 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSFUOD: Source-Free Unknown Object Detection
Jul 23, 2025Source-free object detection adapts a detector pre-trained on a source domain to an unlabeled target domain without requiring access to labeled source data. While this setting is practical as it eliminates the need for the source dataset during domain adaptation, it operates under the restrictive assumption that only pre-defined objects from the source domain exist in the target domain. This closed-set setting prevents the detector from detecting undefined objects. To ease this assumption, we propose Source-Free Unknown Object Detection (SFUOD), a novel scenario which enables the detector to not only recognize known objects but also detect undefined objects as unknown objects. To this end, we propose CollaPAUL (Collaborative tuning and Principal Axis-based Unknown Labeling), a novel framework for SFUOD. Collaborative tuning enhances knowledge adaptation by integrating target-dependent knowledge from the auxiliary encoder with source-dependent knowledge from the pre-trained detector through a cross-domain attention mechanism. Additionally, principal axes-based unknown labeling assigns pseudo-labels to unknown objects by estimating objectness via principal axes projection and confidence scores from model predictions. The proposed CollaPAUL achieves state-of-the-art performances on SFUOD benchmarks, and extensive experiments validate its effectiveness.
Universal Domain Adaptation for Semantic Segmentation
May 28, 2025Unsupervised domain adaptation for semantic segmentation (UDA-SS) aims to transfer knowledge from labeled source data to unlabeled target data. However, traditional UDA-SS methods assume that category settings between source and target domains are known, which is unrealistic in real-world scenarios. This leads to performance degradation if private classes exist. To address this limitation, we propose Universal Domain Adaptation for Semantic Segmentation (UniDA-SS), achieving robust adaptation even without prior knowledge of category settings. We define the problem in the UniDA-SS scenario as low confidence scores of common classes in the target domain, which leads to confusion with private classes. To solve this problem, we propose UniMAP: UniDA-SS with Image Matching and Prototype-based Distinction, a novel framework composed of two key components. First, Domain-Specific Prototype-based Distinction (DSPD) divides each class into two domain-specific prototypes, enabling finer separation of domain-specific features and enhancing the identification of common classes across domains. Second, Target-based Image Matching (TIM) selects a source image containing the most common-class pixels based on the target pseudo-label and pairs it in a batch to promote effective learning of common classes. We also introduce a new UniDA-SS benchmark and demonstrate through various experiments that UniMAP significantly outperforms baselines. The code is available at \href{https://github.com/KU-VGI/UniMAP}{this https URL}.
Online Continuous Generalized Category Discovery
Aug 24, 2024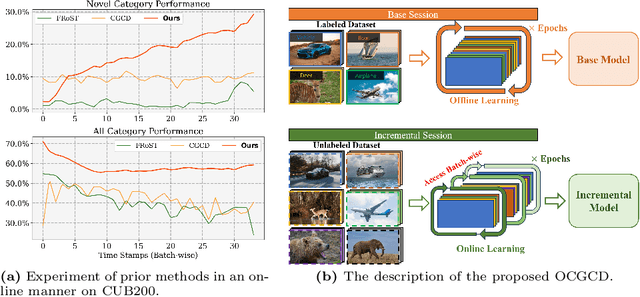
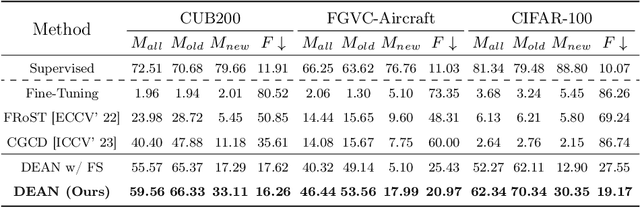
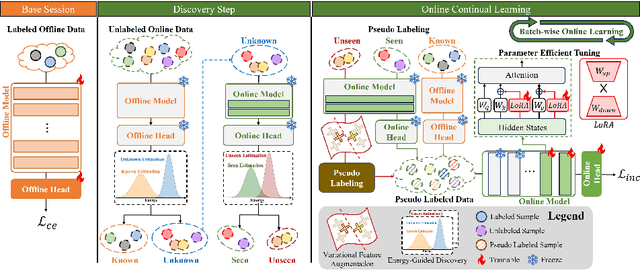

With the advancement of deep neural networks in computer vision, artificial intelligence (AI) is widely employed in real-world applications. However, AI still faces limitations in mimicking high-level human capabilities, such as novel category discovery, for practical use. While some methods utilizing offline continual learning have been proposed for novel category discovery, they neglect the continuity of data streams in real-world settings. In this work, we introduce Online Continuous Generalized Category Discovery (OCGCD), which considers the dynamic nature of data streams where data can be created and deleted in real time. Additionally, we propose a novel method, DEAN, Discovery via Energy guidance and feature AugmentatioN, which can discover novel categories in an online manner through energy-guided discovery and facilitate discriminative learning via energy-based contrastive loss. Furthermore, DEAN effectively pseudo-labels unlabeled data through variance-based feature augmentation. Experimental results demonstrate that our proposed DEAN achieves outstanding performance in proposed OCGCD scenario.
