 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen-Image-Layered: Towards Inherent Editability via Layer Decomposition
Dec 17, 2025Recent visual generative models often struggle with consistency during image editing due to the entangled nature of raster images, where all visual content is fused into a single canvas. In contrast, professional design tools employ layered representations, allowing isolated edits while preserving consistency. Motivated by this, we propose \textbf{Qwen-Image-Layered}, an end-to-end diffusion model that decomposes a single RGB image into multiple semantically disentangled RGBA layers, enabling \textbf{inherent editability}, where each RGBA layer can be independently manipulated without affecting other content. To support variable-length decomposition, we introduce three key components: (1) an RGBA-VAE to unify the latent representations of RGB and RGBA images; (2) a VLD-MMDiT (Variable Layers Decomposition MMDiT) architecture capable of decomposing a variable number of image layers; and (3) a Multi-stage Training strategy to adapt a pretrained image generation model into a multilayer image decomposer. Furthermore, to address the scarcity of high-quality multilayer training images, we build a pipeline to extract and annotate multilayer images from Photoshop documents (PSD). Experiments demonstrate that our method significantly surpasses existing approaches in decomposition quality and establishes a new paradigm for consistent image editing. Our code and models are released on \href{https://github.com/QwenLM/Qwen-Image-Layered}{https://github.com/QwenLM/Qwen-Image-Layered}
Step-Video-TI2V Technical Report: A State-of-the-Art Text-Driven Image-to-Video Generation Model
Mar 14, 2025We present Step-Video-TI2V, a state-of-the-art text-driven image-to-video generation model with 30B parameters, capable of generating videos up to 102 frames based on both text and image inputs. We build Step-Video-TI2V-Eval as a new benchmark for the text-driven image-to-video task and compare Step-Video-TI2V with open-source and commercial TI2V engines using this dataset. Experimental results demonstrate the state-of-the-art performance of Step-Video-TI2V in the image-to-video generation task. Both Step-Video-TI2V and Step-Video-TI2V-Eval are available at https://github.com/stepfun-ai/Step-Video-TI2V.
EG4D: Explicit Generation of 4D Object without Score Distillation
May 28, 2024In recent years, the increasing demand for dynamic 3D assets in design and gaming applications has given rise to powerful generative pipelines capable of synthesizing high-quality 4D objects. Previous methods generally rely on score distillation sampling (SDS) algorithm to infer the unseen views and motion of 4D objects, thus leading to unsatisfactory results with defects like over-saturation and Janus problem. Therefore, inspired by recent progress of video diffusion models, we propose to optimize a 4D representation by explicitly generating multi-view videos from one input image. However, it is far from trivial to handle practical challenges faced by such a pipeline, including dramatic temporal inconsistency, inter-frame geometry and texture diversity, and semantic defects brought by video generation results. To address these issues, we propose DG4D, a novel multi-stage framework that generates high-quality and consistent 4D assets without score distillation. Specifically, collaborative techniques and solutions are developed, including an attention injection strategy to synthesize temporal-consistent multi-view videos, a robust and efficient dynamic reconstruction method based on Gaussian Splatting, and a refinement stage with diffusion prior for semantic restoration. The qualitative results and user preference study demonstrate that our framework outperforms the baselines in generation quality by a considerable margin. Code will be released at \url{https://github.com/jasongzy/EG4D}.
Using Left and Right Brains Together: Towards Vision and Language Planning
Feb 16, 2024



Large Language Models (LLMs) and Large Multi-modality Models (LMMs) have demonstrated remarkable decision masking capabilities on a variety of tasks. However, they inherently operate planning within the language space, lacking the vision and spatial imagination ability. In contrast, humans utilize both left and right hemispheres of the brain for language and visual planning during the thinking process. Therefore, we introduce a novel vision-language planning framework in this work to perform concurrent visual and language planning for tasks with inputs of any form. Our framework incorporates visual planning to capture intricate environmental details, while language planning enhances the logical coherence of the overall system. We evaluate the effectiveness of our framework across vision-language tasks, vision-only tasks, and language-only tasks. The results demonstrate the superior performance of our approach, indicating that the integration of visual and language planning yields better contextually aware task execution.
