 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Learning-based Video Motion Magnification for Real-time Processing
Mar 04, 2024



Video motion magnification is a technique to capture and amplify subtle motion in a video that is invisible to the naked eye. The deep learning-based prior work successfully demonstrates the modelling of the motion magnification problem with outstanding quality compared to conventional signal processing-based ones. However, it still lags behind real-time performance, which prevents it from being extended to various online applications. In this paper, we investigate an efficient deep learning-based motion magnification model that runs in real time for full-HD resolution videos. Due to the specified network design of the prior art, i.e. inhomogeneous architecture, the direct application of existing neural architecture search methods is complicated. Instead of automatic search, we carefully investigate the architecture module by module for its role and importance in the motion magnification task. Two key findings are 1) Reducing the spatial resolution of the latent motion representation in the decoder provides a good trade-off between computational efficiency and task quality, and 2) surprisingly, only a single linear layer and a single branch in the encoder are sufficient for the motion magnification task. Based on these findings, we introduce a real-time deep learning-based motion magnification model with4.2X fewer FLOPs and is 2.7X faster than the prior art while maintaining comparable quality.
MST-compression: Compressing and Accelerating Binary Neural Networks with Minimum Spanning Tree
Aug 26, 2023
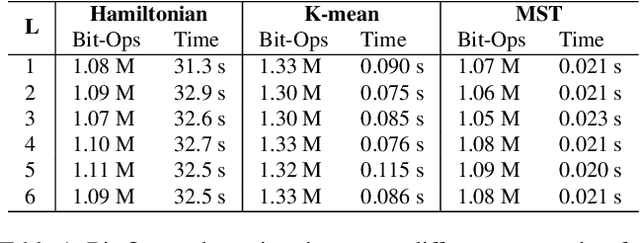


Binary neural networks (BNNs) have been widely adopted to reduce the computational cost and memory storage on edge-computing devices by using one-bit representation for activations and weights. However, as neural networks become wider/deeper to improve accuracy and meet practical requirements, the computational burden remains a significant challenge even on the binary version. To address these issues, this paper proposes a novel method called Minimum Spanning Tree (MST) compression that learns to compress and accelerate BNNs. The proposed architecture leverages an observation from previous works that an output channel in a binary convolution can be computed using another output channel and XNOR operations with weights that differ from the weights of the reused channel. We first construct a fully connected graph with vertices corresponding to output channels, where the distance between two vertices is the number of different values between the weight sets used for these outputs. Then, the MST of the graph with the minimum depth is proposed to reorder output calculations, aiming to reduce computational cost and latency. Moreover, we propose a new learning algorithm to reduce the total MST distance during training. Experimental results on benchmark models demonstrate that our method achieves significant compression ratios with negligible accuracy drops, making it a promising approach for resource-constrained edge-computing devices.