 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Geometry-Appearance Human Reconstruction in a Unified Latent Space via Bridge Diffusion
Jan 01, 2026Achieving consistent and high-fidelity geometry and appearance reconstruction of 3D digital humans from a single RGB image is inherently a challenging task. Existing studies typically resort to decoupled pipelines for geometry estimation and appearance synthesis, often hindering unified reconstruction and causing inconsistencies. This paper introduces \textbf{JGA-LBD}, a novel framework that unifies the modeling of geometry and appearance into a joint latent representation and formulates the generation process as bridge diffusion. Observing that directly integrating heterogeneous input conditions (e.g., depth maps, SMPL models) leads to substantial training difficulties, we unify all conditions into the 3D Gaussian representations, which can be further compressed into a unified latent space through a shared sparse variational autoencoder (VAE). Subsequently, the specialized form of bridge diffusion enables to start with a partial observation of the target latent code and solely focuses on inferring the missing components. Finally, a dedicated decoding module extracts the complete 3D human geometric structure and renders novel views from the inferred latent representation. Experiments demonstrate that JGA-LBD outperforms current state-of-the-art approaches in terms of both geometry fidelity and appearance quality, including challenging in-the-wild scenarios. Our code will be made publicly available at https://github.com/haiantyz/JGA-LBD.
HuGDiffusion: Generalizable Single-Image Human Rendering via 3D Gaussian Diffusion
Jan 25, 2025

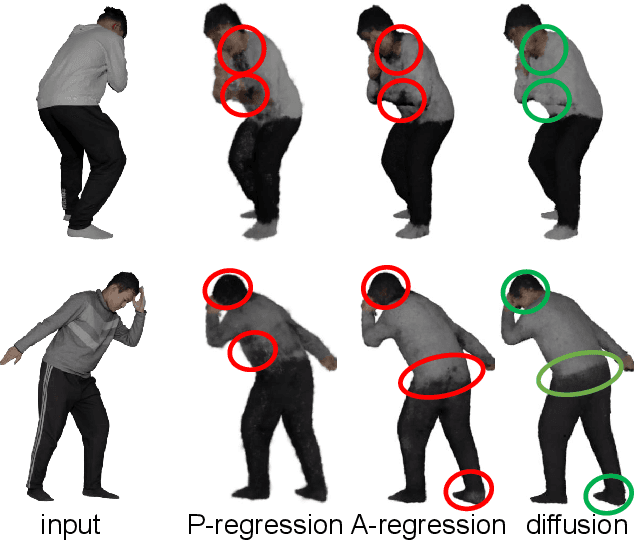

We present HuGDiffusion, a generalizable 3D Gaussian splatting (3DGS) learning pipeline to achieve novel view synthesis (NVS) of human characters from single-view input images. Existing approaches typically require monocular videos or calibrated multi-view images as inputs, whose applicability could be weakened in real-world scenarios with arbitrary and/or unknown camera poses. In this paper, we aim to generate the set of 3DGS attributes via a diffusion-based framework conditioned on human priors extracted from a single image. Specifically, we begin with carefully integrated human-centric feature extraction procedures to deduce informative conditioning signals. Based on our empirical observations that jointly learning the whole 3DGS attributes is challenging to optimize, we design a multi-stage generation strategy to obtain different types of 3DGS attributes. To facilitate the training process, we investigate constructing proxy ground-truth 3D Gaussian attributes as high-quality attribute-level supervision signals. Through extensive experiments, our HuGDiffusion shows significant performance improvements over the state-of-the-art methods. Our code will be made publicly available.
Human as Points: Explicit Point-based 3D Human Reconstruction from Single-view RGB Images
Nov 06, 2023


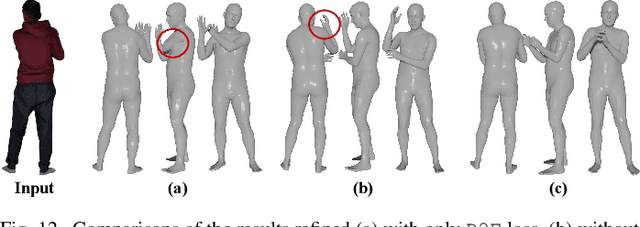
The latest trends in the research field of single-view human reconstruction devote to learning deep implicit functions constrained by explicit body shape priors. Despite the remarkable performance improvements compared with traditional processing pipelines, existing learning approaches still show different aspects of limitations in terms of flexibility, generalizability, robustness, and/or representation capability. To comprehensively address the above issues, in this paper, we investigate an explicit point-based human reconstruction framework called HaP, which adopts point clouds as the intermediate representation of the target geometric structure. Technically, our approach is featured by fully-explicit point cloud estimation, manipulation, generation, and refinement in the 3D geometric space, instead of an implicit learning process that can be ambiguous and less controllable. The overall workflow is carefully organized with dedicated designs of the corresponding specialized learning components as well as processing procedures. Extensive experiments demonstrate that our framework achieves quantitative performance improvements of 20% to 40% over current state-of-the-art methods, and better qualitative results. Our promising results may indicate a paradigm rollback to the fully-explicit and geometry-centric algorithm design, which enables to exploit various powerful point cloud modeling architectures and processing techniques. We will make our code and data publicly available at https://github.com/yztang4/HaP.
WarpingGAN: Warping Multiple Uniform Priors for Adversarial 3D Point Cloud Generation
Mar 24, 2022We propose WarpingGAN, an effective and efficient 3D point cloud generation network. Unlike existing methods that generate point clouds by directly learning the mapping functions between latent codes and 3D shapes, Warping-GAN learns a unified local-warping function to warp multiple identical pre-defined priors (i.e., sets of points uniformly distributed on regular 3D grids) into 3D shapes driven by local structure-aware semantics. In addition, we also ingeniously utilize the principle of the discriminator and tailor a stitching loss to eliminate the gaps between different partitions of a generated shape corresponding to different priors for boosting quality. Owing to the novel generating mechanism, WarpingGAN, a single lightweight network after one-time training, is capable of efficiently generating uniformly distributed 3D point clouds with various resolutions. Extensive experimental results demonstrate the superiority of our WarpingGAN over state-of-the-art methods in terms of quantitative metrics, visual quality, and efficiency. The source code is publicly available at https://github.com/yztang4/WarpingGAN.git.