StrokeNUWA: Tokenizing Strokes for Vector Graphic Synthesis
Jan 30, 2024To leverage LLMs for visual synthesis, traditional methods convert raster image information into discrete grid tokens through specialized visual modules, while disrupting the model's ability to capture the true semantic representation of visual scenes. This paper posits that an alternative representation of images, vector graphics, can effectively surmount this limitation by enabling a more natural and semantically coherent segmentation of the image information. Thus, we introduce StrokeNUWA, a pioneering work exploring a better visual representation ''stroke tokens'' on vector graphics, which is inherently visual semantics rich, naturally compatible with LLMs, and highly compressed. Equipped with stroke tokens, StrokeNUWA can significantly surpass traditional LLM-based and optimization-based methods across various metrics in the vector graphic generation task. Besides, StrokeNUWA achieves up to a 94x speedup in inference over the speed of prior methods with an exceptional SVG code compression ratio of 6.9%.
ORES: Open-vocabulary Responsible Visual Synthesis
Aug 26, 2023



Avoiding synthesizing specific visual concepts is an essential challenge in responsible visual synthesis. However, the visual concept that needs to be avoided for responsible visual synthesis tends to be diverse, depending on the region, context, and usage scenarios. In this work, we formalize a new task, Open-vocabulary Responsible Visual Synthesis (ORES), where the synthesis model is able to avoid forbidden visual concepts while allowing users to input any desired content. To address this problem, we present a Two-stage Intervention (TIN) framework. By introducing 1) rewriting with learnable instruction through a large-scale language model (LLM) and 2) synthesizing with prompt intervention on a diffusion synthesis model, it can effectively synthesize images avoiding any concepts but following the user's query as much as possible. To evaluate on ORES, we provide a publicly available dataset, baseline models, and benchmark. Experimental results demonstrate the effectiveness of our method in reducing risks of image generation. Our work highlights the potential of LLMs in responsible visual synthesis. Our code and dataset is public available.
DragNUWA: Fine-grained Control in Video Generation by Integrating Text, Image, and Trajectory
Aug 16, 2023



