 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDescanning: From Scanned to the Original Images with a Color Correction Diffusion Model
Feb 08, 2024
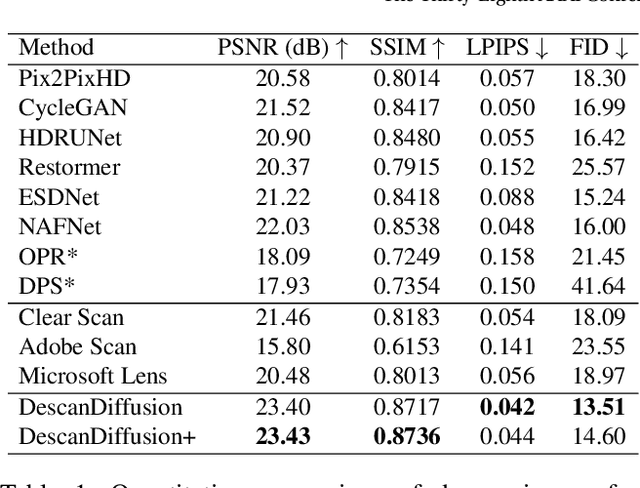

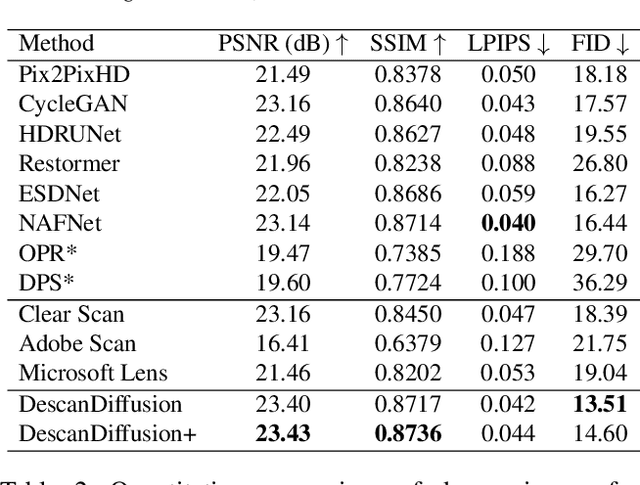
A significant volume of analog information, i.e., documents and images, have been digitized in the form of scanned copies for storing, sharing, and/or analyzing in the digital world. However, the quality of such contents is severely degraded by various distortions caused by printing, storing, and scanning processes in the physical world. Although restoring high-quality content from scanned copies has become an indispensable task for many products, it has not been systematically explored, and to the best of our knowledge, no public datasets are available. In this paper, we define this problem as Descanning and introduce a new high-quality and large-scale dataset named DESCAN-18K. It contains 18K pairs of original and scanned images collected in the wild containing multiple complex degradations. In order to eliminate such complex degradations, we propose a new image restoration model called DescanDiffusion consisting of a color encoder that corrects the global color degradation and a conditional denoising diffusion probabilistic model (DDPM) that removes local degradations. To further improve the generalization ability of DescanDiffusion, we also design a synthetic data generation scheme by reproducing prominent degradations in scanned images. We demonstrate that our DescanDiffusion outperforms other baselines including commercial restoration products, objectively and subjectively, via comprehensive experiments and analyses.
SaliencyMix: A Saliency Guided Data Augmentation Strategy for Better Regularization
Jun 02, 2020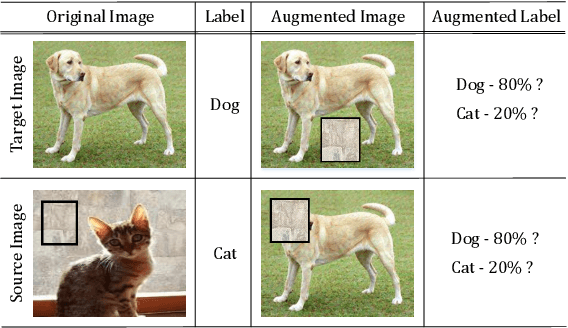
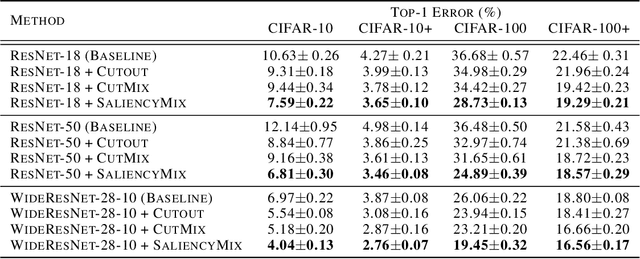


Advanced data augmentation strategies have widely been studied to improve the generalization ability of deep learning models. Regional dropout is one of the popular solutions that guides the model to focus on less discriminative parts by randomly removing image regions, resulting in improved regularization. However, such information removal is undesirable. On the other hand, recent strategies suggest to randomly cut and mix patches and their labels among training images, to enjoy the advantages of regional dropout without having any pointless pixel in the augmented images. We argue that the random selection of the patch may not necessarily represent any information about the corresponding object and thereby mixing the labels according to that uninformative patch enables the model to learn unexpected feature representation. Therefore, we propose SaliencyMix that carefully selects a representative image patch with the help of a saliency map and mixes this indicative patch with the target image that leads the model to learn more appropriate feature representation. SaliencyMix achieves a new state-of-the-art top-1 error of 20.09% on ImageNet classification using ResNet-101 architecture and also improves the model robustness against adversarial perturbations. Furthermore, SaliencyMix trained model helps to improve the object detection performance.