 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Eye-gaze Augmentation To Enhance Imitation Learning In Atari Games
Dec 05, 2020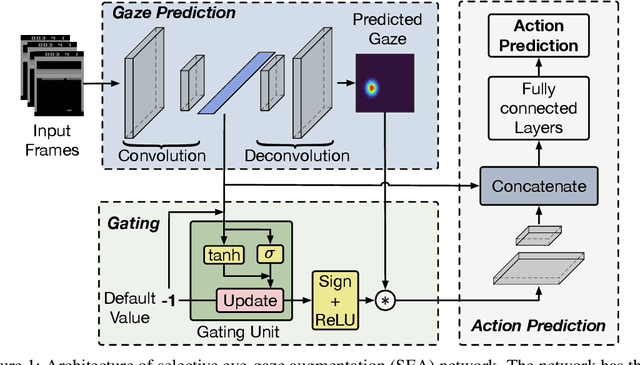


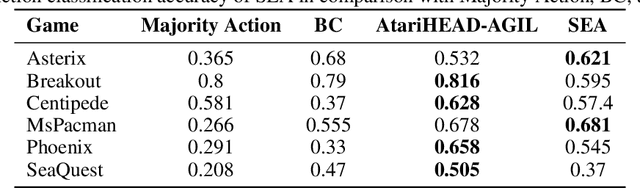
This paper presents the selective use of eye-gaze information in learning human actions in Atari games. Vast evidence suggests that our eye movement convey a wealth of information about the direction of our attention and mental states and encode the information necessary to complete a task. Based on this evidence, we hypothesize that selective use of eye-gaze, as a clue for attention direction, will enhance the learning from demonstration. For this purpose, we propose a selective eye-gaze augmentation (SEA) network that learns when to use the eye-gaze information. The proposed network architecture consists of three sub-networks: gaze prediction, gating, and action prediction network. Using the prior 4 game frames, a gaze map is predicted by the gaze prediction network which is used for augmenting the input frame. The gating network will determine whether the predicted gaze map should be used in learning and is fed to the final network to predict the action at the current frame. To validate this approach, we use publicly available Atari Human Eye-Tracking And Demonstration (Atari-HEAD) dataset consists of 20 Atari games with 28 million human demonstrations and 328 million eye-gazes (over game frames) collected from four subjects. We demonstrate the efficacy of selective eye-gaze augmentation in comparison with state of the art Attention Guided Imitation Learning (AGIL), Behavior Cloning (BC). The results indicate that the selective augmentation approach (the SEA network) performs significantly better than the AGIL and BC. Moreover, to demonstrate the significance of selective use of gaze through the gating network, we compare our approach with the random selection of the gaze. Even in this case, the SEA network performs significantly better validating the advantage of selectively using the gaze in demonstration learning.