Controllable video generation has gained significant attention in recent years. However, two main limitations persist: Firstly, most existing works focus on either text, image, or trajectory-based control, leading to an inability to achieve fine-grained control in videos. Secondly, trajectory control research is still in its early stages, with most experiments being conducted on simple datasets like Human3.6M. This constraint limits the models' capability to process open-domain images and effectively handle complex curved trajectories. In this paper, we propose DragNUWA, an open-domain diffusion-based video generation model. To tackle the issue of insufficient control granularity in existing works, we simultaneously introduce text, image, and trajectory information to provide fine-grained control over video content from semantic, spatial, and temporal perspectives. To resolve the problem of limited open-domain trajectory control in current research, We propose trajectory modeling with three aspects: a Trajectory Sampler (TS) to enable open-domain control of arbitrary trajectories, a Multiscale Fusion (MF) to control trajectories in different granularities, and an Adaptive Training (AT) strategy to generate consistent videos following trajectories. Our experiments validate the effectiveness of DragNUWA, demonstrating its superior performance in fine-grained control in video generation. The homepage link is \url{https://www.microsoft.com/en-us/research/project/dragnuwa/}
NUWA-XL: Diffusion over Diffusion for eXtremely Long Video Generation
Mar 22, 2023



In this paper, we propose NUWA-XL, a novel Diffusion over Diffusion architecture for eXtremely Long video generation. Most current work generates long videos segment by segment sequentially, which normally leads to the gap between training on short videos and inferring long videos, and the sequential generation is inefficient. Instead, our approach adopts a ``coarse-to-fine'' process, in which the video can be generated in parallel at the same granularity. A global diffusion model is applied to generate the keyframes across the entire time range, and then local diffusion models recursively fill in the content between nearby frames. This simple yet effective strategy allows us to directly train on long videos (3376 frames) to reduce the training-inference gap, and makes it possible to generate all segments in parallel. To evaluate our model, we build FlintstonesHD dataset, a new benchmark for long video generation. Experiments show that our model not only generates high-quality long videos with both global and local coherence, but also decreases the average inference time from 7.55min to 26s (by 94.26\%) at the same hardware setting when generating 1024 frames. The homepage link is \url{https://msra-nuwa.azurewebsites.net/}
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
Mar 08, 2023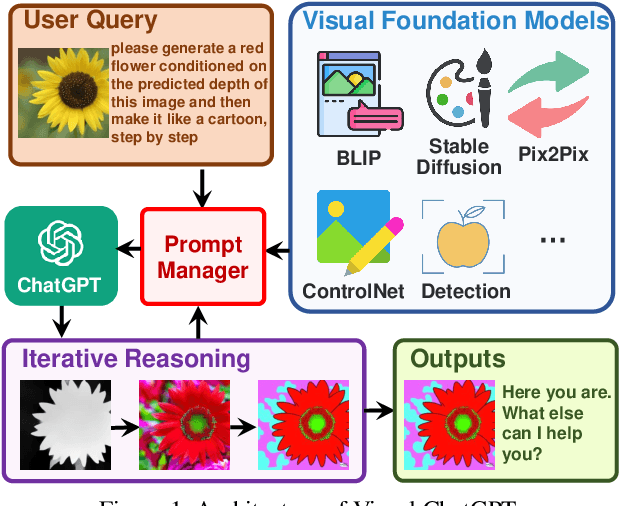
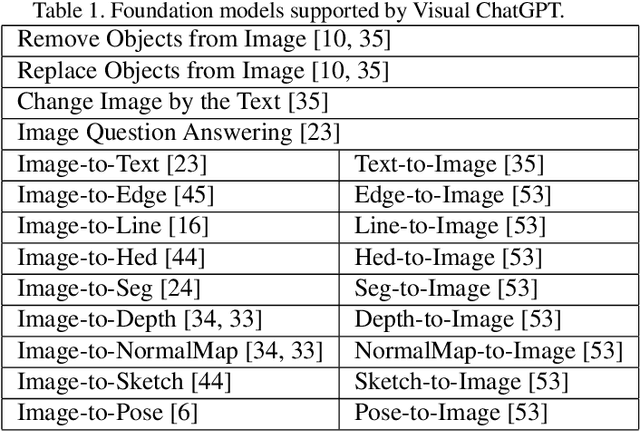
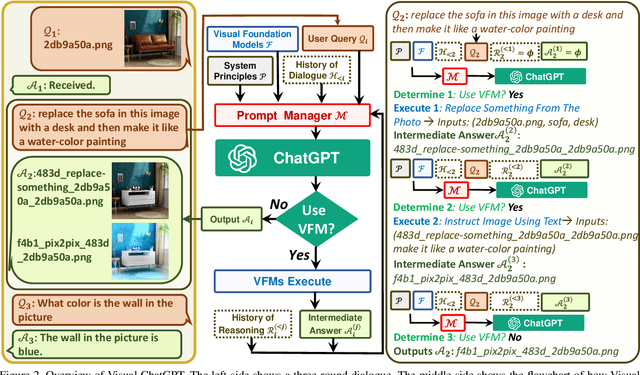
