 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Geometry-Appearance Human Reconstruction in a Unified Latent Space via Bridge Diffusion
Jan 01, 2026Achieving consistent and high-fidelity geometry and appearance reconstruction of 3D digital humans from a single RGB image is inherently a challenging task. Existing studies typically resort to decoupled pipelines for geometry estimation and appearance synthesis, often hindering unified reconstruction and causing inconsistencies. This paper introduces \textbf{JGA-LBD}, a novel framework that unifies the modeling of geometry and appearance into a joint latent representation and formulates the generation process as bridge diffusion. Observing that directly integrating heterogeneous input conditions (e.g., depth maps, SMPL models) leads to substantial training difficulties, we unify all conditions into the 3D Gaussian representations, which can be further compressed into a unified latent space through a shared sparse variational autoencoder (VAE). Subsequently, the specialized form of bridge diffusion enables to start with a partial observation of the target latent code and solely focuses on inferring the missing components. Finally, a dedicated decoding module extracts the complete 3D human geometric structure and renders novel views from the inferred latent representation. Experiments demonstrate that JGA-LBD outperforms current state-of-the-art approaches in terms of both geometry fidelity and appearance quality, including challenging in-the-wild scenarios. Our code will be made publicly available at https://github.com/haiantyz/JGA-LBD.
FlexPara: Flexible Neural Surface Parameterization
Apr 27, 2025Surface parameterization is a fundamental geometry processing task, laying the foundations for the visual presentation of 3D assets and numerous downstream shape analysis scenarios. Conventional parameterization approaches demand high-quality mesh triangulation and are restricted to certain simple topologies unless additional surface cutting and decomposition are provided. In practice, the optimal configurations (e.g., type of parameterization domains, distribution of cutting seams, number of mapping charts) may vary drastically with different surface structures and task characteristics, thus requiring more flexible and controllable processing pipelines. To this end, this paper introduces FlexPara, an unsupervised neural optimization framework to achieve both global and multi-chart surface parameterizations by establishing point-wise mappings between 3D surface points and adaptively-deformed 2D UV coordinates. We ingeniously design and combine a series of geometrically-interpretable sub-networks, with specific functionalities of cutting, deforming, unwrapping, and wrapping, to construct a bi-directional cycle mapping framework for global parameterization without the need for manually specified cutting seams. Furthermore, we construct a multi-chart parameterization framework with adaptively-learned chart assignment. Extensive experiments demonstrate the universality, superiority, and inspiring potential of our neural surface parameterization paradigm. The code will be publicly available at https://github.com/AidenZhao/FlexPara
SuperCarver: Texture-Consistent 3D Geometry Super-Resolution for High-Fidelity Surface Detail Generation
Mar 12, 2025

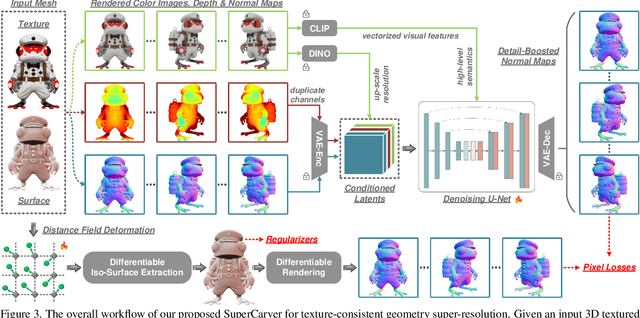

Traditional production workflow of high-precision 3D mesh assets necessitates a cumbersome and laborious process of manual sculpting by specialized modelers. The recent years have witnessed remarkable advances in AI-empowered 3D content creation. However, although the latest state-of-the-arts are already capable of generating plausible structures and intricate appearances from images or text prompts, the actual mesh surfaces are typically over-smoothing and lack geometric details. This paper introduces SuperCarver, a 3D geometry super-resolution framework particularly tailored for adding texture-consistent surface details to given coarse meshes. Technically, we start by rendering the original textured mesh into the image domain from multiple viewpoints. To achieve geometric detail generation, we develop a deterministic prior-guided normal diffusion model fine-tuned on a carefully curated dataset of paired low-poly and high-poly normal renderings. To optimize mesh structures from potentially imperfect normal map predictions, we design a simple yet effective noise-resistant inverse rendering scheme based on distance field deformation. Extensive experiments show that SuperCarver generates realistic and expressive surface details as depicted by specific texture appearances, making it a powerful tool for automatically upgrading massive outdated low-quality assets and shortening the iteration cycle of high-quality mesh production in practical applications.
