed restoration planning methods. An IEEE 8500-bus power distribution test network coupled with a 21 square km transportation network is used as the case study, with scenarios varying in terms of numbers of damaged nodes, depots, and crews. Results demonstrate the approach's generalizability and scalability across scenarios, with learned policies providing 3-fold better performance than random policies, while also outperforming optimization-based solutions in both computation time (by several orders of magnitude) and power restored.
A Talent-infused Policy-gradient Approach to Efficient Co-Design of Morphology and Task Allocation Behavior of Multi-Robot Systems
Nov 27, 2024



Interesting and efficient collective behavior observed in multi-robot or swarm systems emerges from the individual behavior of the robots. The functional space of individual robot behaviors is in turn shaped or constrained by the robot's morphology or physical design. Thus the full potential of multi-robot systems can be realized by concurrently optimizing the morphology and behavior of individual robots, informed by the environment's feedback about their collective performance, as opposed to treating morphology and behavior choices disparately or in sequence (the classical approach). This paper presents an efficient concurrent design or co-design method to explore this potential and understand how morphology choices impact collective behavior, particularly in an MRTA problem focused on a flood response scenario, where the individual behavior is designed via graph reinforcement learning. Computational efficiency in this case is attributed to a new way of near exact decomposition of the co-design problem into a series of simpler optimization and learning problems. This is achieved through i) the identification and use of the Pareto front of Talent metrics that represent morphology-dependent robot capabilities, and ii) learning the selection of Talent best trade-offs and individual robot policy that jointly maximizes the MRTA performance. Applied to a multi-unmanned aerial vehicle flood response use case, the co-design outcomes are shown to readily outperform sequential design baselines. Significant differences in morphology and learned behavior are also observed when comparing co-designed single robot vs. co-designed multi-robot systems for similar operations.
A Graph-based Adversarial Imitation Learning Framework for Reliable & Realtime Fleet Scheduling in Urban Air Mobility
Jul 16, 2024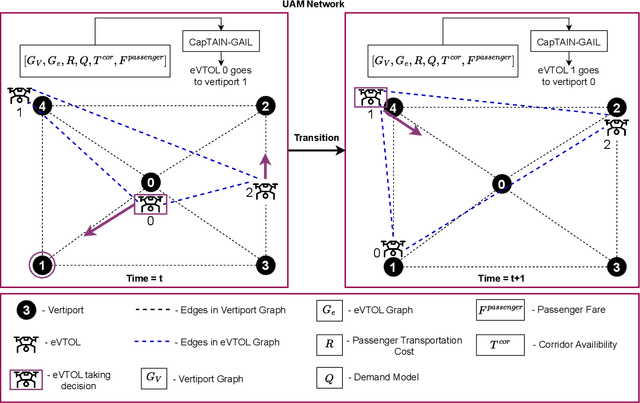
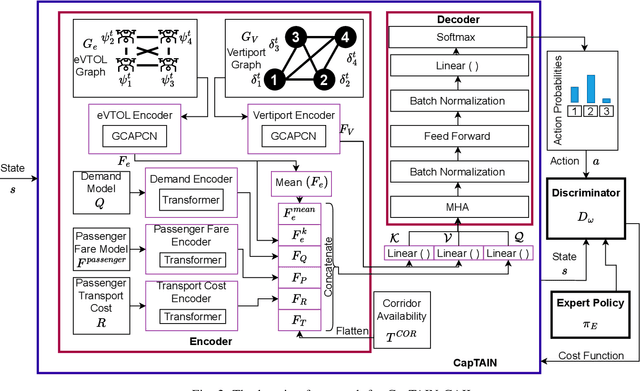
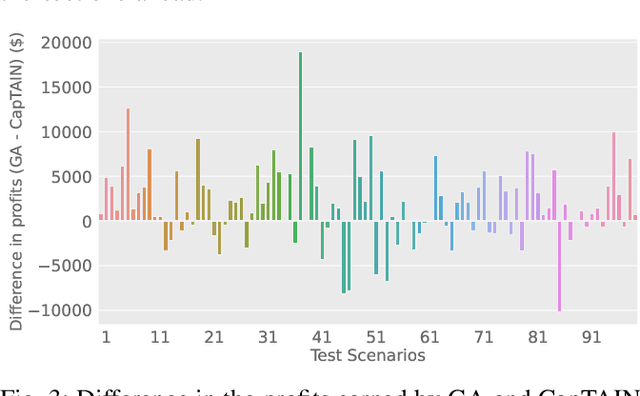
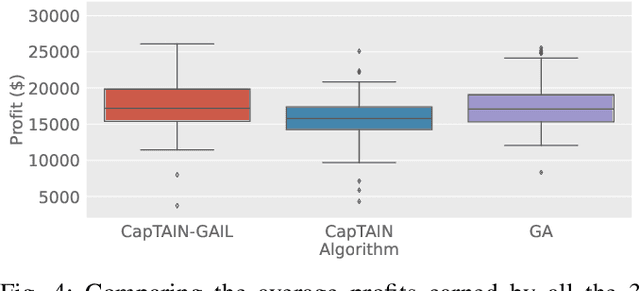
The advent of Urban Air Mobility (UAM) presents the scope for a transformative shift in the domain of urban transportation. However, its widespread adoption and economic viability depends in part on the ability to optimally schedule the fleet of aircraft across vertiports in a UAM network, under uncertainties attributed to airspace congestion, changing weather conditions, and varying demands. This paper presents a comprehensive optimization formulation of the fleet scheduling problem, while also identifying the need for alternate solution approaches, since directly solving the resulting integer nonlinear programming problem is computationally prohibitive for daily fleet scheduling. Previous work has shown the effectiveness of using (graph) reinforcement learning (RL) approaches to train real-time executable policy models for fleet scheduling. However, such policies can often be brittle on out-of-distribution scenarios or edge cases. Moreover, training performance also deteriorates as the complexity (e.g., number of constraints) of the problem increases. To address these issues, this paper presents an imitation learning approach where the RL-based policy exploits expert demonstrations yielded by solving the exact optimization using a Genetic Algorithm. The policy model comprises Graph Neural Network (GNN) based encoders that embed the space of vertiports and aircraft, Transformer networks to encode demand, passenger fare, and transport cost profiles, and a Multi-head attention (MHA) based decoder. Expert demonstrations are used through the Generative Adversarial Imitation Learning (GAIL) algorithm. Interfaced with a UAM simulation environment involving 8 vertiports and 40 aircrafts, in terms of the daily profits earned reward, the new imitative approach achieves better mean performance and remarkable improvement in the case of unseen worst-case scenarios, compared to pure RL results.