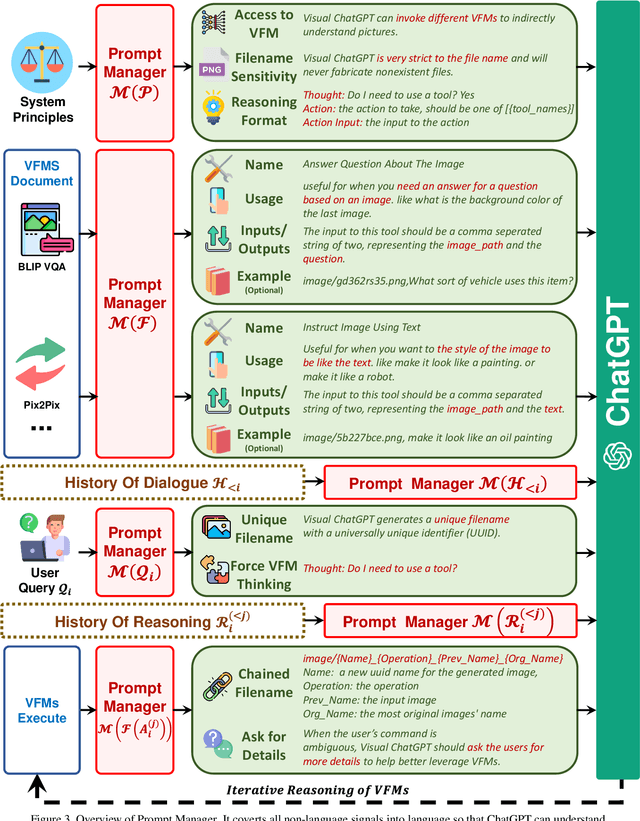
ChatGPT is attracting a cross-field interest as it provides a language interface with remarkable conversational competency and reasoning capabilities across many domains. However, since ChatGPT is trained with languages, it is currently not capable of processing or generating images from the visual world. At the same time, Visual Foundation Models, such as Visual Transformers or Stable Diffusion, although showing great visual understanding and generation capabilities, they are only experts on specific tasks with one-round fixed inputs and outputs. To this end, We build a system called \textbf{Visual ChatGPT}, incorporating different Visual Foundation Models, to enable the user to interact with ChatGPT by 1) sending and receiving not only languages but also images 2) providing complex visual questions or visual editing instructions that require the collaboration of multiple AI models with multi-steps. 3) providing feedback and asking for corrected results. We design a series of prompts to inject the visual model information into ChatGPT, considering models of multiple inputs/outputs and models that require visual feedback. Experiments show that Visual ChatGPT opens the door to investigating the visual roles of ChatGPT with the help of Visual Foundation Models. Our system is publicly available at \url{https://github.com/microsoft/visual-chatgpt}.
Learning 3D Photography Videos via Self-supervised Diffusion on Single Images
Feb 21, 2023
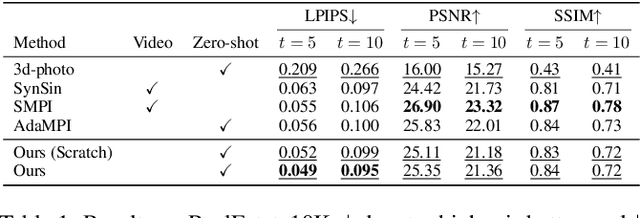


3D photography renders a static image into a video with appealing 3D visual effects. Existing approaches typically first conduct monocular depth estimation, then render the input frame to subsequent frames with various viewpoints, and finally use an inpainting model to fill those missing/occluded regions. The inpainting model plays a crucial role in rendering quality, but it is normally trained on out-of-domain data. To reduce the training and inference gap, we propose a novel self-supervised diffusion model as the inpainting module. Given a single input image, we automatically construct a training pair of the masked occluded image and the ground-truth image with random cycle-rendering. The constructed training samples are closely aligned to the testing instances, without the need of data annotation. To make full use of the masked images, we design a Masked Enhanced Block (MEB), which can be easily plugged into the UNet and enhance the semantic conditions. Towards real-world animation, we present a novel task: out-animation, which extends the space and time of input objects. Extensive experiments on real datasets show that our method achieves competitive results with existing SOTA methods.