HuGDiffusion: Generalizable Single-Image Human Rendering via 3D Gaussian Diffusion
Jan 25, 2025

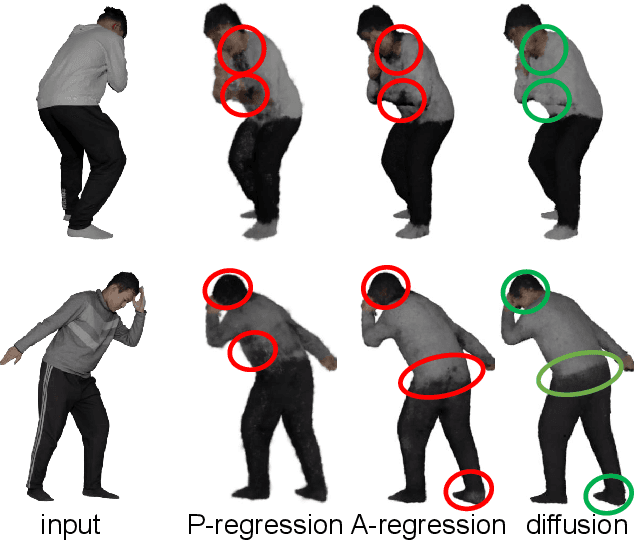

We present HuGDiffusion, a generalizable 3D Gaussian splatting (3DGS) learning pipeline to achieve novel view synthesis (NVS) of human characters from single-view input images. Existing approaches typically require monocular videos or calibrated multi-view images as inputs, whose applicability could be weakened in real-world scenarios with arbitrary and/or unknown camera poses. In this paper, we aim to generate the set of 3DGS attributes via a diffusion-based framework conditioned on human priors extracted from a single image. Specifically, we begin with carefully integrated human-centric feature extraction procedures to deduce informative conditioning signals. Based on our empirical observations that jointly learning the whole 3DGS attributes is challenging to optimize, we design a multi-stage generation strategy to obtain different types of 3DGS attributes. To facilitate the training process, we investigate constructing proxy ground-truth 3D Gaussian attributes as high-quality attribute-level supervision signals. Through extensive experiments, our HuGDiffusion shows significant performance improvements over the state-of-the-art methods. Our code will be made publicly available.
Flatten Anything: Unsupervised Neural Surface Parameterization
May 23, 2024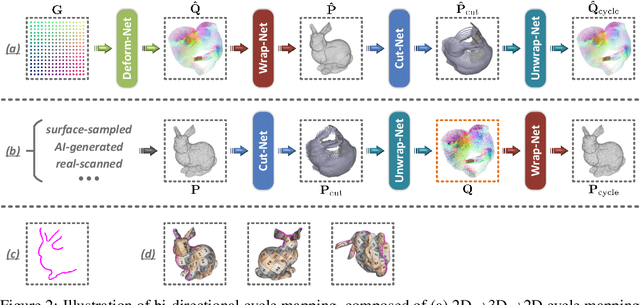
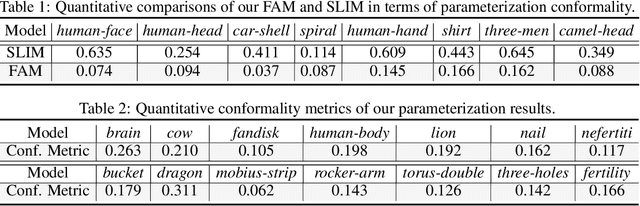
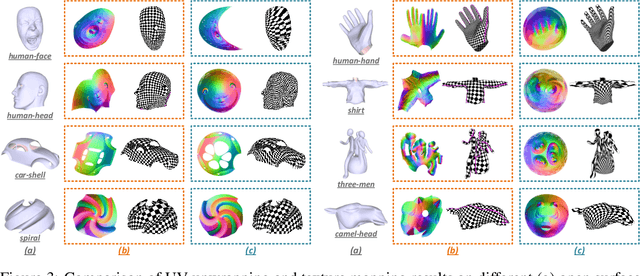

Surface parameterization plays an essential role in numerous computer graphics and geometry processing applications. Traditional parameterization approaches are designed for high-quality meshes laboriously created by specialized 3D modelers, thus unable to meet the processing demand for the current explosion of ordinary 3D data. Moreover, their working mechanisms are typically restricted to certain simple topologies, thus relying on cumbersome manual efforts (e.g., surface cutting, part segmentation) for pre-processing. In this paper, we introduce the Flatten Anything Model (FAM), an unsupervised neural architecture to achieve global free-boundary surface parameterization via learning point-wise mappings between 3D points on the target geometric surface and adaptively-deformed UV coordinates within the 2D parameter domain. To mimic the actual physical procedures, we ingeniously construct geometrically-interpretable sub-networks with specific functionalities of surface cutting, UV deforming, unwrapping, and wrapping, which are assembled into a bi-directional cycle mapping framework. Compared with previous methods, our FAM directly operates on discrete surface points without utilizing connectivity information, thus significantly reducing the strict requirements for mesh quality and even applicable to unstructured point cloud data. More importantly, our FAM is fully-automated without the need for pre-cutting and can deal with highly-complex topologies, since its learning process adaptively finds reasonable cutting seams and UV boundaries. Extensive experiments demonstrate the universality, superiority, and inspiring potential of our proposed neural surface parameterization paradigm. The code will be publicly available.
