 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Consistency of Video Large Language Models in Temporal Comprehension
Paper and Code
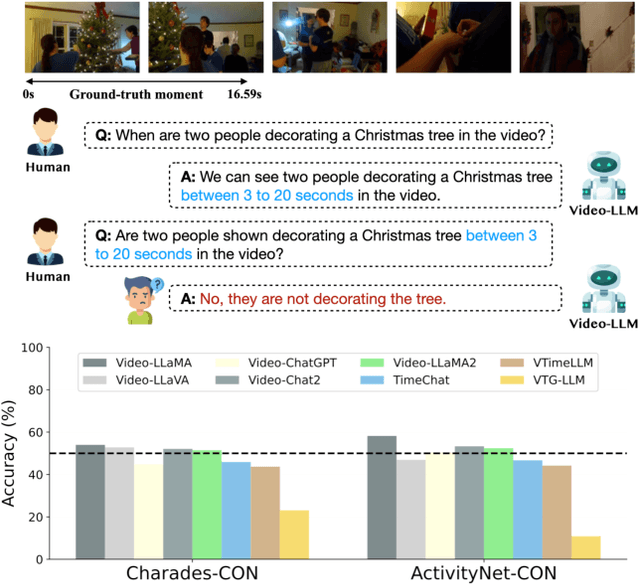
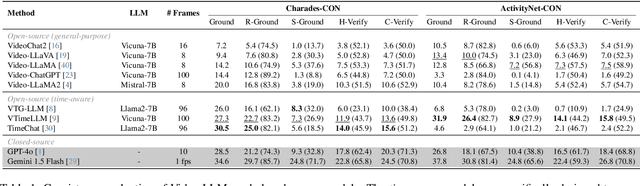

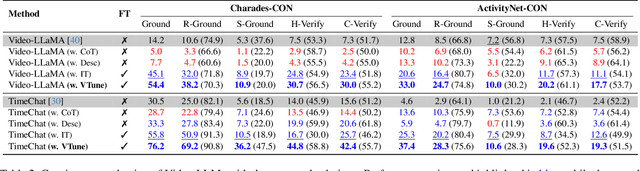
Video large language models (Video-LLMs) can temporally ground language queries and retrieve video moments. Yet, such temporal comprehension capabilities are neither well-studied nor understood. So we conduct a study on prediction consistency -- a key indicator for robustness and trustworthiness of temporal grounding. After the model identifies an initial moment within the video content, we apply a series of probes to check if the model's responses align with this initial grounding as an indicator of reliable comprehension. Our results reveal that current Video-LLMs are sensitive to variations in video contents, language queries, and task settings, unveiling severe deficiencies in maintaining consistency. We further explore common prompting and instruction-tuning methods as potential solutions, but find that their improvements are often unstable. To that end, we propose event temporal verification tuning that explicitly accounts for consistency, and demonstrate significant improvements for both grounding and consistency. Our data and code will be available at https://github.com/minjoong507/Consistency-of-Video-LLM.