Open-Set Domain Adaptation for Semantic Segmentation
May 30, 2024

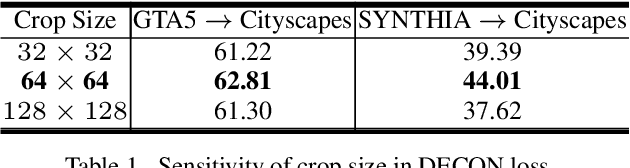
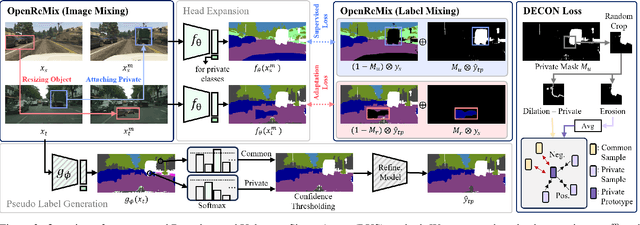
Unsupervised domain adaptation (UDA) for semantic segmentation aims to transfer the pixel-wise knowledge from the labeled source domain to the unlabeled target domain. However, current UDA methods typically assume a shared label space between source and target, limiting their applicability in real-world scenarios where novel categories may emerge in the target domain. In this paper, we introduce Open-Set Domain Adaptation for Semantic Segmentation (OSDA-SS) for the first time, where the target domain includes unknown classes. We identify two major problems in the OSDA-SS scenario as follows: 1) the existing UDA methods struggle to predict the exact boundary of the unknown classes, and 2) they fail to accurately predict the shape of the unknown classes. To address these issues, we propose Boundary and Unknown Shape-Aware open-set domain adaptation, coined BUS. Our BUS can accurately discern the boundaries between known and unknown classes in a contrastive manner using a novel dilation-erosion-based contrastive loss. In addition, we propose OpenReMix, a new domain mixing augmentation method that guides our model to effectively learn domain and size-invariant features for improving the shape detection of the known and unknown classes. Through extensive experiments, we demonstrate that our proposed BUS effectively detects unknown classes in the challenging OSDA-SS scenario compared to the previous methods by a large margin. The code is available at https://github.com/KHU-AGI/BUS.
Pre-trained Vision and Language Transformers Are Few-Shot Incremental Learners
Apr 02, 2024



Few-Shot Class Incremental Learning (FSCIL) is a task that requires a model to learn new classes incrementally without forgetting when only a few samples for each class are given. FSCIL encounters two significant challenges: catastrophic forgetting and overfitting, and these challenges have driven prior studies to primarily rely on shallow models, such as ResNet-18. Even though their limited capacity can mitigate both forgetting and overfitting issues, it leads to inadequate knowledge transfer during few-shot incremental sessions. In this paper, we argue that large models such as vision and language transformers pre-trained on large datasets can be excellent few-shot incremental learners. To this end, we propose a novel FSCIL framework called PriViLege, Pre-trained Vision and Language transformers with prompting functions and knowledge distillation. Our framework effectively addresses the challenges of catastrophic forgetting and overfitting in large models through new pre-trained knowledge tuning (PKT) and two losses: entropy-based divergence loss and semantic knowledge distillation loss. Experimental results show that the proposed PriViLege significantly outperforms the existing state-of-the-art methods with a large margin, e.g., +9.38% in CUB200, +20.58% in CIFAR-100, and +13.36% in miniImageNet. Our implementation code is available at https://github.com/KHU-AGI/PriViLege.