ParaPoint: Learning Global Free-Boundary Surface Parameterization of 3D Point Clouds
Mar 15, 2024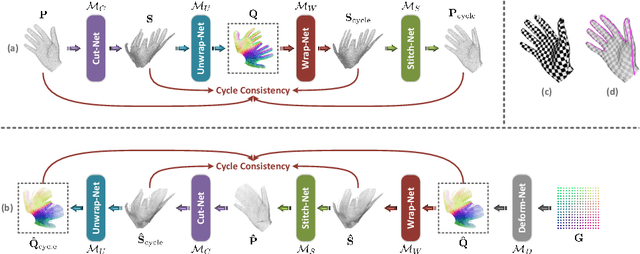
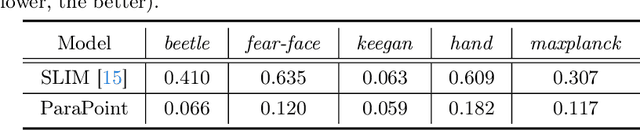
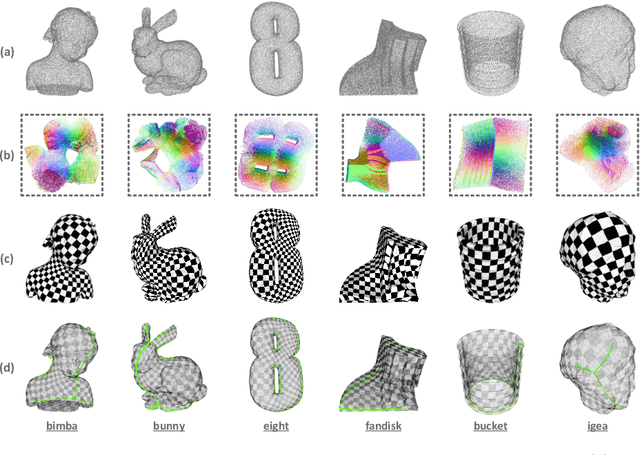
Surface parameterization is a fundamental geometry processing problem with rich downstream applications. Traditional approaches are designed to operate on well-behaved mesh models with high-quality triangulations that are laboriously produced by specialized 3D modelers, and thus unable to meet the processing demand for the current explosion of ordinary 3D data. In this paper, we seek to perform UV unwrapping on unstructured 3D point clouds. Technically, we propose ParaPoint, an unsupervised neural learning pipeline for achieving global free-boundary surface parameterization by building point-wise mappings between given 3D points and 2D UV coordinates with adaptively deformed boundaries. We ingeniously construct several geometrically meaningful sub-networks with specific functionalities, and assemble them into a bi-directional cycle mapping framework. We also design effective loss functions and auxiliary differential geometric constraints for the optimization of the neural mapping process. To the best of our knowledge, this work makes the first attempt to investigate neural point cloud parameterization that pursues both global mappings and free boundaries. Experiments demonstrate the effectiveness and inspiring potential of our proposed learning paradigm. The code will be publicly available.
