 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFP8-LM: Training FP8 Large Language Models
Oct 27, 2023



In this paper, we explore FP8 low-bit data formats for efficient training of large language models (LLMs). Our key insight is that most variables, such as gradients and optimizer states, in LLM training can employ low-precision data formats without compromising model accuracy and requiring no changes to hyper-parameters. Specifically, we propose a new FP8 automatic mixed-precision framework for training LLMs. This framework offers three levels of FP8 utilization to streamline mixed-precision and distributed parallel training for LLMs. It gradually incorporates 8-bit gradients, optimizer states, and distributed learning in an incremental manner. Experiment results show that, during the training of GPT-175B model on H100 GPU platform, our FP8 mixed-precision training framework not only achieved a remarkable 42% reduction in real memory usage but also ran 64% faster than the widely adopted BF16 framework (i.e., Megatron-LM), surpassing the speed of Nvidia Transformer Engine by 17%. This largely reduces the training costs for large foundation models. Furthermore, our FP8 mixed-precision training methodology is generic. It can be seamlessly applied to other tasks such as LLM instruction tuning and reinforcement learning with human feedback, offering savings in fine-tuning expenses. Our FP8 low-precision training framework is open-sourced at {https://github.com/Azure/MS-AMP}{aka.ms/MS.AMP}.
NUWA-XL: Diffusion over Diffusion for eXtremely Long Video Generation
Mar 22, 2023



In this paper, we propose NUWA-XL, a novel Diffusion over Diffusion architecture for eXtremely Long video generation. Most current work generates long videos segment by segment sequentially, which normally leads to the gap between training on short videos and inferring long videos, and the sequential generation is inefficient. Instead, our approach adopts a ``coarse-to-fine'' process, in which the video can be generated in parallel at the same granularity. A global diffusion model is applied to generate the keyframes across the entire time range, and then local diffusion models recursively fill in the content between nearby frames. This simple yet effective strategy allows us to directly train on long videos (3376 frames) to reduce the training-inference gap, and makes it possible to generate all segments in parallel. To evaluate our model, we build FlintstonesHD dataset, a new benchmark for long video generation. Experiments show that our model not only generates high-quality long videos with both global and local coherence, but also decreases the average inference time from 7.55min to 26s (by 94.26\%) at the same hardware setting when generating 1024 frames. The homepage link is \url{https://msra-nuwa.azurewebsites.net/}
XGLUE: A New Benchmark Dataset for Cross-lingual Pre-training, Understanding and Generation
Apr 19, 2020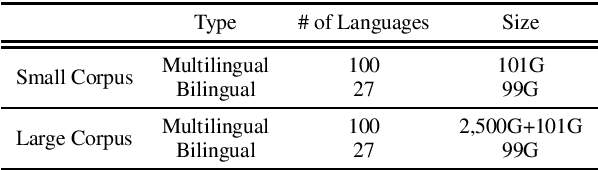
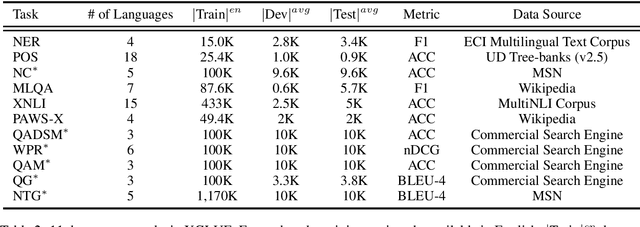
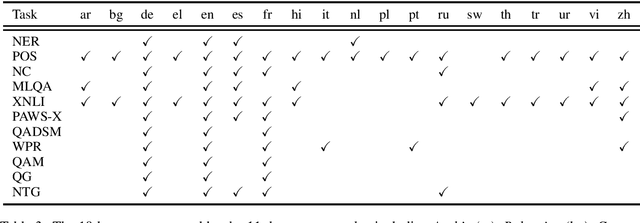
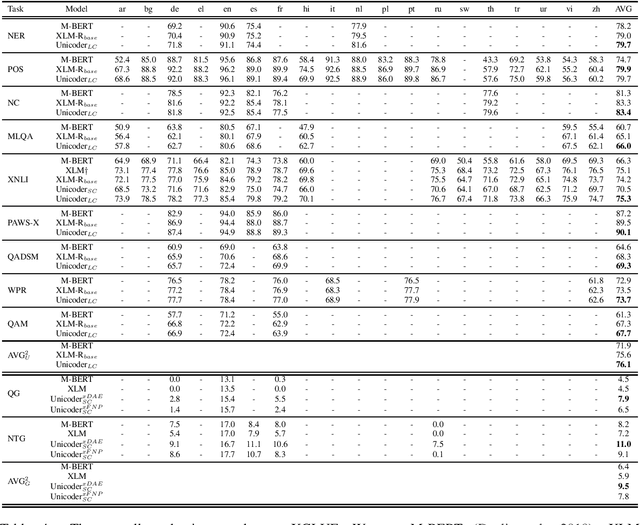
In this paper, we introduce XGLUE, a new benchmark dataset to train large-scale cross-lingual pre-trained models using multilingual and bilingual corpora, and evaluate their performance across a diverse set of cross-lingual tasks. Comparing to GLUE (Wang et al.,2019), which is labeled in English and includes natural language understanding tasks only, XGLUE has three main advantages: (1) it provides two corpora with different sizes for cross-lingual pre-training; (2) it provides 11 diversified tasks that cover both natural language understanding and generation scenarios; (3) for each task, it provides labeled data in multiple languages. We extend a recent cross-lingual pre-trained model Unicoder (Huang et al., 2019) to cover both understanding and generation tasks, which is evaluated on XGLUE as a strong baseline. We also evaluate the base versions (12-layer) of Multilingual BERT, XLM and XLM-R for comparison.