Online Class Incremental Learning on Stochastic Blurry Task Boundary via Mask and Visual Prompt Tuning
Aug 18, 2023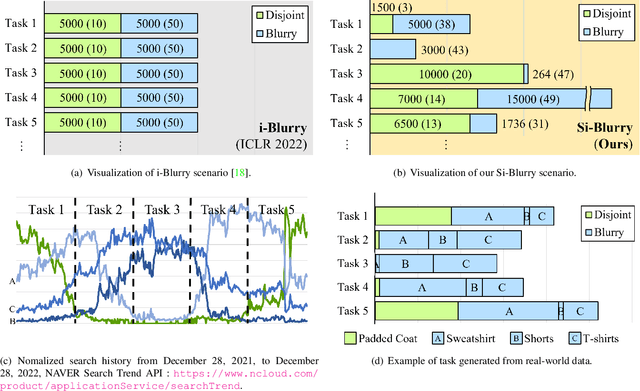
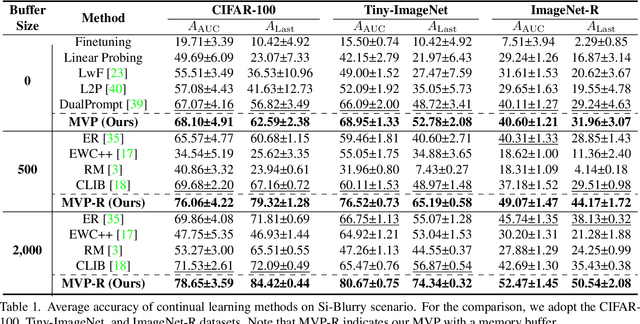
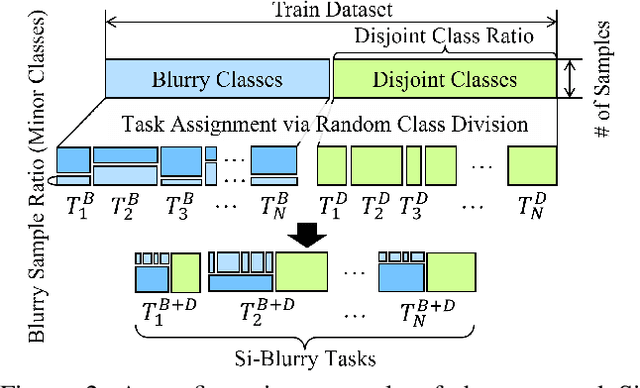
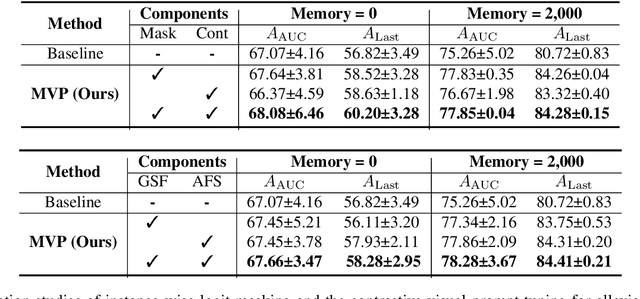
Continual learning aims to learn a model from a continuous stream of data, but it mainly assumes a fixed number of data and tasks with clear task boundaries. However, in real-world scenarios, the number of input data and tasks is constantly changing in a statistical way, not a static way. Although recently introduced incremental learning scenarios having blurry task boundaries somewhat address the above issues, they still do not fully reflect the statistical properties of real-world situations because of the fixed ratio of disjoint and blurry samples. In this paper, we propose a new Stochastic incremental Blurry task boundary scenario, called Si-Blurry, which reflects the stochastic properties of the real-world. We find that there are two major challenges in the Si-Blurry scenario: (1) inter- and intra-task forgettings and (2) class imbalance problem. To alleviate them, we introduce Mask and Visual Prompt tuning (MVP). In MVP, to address the inter- and intra-task forgetting issues, we propose a novel instance-wise logit masking and contrastive visual prompt tuning loss. Both of them help our model discern the classes to be learned in the current batch. It results in consolidating the previous knowledge. In addition, to alleviate the class imbalance problem, we introduce a new gradient similarity-based focal loss and adaptive feature scaling to ease overfitting to the major classes and underfitting to the minor classes. Extensive experiments show that our proposed MVP significantly outperforms the existing state-of-the-art methods in our challenging Si-Blurry scenario.