Optimizing Design and Control of Running Robots Abstracted as Torque Driven Spring Loaded Inverted Pendulum (TD-SLIP)
Jul 16, 2024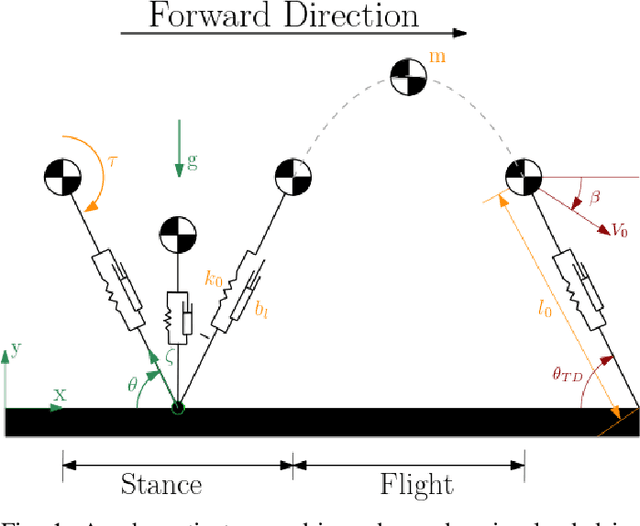
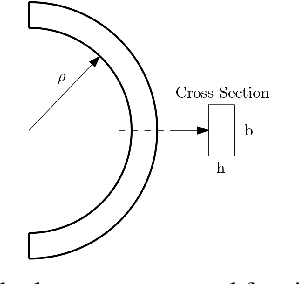
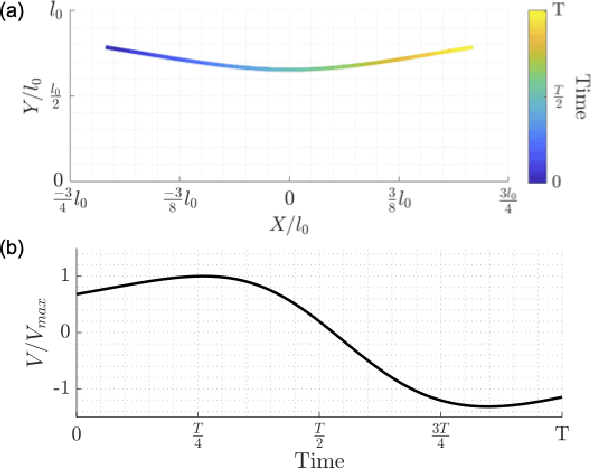
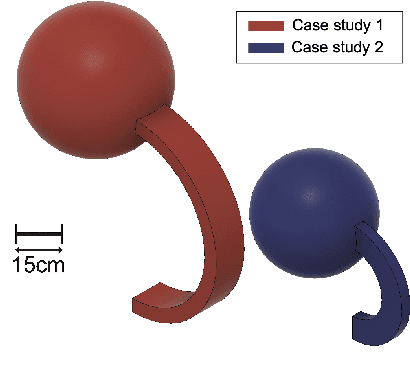
Legged locomotion shows promise for running in complex, unstructured environments. Designing such legged robots requires considering heterogeneous, multi-domain constraints and variables, from mechanical hardware and geometry choices to controller profiles. However, very few formal or systematic (as opposed to ad hoc) design formulations and frameworks exist to identify feasible and robust running platforms, especially at the small (sub 500 g) scale. This critical gap in running legged robot design is addressed here by abstracting the motion of legged robots through a torque-driven spring-loaded inverted pendulum (TD-SLIP) model, and deriving constraints that result in stable cyclic forward locomotion in the presence of system noise. Synthetic noise is added to the initial state in candidate design evaluation to simulate accumulated errors in an open-loop control. The design space was defined in terms of morphological parameters, such as the leg properties and system mass, actuator selection, and an open loop voltage profile. These attributes were optimized with a well-known particle swarm optimization solver that can handle mixed-discrete variables. Two separate case studies minimized the difference in touchdown angle from stride to stride and the actuation energy, respectively. Both cases resulted in legged robot designs with relatively repeatable and stable dynamics, while presenting distinct geometry and controller profile choices.