 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Ordinal Bias in Action Recognition for Instructional Videos
Paper and Code
Apr 09, 2025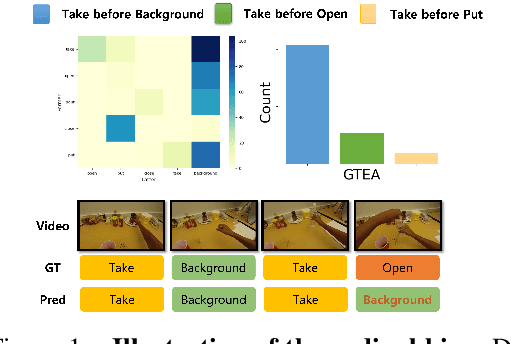

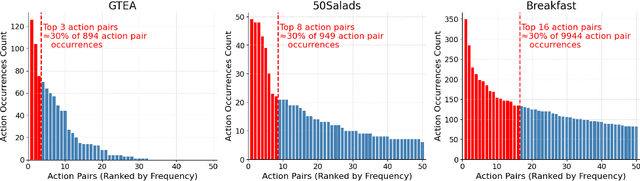

Action recognition models have achieved promising results in understanding instructional videos. However, they often rely on dominant, dataset-specific action sequences rather than true video comprehension, a problem that we define as ordinal bias. To address this issue, we propose two effective video manipulation methods: Action Masking, which masks frames of frequently co-occurring actions, and Sequence Shuffling, which randomizes the order of action segments. Through comprehensive experiments, we demonstrate that current models exhibit significant performance drops when confronted with nonstandard action sequences, underscoring their vulnerability to ordinal bias. Our findings emphasize the importance of rethinking evaluation strategies and developing models capable of generalizing beyond fixed action patterns in diverse instructional videos.