PCM and APCM Revisited: An Uncertainty Perspective
Oct 27, 2016
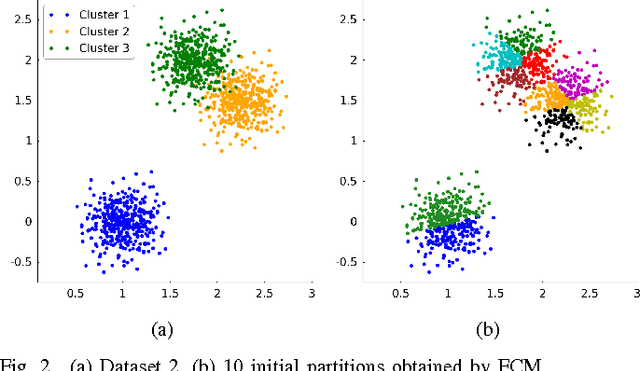
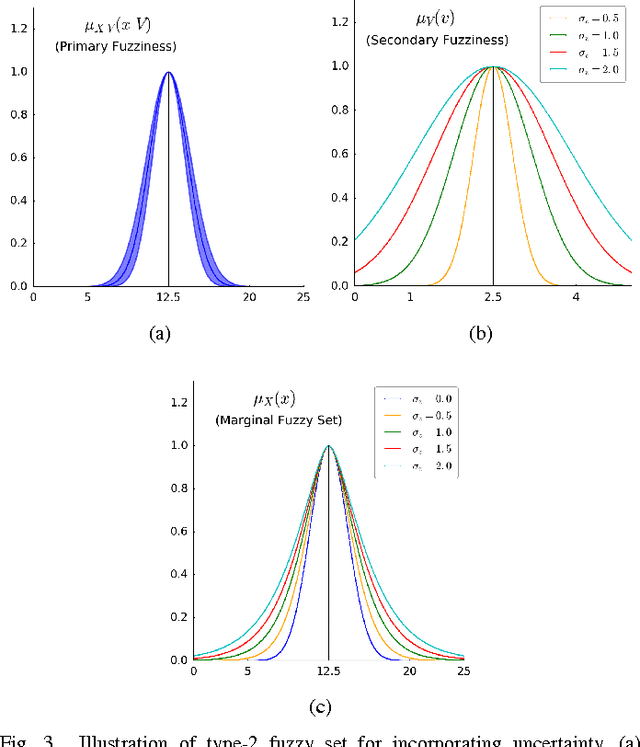
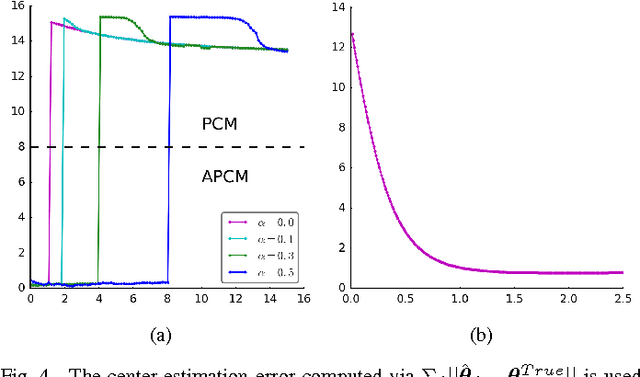
In this paper, we take a new look at the possibilistic c-means (PCM) and adaptive PCM (APCM) clustering algorithms from the perspective of uncertainty. This new perspective offers us insights into the clustering process, and also provides us greater degree of flexibility. We analyze the clustering behavior of PCM-based algorithms and introduce parameters $\sigma_v$ and $\alpha$ to characterize uncertainty of estimated bandwidth and noise level of the dataset respectively. Then uncertainty (fuzziness) of membership values caused by uncertainty of the estimated bandwidth parameter is modeled by a conditional fuzzy set, which is a new formulation of the type-2 fuzzy set. Experiments show that parameters $\sigma_v$ and $\alpha$ make the clustering process more easy to control, and main features of PCM and APCM are unified in this new clustering framework (UPCM). More specifically, UPCM reduces to PCM when we set a small $\alpha$ or a large $\sigma_v$, and UPCM reduces to APCM when clusters are confined in their physical clusters and possible cluster elimination are ensured. Finally we present further researches of this paper.