Dynamic 3D Point Cloud Sequences as 2D Videos
Mar 02, 2024
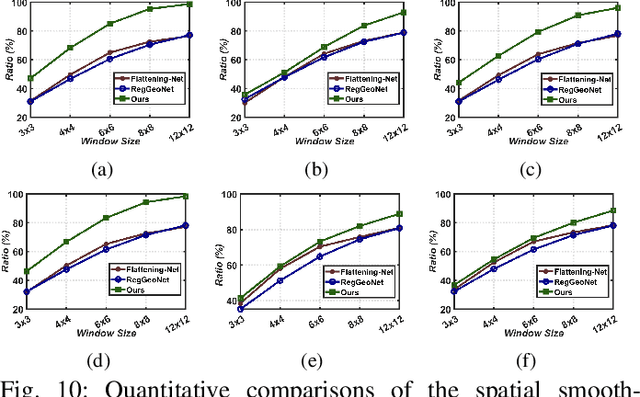
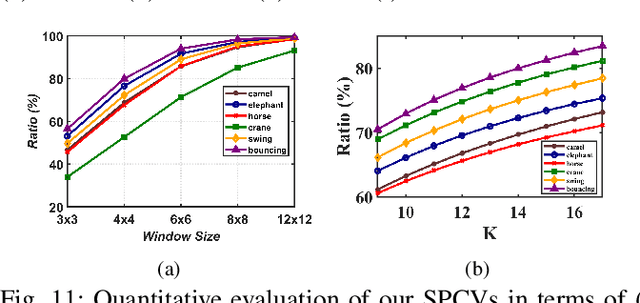

Dynamic 3D point cloud sequences serve as one of the most common and practical representation modalities of dynamic real-world environments. However, their unstructured nature in both spatial and temporal domains poses significant challenges to effective and efficient processing. Existing deep point cloud sequence modeling approaches imitate the mature 2D video learning mechanisms by developing complex spatio-temporal point neighbor grouping and feature aggregation schemes, often resulting in methods lacking effectiveness, efficiency, and expressive power. In this paper, we propose a novel generic representation called \textit{Structured Point Cloud Videos} (SPCVs). Intuitively, by leveraging the fact that 3D geometric shapes are essentially 2D manifolds, SPCV re-organizes a point cloud sequence as a 2D video with spatial smoothness and temporal consistency, where the pixel values correspond to the 3D coordinates of points. The structured nature of our SPCV representation allows for the seamless adaptation of well-established 2D image/video techniques, enabling efficient and effective processing and analysis of 3D point cloud sequences. To achieve such re-organization, we design a self-supervised learning pipeline that is geometrically regularized and driven by self-reconstructive and deformation field learning objectives. Additionally, we construct SPCV-based frameworks for both low-level and high-level 3D point cloud sequence processing and analysis tasks, including action recognition, temporal interpolation, and compression. Extensive experiments demonstrate the versatility and superiority of the proposed SPCV, which has the potential to offer new possibilities for deep learning on unstructured 3D point cloud sequences. Code will be released at https://github.com/ZENGYIMING-EAMON/SPCV.
Human as Points: Explicit Point-based 3D Human Reconstruction from Single-view RGB Images
Nov 06, 2023


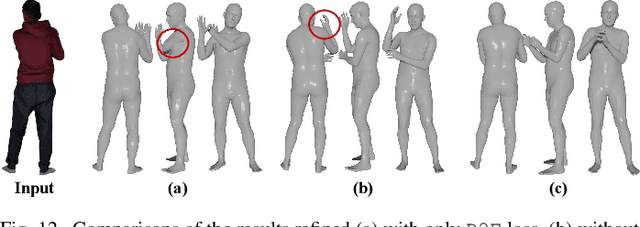
The latest trends in the research field of single-view human reconstruction devote to learning deep implicit functions constrained by explicit body shape priors. Despite the remarkable performance improvements compared with traditional processing pipelines, existing learning approaches still show different aspects of limitations in terms of flexibility, generalizability, robustness, and/or representation capability. To comprehensively address the above issues, in this paper, we investigate an explicit point-based human reconstruction framework called HaP, which adopts point clouds as the intermediate representation of the target geometric structure. Technically, our approach is featured by fully-explicit point cloud estimation, manipulation, generation, and refinement in the 3D geometric space, instead of an implicit learning process that can be ambiguous and less controllable. The overall workflow is carefully organized with dedicated designs of the corresponding specialized learning components as well as processing procedures. Extensive experiments demonstrate that our framework achieves quantitative performance improvements of 20% to 40% over current state-of-the-art methods, and better qualitative results. Our promising results may indicate a paradigm rollback to the fully-explicit and geometry-centric algorithm design, which enables to exploit various powerful point cloud modeling architectures and processing techniques. We will make our code and data publicly available at https://github.com/yztang4/HaP.
