 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet's reward step by step: Step-Level reward model as the Navigators for Reasoning
Paper and Code
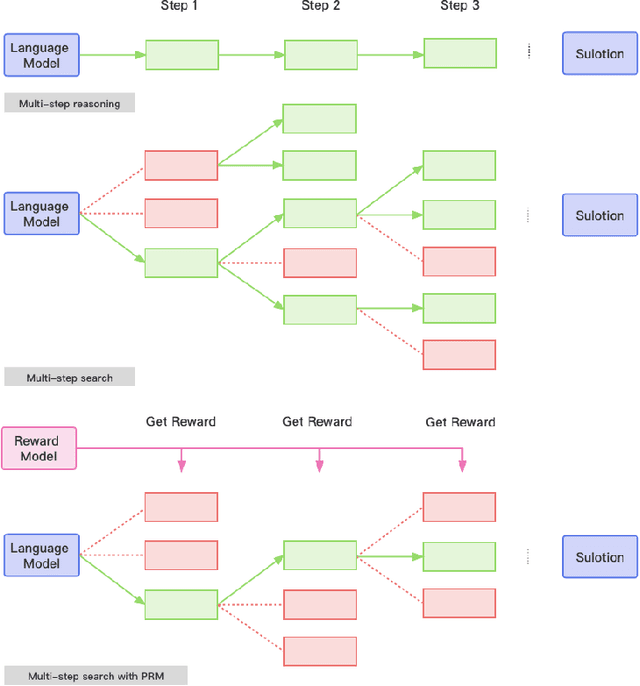

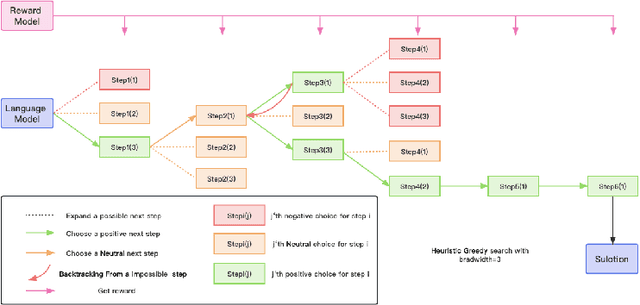

Recent years have seen considerable advancements in multi-step reasoning with Large Language Models (LLMs). The previous studies have elucidated the merits of integrating feedback or search mechanisms during model inference to improve the reasoning accuracy. The Process-Supervised Reward Model (PRM), typically furnishes LLMs with step-by-step feedback during the training phase, akin to Proximal Policy Optimization (PPO) or reject sampling. Our objective is to examine the efficacy of PRM in the inference phase to help discern the optimal solution paths for multi-step tasks such as mathematical reasoning and code generation. To this end, we propose a heuristic greedy search algorithm that employs the step-level feedback from PRM to optimize the reasoning pathways explored by LLMs. This tailored PRM demonstrated enhanced results compared to the Chain of Thought (CoT) on mathematical benchmarks like GSM8K and MATH. Additionally, to explore the versatility of our approach, we develop a novel method to automatically generate step-level reward dataset for coding tasks and observed similar improved performance in the code generation tasks. Thus highlighting the robust nature of our reward-model-based approach to inference for reasoning tasks.