NeuroGF: A Neural Representation for Fast Geodesic Distance and Path Queries
Jun 01, 2023Geodesics are essential in many geometry processing applications. However, traditional algorithms for computing geodesic distances and paths on 3D mesh models are often inefficient and slow. This makes them impractical for scenarios that require extensive querying of arbitrary point-to-point geodesics. Although neural implicit representations have emerged as a popular way of representing 3D shape geometries, there is still no research on representing geodesics with deep implicit functions. To bridge this gap, this paper presents the first attempt to represent geodesics on 3D mesh models using neural implicit functions. Specifically, we introduce neural geodesic fields (NeuroGFs), which are learned to represent the all-pairs geodesics of a given mesh. By using NeuroGFs, we can efficiently and accurately answer queries of arbitrary point-to-point geodesic distances and paths, overcoming the limitations of traditional algorithms. Evaluations on common 3D models show that NeuroGFs exhibit exceptional performance in solving the single-source all-destination (SSAD) and point-to-point geodesics, and achieve high accuracy consistently. Moreover, NeuroGFs offer the unique advantage of encoding both 3D geometry and geodesics in a unified representation. Code is made available at https://github.com/keeganhk/NeuroGF/tree/master.
Bidirectional Propagation for Cross-Modal 3D Object Detection
Jan 22, 2023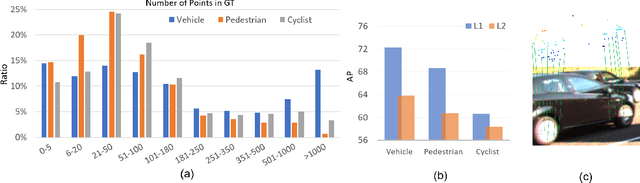
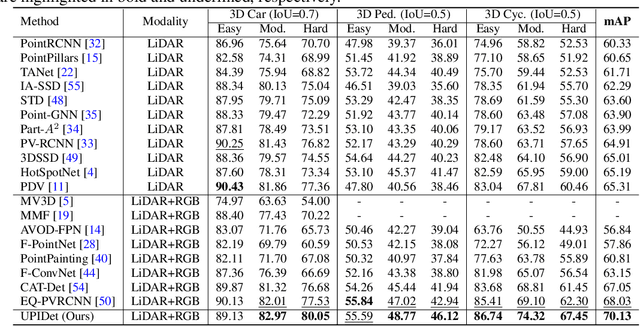

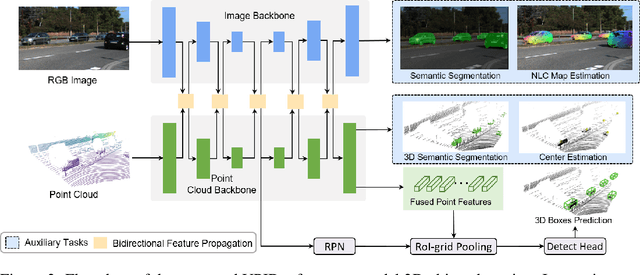
Recent works have revealed the superiority of feature-level fusion for cross-modal 3D object detection, where fine-grained feature propagation from 2D image pixels to 3D LiDAR points has been widely adopted for performance improvement. Still, the potential of heterogeneous feature propagation between 2D and 3D domains has not been fully explored. In this paper, in contrast to existing pixel-to-point feature propagation, we investigate an opposite point-to-pixel direction, allowing point-wise features to flow inversely into the 2D image branch. Thus, when jointly optimizing the 2D and 3D streams, the gradients back-propagated from the 2D image branch can boost the representation ability of the 3D backbone network working on LiDAR point clouds. Then, combining pixel-to-point and point-to-pixel information flow mechanisms, we construct an bidirectional feature propagation framework, dubbed BiProDet. In addition to the architectural design, we also propose normalized local coordinates map estimation, a new 2D auxiliary task for the training of the 2D image branch, which facilitates learning local spatial-aware features from the image modality and implicitly enhances the overall 3D detection performance. Extensive experiments and ablation studies validate the effectiveness of our method. Notably, we rank $\mathbf{1^{\mathrm{st}}}$ on the highly competitive KITTI benchmark on the cyclist class by the time of submission. The source code is available at https://github.com/Eaphan/BiProDet.